
Главное
• Синхронный перевод в видеоконференциях сегодня — это сквозной пайплайн из четырёх стадий: ASR (распознавание речи), MT (машинный перевод), TTS (синтез речи) и опционально клонирование голоса. Целевая сквозная задержка — менее 800 мс для субтитров и 2–3 с для переведённого голоса.
• Победители стека 2026 — Deepgram Nova-3 + DeepL + ElevenLabs Multilingual. Deepgram даёт WER ~5–7% при потоковой задержке ~450 мс, DeepL лидирует по качеству перевода европейских языков по метрике COMET, ElevenLabs Flash укладывается в 75 мс TTS-задержки. Каскадный пайплайн по-прежнему обыгрывает сквозные модели speech-to-speech в продакшене.
• Реальная стоимость минуты — около 3–4,5 ₽. Примерно 0,69 ₽/мин ASR + 0,18 ₽ за 100 знаков MT + 2,25 ₽/мин TTS = 187–262 ₽/час переведённого аудио. Добавьте 20–30% на повторные попытки, простой потока и определение языка.
• Выбор WebRTC-архитектуры меняет всё. SFU + серверный воркер перевода — это продакшен-паттерн. P2P ломается при >3 участниках; MCU добавляет задержку транскодинга. Подробно мы разобрали это в материале «Архитектура видеочата: P2P vs MCU vs SFU».
• Точка окупаемости «делать своё vs покупать» — около 2 000 платных звонков в месяц. Ниже — выгоднее коробочные KUDO, Interprefy, Wordly или Zoom AI Companion. Выше, а также для телемедицины, судов, вещания и киберспорта, где важны локация данных и доменные глоссарии, обычно выигрывает кастомный WebRTC + перевод.
По теме: наш подробный гид — 7 лучших инструментов перевода видеозвонков (сравнение, 2026).
Почему этот гид по синхронному переводу написала Фора Софт
Мы разрабатываем видео- и ИИ-продукты 19 лет и выпустили в работу более 450 видео- и конференц-систем. Среди них — Translinguist, кастомная платформа синхронного перевода живых событий на базе ИИ. Она объединяет потоковый ASR, real-time MT, многоязычный TTS и переключение на человека-переводчика для событий, где стандартных переведённых субтитров Zoom недостаточно.
Этот гид мы написали как тот самый материал, которого не хватало продуктовым командам на старте. Мы честно сравниваем стек ASR / MT / TTS 2026 года по WER, BLEU/COMET, задержке и цене. Разбираем WebRTC-архитектуру, по которой переведённый звук возвращается обратно в звонок. Даём стоимостную модель в масштабе, ловушки соответствия для HIPAA / GDPR / FERPA и границу «строить или купить». В конце — фреймворк из пяти вопросов, чтобы выбрать правильный путь.
Если у вас платформа вебинаров, инструмент телемедицины, e-learning-сервис, стек записи судебных заседаний или киберспортивная трансляция, остальная часть статьи — для вас.
Добавляете синхронный перевод в свой видеопродукт?
30 минут разговора — и у вас будет независимая от вендоров архитектура, актуальный стек 2026 года и бюджет под переведённые субтитры или полноценный голосовой перевод.
Что такое синхронный перевод в видеоконференциях на самом деле
Синхронный перевод — это перевод речи одного говорящего на другой язык в реальном времени: в виде субтитров, переведённого голоса или и того, и другого. Задержка достаточно мала, чтобы слушатели следили за разговором по мере того, как он идёт. Раньше для этого нужны были человек-переводчик и звукоизолированная кабина. В 2026 году это программный пайплайн, который вы встраиваете прямо в свой продукт для видеоконференций.
Сосуществуют два режима. Переведённые субтитры показывают слушателю письменные титры на его языке; цель по задержке — менее 800 мс, точность определяется в основном связкой ASR + MT. Переведённый голос воспроизводит фразы говорящего как звук на языке слушателя, опционально — клонированным голосом; цель по сквозной задержке — 2–3 с, и в цепочке добавляются риски качества TTS и клонирования. В большинстве продакшен-внедрений запускают оба режима и дают слушателю выбор.

Рисунок 1. Пайплайн синхронного перевода — от микрофона до переведённых субтитров и дублированного голоса.
Пайплайн из четырёх стадий — ASR → MT → TTS → клонирование голоса
Пайплайн синхронного перевода — это цепочка. Каждая стадия добавляет задержку и риск ошибок; оптимизируете вы цепочку, а не отдельные компоненты.
1. ASR (распознавание речи). Поточно превращает звук говорящего в частичные расшифровки. Современные движки (Deepgram Nova-3, AssemblyAI Universal-2, Whisper-large-v3 с потоковыми обёртками) дают задержку 100–500 мс на потоковых эндпойнтах. Word error rate (WER) — основная метрика точности; 5–7% на разговорном английском — рубеж 2026 года.
2. MT (машинный перевод). Переводит расшифровку на целевой язык. Каскадный MT (DeepL, Google Cloud Translation, Azure Translator, NLLB-200) обычно добавляет 100–200 мс на предложение. Сквозные модели speech-to-speech (Meta Seamless Streaming, Google Translatotron) обходят ASR + MT, но в масштабе работают пока на ограниченном наборе языков и добавляют 1,5–2 с задержки на горизонте 2026.
3. TTS (синтез речи). Озвучивает переведённый текст. ElevenLabs Multilingual (Flash v2.5 — 75 мс до первого токена), OpenAI Voice Engine, Microsoft Azure Neural TTS, PlayHT и Resemble AI покрывают весь продакшен-диапазон качества. Компромисс — естественность vs задержка: выразительные голоса добавляют 200–400 мс.
4. Клонирование голоса (опционально). Воспроизводит TTS голосом исходного говорящего. ElevenLabs Multilingual v3, Microsoft VALL-E 2 / Azure Personal Voice и OpenAI Voice Engine — все это умеют. Это множитель качества, благодаря которому переведённая встреча ощущается так, будто говорящий действительно выучил ваш язык. Ловушки соответствия реальны: и HIPAA, и GDPR относят голосовую биометрию к чувствительным данным.
Выбирайте каскад ASR → MT → TTS, когда: нужны 100–120 языковых пар, отладка по каждой стадии, кастомные доменные глоссарии и возможность заменить один компонент без пересборки всего пайплайна. Сквозные speech-to-speech — это интересное исследование, а не продакшен-стандарт 2026 года.
ASR-движки 2026 — что катить в продакшен
Цифры ниже — это данные вендоров и независимые бенчмарки за 2025–2026. Перепроверяйте на своём аудио перед выбором: разговорные акценты, переключение языка и фоновый шум меняют расстановку сил.
| ASR-движок | WER (разг.) | Потоковая задержка | Языки | Цена/мин | Сценарий |
|---|---|---|---|---|---|
| Deepgram Nova-3 | 5,3–6,8% | ~450 мс | 40+ | 0,69 ₽ | Универсальный real-time |
| OpenAI Whisper v3 | ~7,4% | батч по 30 с | 99+ | 0,45 ₽ | Широкая поддержка языков |
| AssemblyAI Universal-2 | ~14% разг. / 2% чистый | ~600 мс | сильный английский | 0,18 ₽ | Экономный, цифры/буквы |
| Google Cloud STT | 7–10% | ~500 мс | 125+ | 1,2 ₽ / 0,3 ₽ при объёме | Инфраструктура GCP |
| Azure Speech | 7–9% | ~500 мс | 100+ | 0,9 ₽ | Инфраструктура Microsoft, HIPAA |
| NVIDIA Riva (on-prem) | 8–10% | ~300 мс | 12 базовых + кастом | капекс на GPU | Изолированные, регулируемые контуры |
Подробнее об ASR-ландшафте мы собрали отдельный обзор платформ распознавания речи, который выходит за рамки задач перевода.
MT-движки 2026 — что переводит хорошо и быстро
DeepL. Лидер по качеству на европейских языках по COMET и оценкам людей; 30+ языковых пар. Потоковый перевод по предложениям, ~150–200 мс. ~0,18 ₽ за 100 знаков. Стандарт по умолчанию для бизнес-встреч в EMEA.
Google Cloud Translation v3. 135 языков. Кастомные AutoML-модели. ~1 125–1 875 ₽ за миллион знаков. Выигрывает по охвату языков и доменной донастройке через AutoML.
Azure Translator. 70+ языков, глубокая интеграция с Microsoft Teams, аттестация HIPAA/GDPR. Естественный выбор, если вы встраиваете перевод внутрь Teams-нативного или медицинского сценария.
Meta NLLB-200 + Seamless M4T. 200+ языковых пар в NLLB-200, мультимодальный текст+речь в Seamless M4T. Open-source, разворачивается on-prem. По BLEU отстаёт от DeepL на 5–10 пунктов на европейских парах, но выигрывает на низкоресурсных языках и на нагрузках, которые не могут покидать приватное облако.
GPT-4o / Claude / Gemini для перевода. Тёмная лошадка 2024–2026. LLM переводят свободно и красиво справляются с переключением языков, но стоят дороже (~750–2 250 ₽ за миллион знаков), несут риск галлюцинаций на именах и числах и добавляют 300–800 мс задержки на вызов API. Подходят для одноразового перевода критичных текстов, хуже — для горячих потоковых сценариев.
TTS и клонирование голоса — решающая стадия для переведённого голоса
Слушатели простят чуть угловатый перевод в субтитрах, но не простят переведённый голос, который звучит роботизированно, обрывается на середине фразы или оторван от говорящего. Выбирайте TTS так, будто выбираете голос своего продукта.
ElevenLabs Multilingual v3 + Flash v2.5. Задержка до первого токена ~75 мс, выразительные голоса, 30+ языков, клонирование голоса по 3–5 минутам исходного аудио. Продакшен-стандарт 2026 для большинства видеопродуктов.
Microsoft Azure Neural TTS & Personal Voice. Шире покрытие языков, готовая поза по HIPAA/GDPR, клонирование голоса — за гейтом ответственного ИИ с явным согласием. Чуть выше задержка (~200 мс до первого токена), но дружелюбнее к энтерпрайзу.
OpenAI Voice Engine, PlayHT, Resemble AI, Coqui. Voice Engine на момент написания доступен только по приглашению; PlayHT и Resemble — серьёзные коммерческие альтернативы; Coqui — open-source-вариант для самостоятельного хостинга, когда облачный TTS вам недоступен совсем.
Подробнее о том, как клонирование голоса устроено под капотом и сколько оно стоит в продакшене, — в нашем гиде по клонированию и синтезу голоса.
WebRTC-архитектура для синхронного переведённого аудио — продакшен-паттерн
Пайплайн перевода бесполезен, если WebRTC-слой не сможет вернуть результат обратно в звонок без джиттера. Продакшен-паттерн 2026 года выглядит так:
1. SFU, а не MCU. SFU (Selective Forwarding Unit) раздаёт каждому клиенту веер исходного медиа и опционально — дополнительные дорожки переведённого аудио. MCU добавляет задержку транскодинга и нагрузку на CPU, которые синхронный перевод просто не может себе позволить.
2. Серверный воркер перевода. SFU ответвляет копию аудио активного говорящего на воркер перевода, где крутятся ASR, MT и TTS. Субтитры возвращаются по WebRTC data channel; переведённый голос — как дополнительная аудиодорожка, на которую клиент-слушатель может переключиться вместо оригинала.
3. VAD + разметка говорящих. Voice-activity detection нарезает речь на переводимые сегменты, не ломая предложения. Метки говорящих (диаризация) удерживают нужный голос привязанным к нужному клонированному TTS-профилю, когда говорящие сменяются в середине звонка.
4. Бюджет задержки и джиттер-буфер. Цель — менее 800 мс суммарно для субтитров и 1,5–2,5 с для переведённого голоса. Джиттер-буфер должен настраиваться индивидуально: слушатели с нарушениями слуха, которым нужны только субтитры, могут жить с более тугим буфером; слушателям в голосовом режиме нужен буфер чуть больше, чтобы поглощать вариативность TTS.
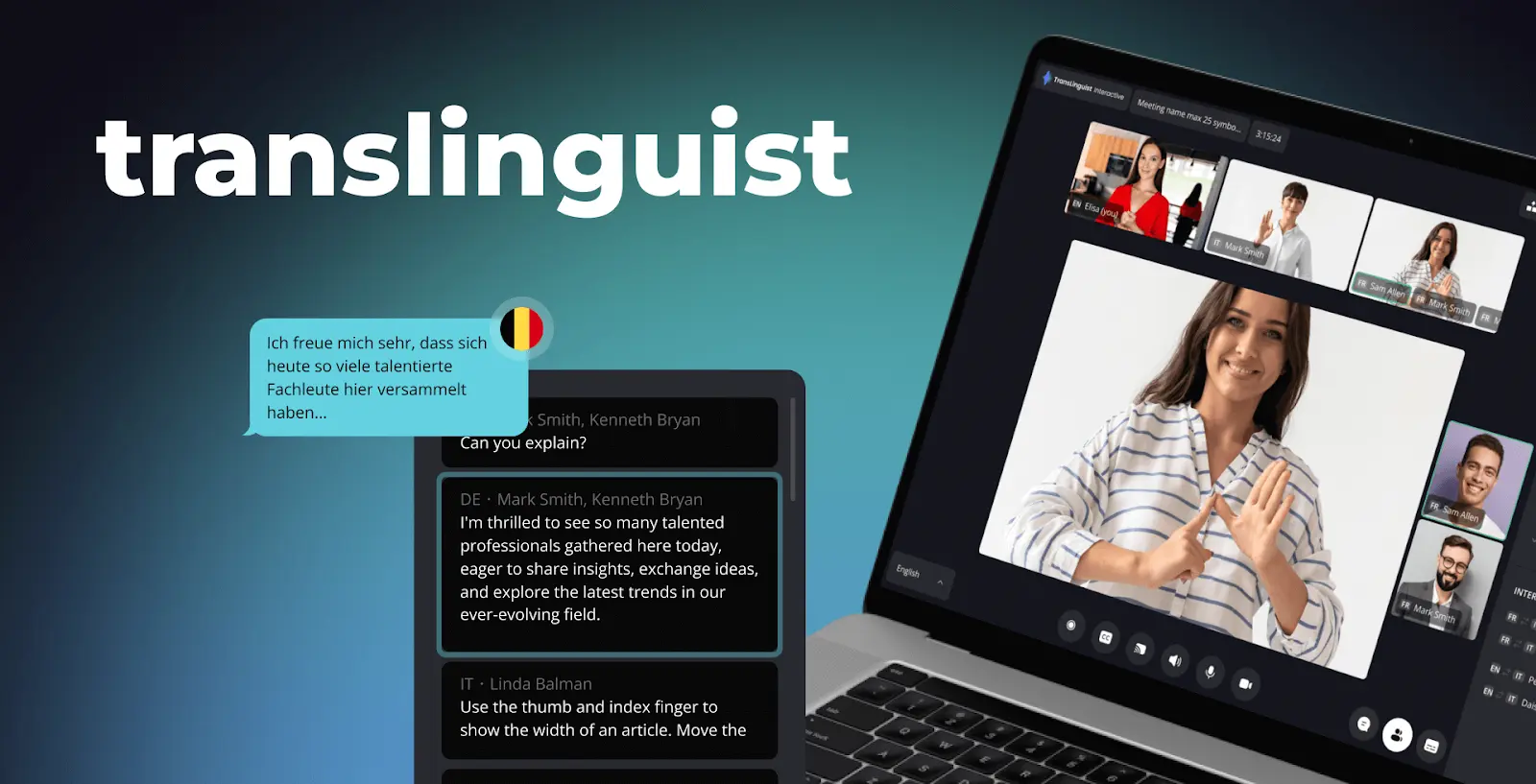
Рисунок 2. SFU + серверный воркер перевода — продакшен-архитектура 2026 года.
Коробочные платформы — что на самом деле дают Zoom, Teams, KUDO, Interprefy и Wordly
Zoom AI Companion — переведённые субтитры. Сегодня — переведённые субтитры на 35+ языков в платных тарифах. Голосовой перевод в 2026 году в приватном превью. Хорошо для общих бизнес-встреч; слаб на доменных глоссариях.
Microsoft Teams — real-time переведённые субтитры и речь. Переведённые субтитры на 70+ языков; функция синхронного перевода для мероприятий. Лучший вариант, если вы уже внутри инфраструктуры Microsoft 365.
Google Meet — синхронный перевод. Переведённые субтитры на основных языках; голосовой режим раскатывается постепенно. Самый «потребительский» вариант по умолчанию; тоньше по корпоративным настройкам.
KUDO AI и Interprefy AI. Специализированные платформы перевода для мероприятий с гибридом ИИ + человек-переводчик. Цена за мероприятие; рассчитаны на конференции, государственные встречи, регулируемые вебинары. Сильны на языках, слабы как SDK для разработчика.
Wordly, Verbit, Maestra, Akkadu, Translanguage. Среднеценовая синхронная интерпретация как сервис; от 30 000 ₽ до 150 000 ₽ за мероприятие в зависимости от языков и длительности. Полезны на уровне события, но редко встраиваются в сторонний продукт.
Коробка не закрывает ваш домен?
Мы построили Translinguist для клиентов, чьи задачи перевода Zoom не покрывал. Сделаем то же самое для вас за 12–16 недель.
Стоимостная модель — что синхронный перевод реально стоит в масштабе
Грубый расчёт на минуту переведённого аудио по ценам 2026 года:
- ASR: Deepgram Nova-3 потоково — 0,69 ₽/мин
- MT: DeepL — ~0,18 ₽ за 100 знаков; ~150 слов/мин ≈ 1,35 ₽/мин
- TTS: ElevenLabs Flash — ~2,25 ₽ за минуту сгенерированного аудио
- Итого: ~4,27 ₽/мин ≈ 256 ₽/час аудио на одну языковую пару
- Добавьте 20–30% на повторные попытки VAD, простой потока, определение языка и потерянные кадры — реальная цена выходит 5,2–5,6 ₽/мин
Только переведённые субтитры (без TTS) укладываются в ~2–2,6 ₽/мин. Голос + клонирование — та же каскадная цена выше плюс стоимость энроллмента (75–375 ₽ за клонированный голос). Умножайте на число языков у слушателей: встреча с 4 активными языками перевода стоит в 4 раза больше за минуту.
Выбирайте white-label-коробку, когда: у вас менее 2 000 переведённых звонков в месяц, менее 4 языковых пар, а слушатели мирятся с универсальными TTS-голосами. Ниже этого масштаба экономия за звонок при сборке своего пайплайна не отбивает инженерные вложения.
Соответствие и локация данных — HIPAA, GDPR, FERPA, AI Act
Синхронный перевод гоняет «сырой» голос и переведённый текст через сторонние API. Уже это нарушает несколько типовых режимов соответствия, если архитектуру не продумать заранее.
HIPAA (здравоохранение США). Голос пациента — это PHI. Большинство потребительских ASR/MT/TTS API не подходят под HIPAA без подписанного BAA. Список тех, кто подписывает BAA в 2026: Microsoft Azure (Speech, Translator, Neural TTS), Google Cloud (STT, Translation), AWS (Transcribe, Translate, Polly), Deepgram (на enterprise-тарифе). Самостоятельный хостинг open-source-моделей в HIPAA-совместимом облаке — более консервативный паттерн для телемедицины.
GDPR (ЕС). Переведённый голос и биометрия клонирования — это данные особой категории. Безопасный дефолт — обработка внутри ЕС; обязательства EU Data Boundary от Microsoft и Google помогают, но читайте мелкий шрифт. Продакшен-паттерн — автоматическое удаление аудио после звонка и хранение только переведённой расшифровки.
FERPA (образование США). Голос ученика подпадает под FERPA, если хранится в идентифицируемом виде. Большинство коробочных платформ перевода не документируют свою FERPA-позу; более безопасный путь для K-12 и американских вузов — собственное решение с автоудалением и on-prem ASR.
EU AI Act. Клонирование голоса теперь — явное обязательство по прозрачности: слушателей должны информировать, что переведённый голос сгенерирован ИИ. Зашивайте это в UI слушателя, а не в мелкий шрифт юридической оговорки.
Мини-кейс — Translinguist, платформа синхронного перевода живых событий, которую мы построили
Ситуация. Клиенту из event-индустрии (организация мероприятий) был нужен синхронный перевод для международных конференций с 6–10 одновременными языками, гибридный сценарий «ИИ + человек-переводчик» как страховка, доменные глоссарии под каждое мероприятие и архив с расшифровкой и дублированным аудио, который годен для регулируемых отраслей. Коробочные платформы покрывали менее 60% воркфлоу.
Что мы построили. Translinguist — пайплайн «WebRTC SFU + серверный воркер перевода», объединяющий потоковый ASR, нейронный MT с глоссариями под событие, многоязычный TTS, клонирование голоса для брендированных голосов спикеров и моментальный переход на человека-переводчика, когда уверенность ИИ падает ниже порога. Субтитры идут по WebRTC data channel; переведённый голос — второй аудиодорожкой, которую каждый слушатель может включить вместо оригинала.
Результат. Задержка переведённого голоса менее 2 с, задержка субтитров менее 800 мс, уверенность ИИ 92% на отрепетированном контенте с плавной передачей человеку-переводчику при необходимости. Платформа сегодня обслуживает многоязычные мероприятия клиентов из финансов, образования, госсектора и корпоративных коммуникаций.
Делать своё vs покупать — когда кастомный перевод окупается
Покупайте коробку, когда: менее 2 000 переведённых звонков в месяц, менее 4 языковых пар, общий контент без доменного глоссария, слушатели мирятся с универсальными голосами, а ваша история с локацией данных уживается с американским или европейским облачным вендором.
Стройте свой WebRTC + перевод, когда: вы делаете более 2 000 звонков в месяц, нужны доменные глоссарии (юридический, медицинский, финансовый, технический), локация данных — жёсткое требование (HIPAA, FERPA, on-prem в ЕС), UX слушателя должен ощущаться частью вашего продукта (свой стиль субтитров, свой UI переключения голоса) или ваша бизнес-модель — продавать перевод как функцию, а не покупать его как услугу.
Вертикали, где кастом — всегда: судебный перевод, дубляж голоса в телемедицине, киберспортивные прямые эфиры, перевод религиозных служб, синхронный перевод живых событий с регулируемыми спикерами, перевод в школьном классе под FERPA. За последние три года мы делали или скоупили каждый из этих сценариев.
Честная форма бюджета. Кастомный MVP «WebRTC + каскадный перевод» с нашей командой и ускорением через Agent Engineering обходится в 6,7–12 млн ₽ и 12–16 недель; сопоставимые коробочные интеграторы обычно называют от 18 млн ₽ и 6–9 месяцев. Если в скоупе клонирование голоса, низкоресурсные языки или полная поза по HIPAA/GDPR, мы сначала скоупим discovery, а не угадываем итоги.
Фреймворк решения — выберите стратегию перевода за пять вопросов
В1. Только субтитры или полноценный переведённый голос? Субтитры — это 60% ценности за 30% стоимости, и в большинстве юрисдикций они проходят ниже радара регулятора. Голос — это конференц-уровень опыта; закладывайте дополнительную задержку, цену и работу с соответствием.
В2. Сколько языковых пар в одном звонке? 1–3 пары → коробки достаточно. 4–10 пар одновременно → вы вышли за рамки любой потребительской платформы; планируйте кастомный SFU с параллельными воркерами перевода.
В3. Какой бюджет задержки у вашей аудитории? Телемедицина и разговоры 1:1 → жёстко (< 1,5 с для голоса). Конференц-трансляции → мягче (3–5 с для голоса приемлемо). Записанные вебинары → минуты не проблема.
В4. Какой у вас режим соответствия? HIPAA, FERPA, GDPR, MAS, OSFI, SOC 2, AI Act — каждый накладывает неприкосновенные ограничения на архитектуру. Выбирайте тех вендоров движков, которые подписывают нужные бумаги.
В5. Перевод — это продуктовая функция или скрытая инфраструктура? Если функция, которой вы маркетируете продукт, — почти всегда правильный ответ кастом. Если скрытая инфраструктура, которую никто не замечает, — коробка подойдёт.
Пять ловушек, которые мы видим почти в каждом запуске синхронного перевода
1. Оптимизация одной стадии вместо всей цепочки. Команды гонятся за точностью Whisper, а потом подключают медленный MT и TTS с 400 мс — итоговая задержка 4 с, и слушатели уходят. Решение: бюджетируйте весь пайплайн заранее и бенчмаркайте сквозную задержку, а не по стадиям.
2. Игнорирование доменной лексики. Универсальный ASR не распознаёт «тахикардия», «противодействие отмыванию денег», «суверенный иммунитет» или игровые термины. WER подскакивает с 6% до 25% на реальном контенте. Решение: глоссарии под каждое мероприятие, кастомная лексика, дообученные акустические модели для вертикалей, где это нужно.
3. Галлюцинации в именах и числах. LLM-MT с удовольствием выдумывает правдоподобные, но неверные переводы имён собственных, дат, дозировок и денежных сумм. Решение: заранее извлекайте сущности и прокидывайте их через перевод нетронутыми; числовые значения дополнительно парсите отдельным проходом.
4. Клонирование голоса без UX согласия. EU AI Act и ряд законов штатов США уже требуют явного уведомления, когда слушатели слышат голос, сгенерированный ИИ. Решение: видимая плашка «AI-голос», переключатель отказа, дисклеймер о записи, подписанный энроллмент для каждого клонированного спикера.
5. Забыли про доступность на языке оригинала. Перевод — для слушателей с другим языком; живые субтитры на исходном языке — для слушателей с нарушениями слуха. Это разные функции, но один движок. Решение: запускайте обе с первого дня.
KPI — как измерить, что синхронный перевод действительно работает
KPI качества. WER на разговорном аудио (цель ≤ 8% для английского, ≤ 12% для других массовых языков); BLEU/COMET против эталонных переводов на отрепетированном контенте (цель ≥ 35 BLEU на европейских парах); MOS-оценка естественности TTS (цель ≥ 4,0/5); самоотчёт слушателей о понятности по 5-балльной шкале (цель ≥ 4).
KPI задержки. Задержка субтитров p50 / p95 (< 800 мс / < 1,5 с); задержка переведённого голоса p50 / p95 (< 2 с / < 3,5 с); доля секунд с подопустошением джиттер-буфера (< 1%); задержка завершения предложения (компромисс «wait-k», цель k = 3 слова).
KPI надёжности. Доступность воркера перевода (≥ 99,9%); доступность по языковым парам (каждая поддерживаемая пара ≥ 99% от недели к неделе); частота передачи человеку-переводчику при падении уверенности ИИ (≤ 5% на отрепетированном контенте); успешная компенсация потери аудиопакетов (≥ 98%).
Когда НЕ добавлять синхронный перевод
Не добавляйте переведённый голос для клинических разговоров, где ошибка перевода может навредить. Ответственный дефолт для таких звонков — субтитры плюс задокументированный SLA с человеком-переводчиком.
Не добавляйте перевод на 12 языков только потому, что кто-то попросил об этом на встрече с отделом продаж. Каждый язык — это вычислительная нагрузка, поддержка и разброс качества: сначала запустите 2–3 сильных языка, потом расширяйтесь.
Не стройте свой стек перевода, чтобы сэкономить 150 000 ₽ в год на лицензиях. Ниже ~2 000 переведённых звонков в месяц инженерные часы не окупаются — коробка тут правильнее.
Выбирайте гибрид «ИИ + человек-переводчик», когда: встреча регулируемая, записывается, транслируется или имеет договорные последствия. ИИ берёт основной объём, человек страхует моменты, где ошибаться нельзя.
Хотите пайплайн перевода, который ваш, а не сторонний виджет?
Мы соберём скоуп кастомного MVP «WebRTC + перевод» под ваш видеопродукт за 48 часов — задержка, языки, соответствие, цена.
Потоковые протоколы и сквозные модели speech-to-speech
В 2026 году сосуществуют два архитектурных русла. Каскадный пайплайн ASR → MT → TTS — продакшен-дефолт почти любого коммерческого внедрения. Сквозные модели speech-to-speech (S2S) — Meta Seamless Streaming, Google Translatotron 3, архитектура «голос-в-голос» i-LAVA — на момент написания остаются исследовательскими или с ограниченным набором языков.
Каскад выигрывает по отлаживаемости. Когда переведённая фраза «поехала», вы можете локализовать сбой до ASR, MT или TTS. Кастомные глоссарии, лексика под событие и тюнинг под конкретные языковые пары — всё это живёт на каскадном пайплайне. Стоимость минуты тут тоже понятнее и легче ложится в бюджет.
Сквозной S2S выигрывает по просодии. Там, где он уже работает, S2S сохраняет эмоции, акценты и стиль речи через языки так, как каскадному TTS пока не удаётся. Meta Seamless Streaming охватывает примерно 100 входных и 36 выходных языков для речи с задержкой ~2 с. Google Translatotron 3 — в исследовательском превью. Следите за пространством, но в продакшен катите каскад.
WebRTC-доставка. Переведённый голос приходит либо как вторая аудиодорожка в существующем peer connection (чище всего), либо по отдельному каналу (для более старых клиентов). Субтитры идут через WebRTC data channel с задержкой меньше кадра. SRT или HLS — варианты для трансляций «один ко многим», где прямой WebRTC не подходит.
Выбирайте сквозной speech-to-speech, когда: ваши языковые пары входят в покрытие Meta Seamless, сохранение просодии — маркетинговая фишка, вы готовы к ~2 с задержки, а ваш режим соответствия допускает путь данных модели. Во всех остальных случаях ответ всё ещё — каскад.
FAQ
Что такое синхронный перевод в видеоконференциях?
Это перевод голоса одного говорящего на другой язык в реальном времени — в виде субтитров, переведённого голоса или того и другого, с задержкой, которая позволяет участникам следить за разговором по ходу. Пайплайн — ASR + MT + TTS + опционально клонирование голоса, цель по задержке — < 800 мс для субтитров и 2–3 с для переведённого голоса.
Какой ASR-движок выбрать в 2026?
Deepgram Nova-3 выигрывает по потоковой задержке (~450 мс) и цене (0,69 ₽/мин). Whisper-large-v3 выигрывает по охвату языков (99+), но не нативно потоковый. AssemblyAI Universal-2 выигрывает по точности на цифрах/буквах и цене (0,18 ₽/мин), но силён в основном на английском. Azure Speech выигрывает по энтерпрайз- и HIPAA-позе. Выбирайте по основному языку, бюджету задержки и режиму соответствия.
DeepL vs Google vs Azure для синхронного машинного перевода?
DeepL лидирует по COMET-качеству на европейских языках и добавляет ~150–200 мс; Google Translation v3 лидирует по охвату языков (135) и AutoML; Azure Translator выигрывает внутри инфраструктуры Microsoft 365. NLLB-200 + Seamless M4T — open-source-вариант on-prem для регулируемых нагрузок.
Какая задержка приемлема для синхронного перевода?
Менее 800 мс ощущается как реальное время для субтитров; 1,5–2,5 с для переведённого голоса сохраняет естественный диалог; выше 4 с — диалог ломается. Целитесь в p95 субтитров < 1,5 с и p95 голоса < 3,5 с в продакшене.
Сколько стоит минута синхронного перевода?
Каскад ASR + MT + TTS по ценам 2026 — около 4,27 ₽/мин (256 ₽/час) на одну языковую пару. Добавьте 20–30% на повторные попытки VAD и простой потока. Только субтитры — ~2,25 ₽/мин. Умножайте на число одновременных языков у слушателей.
Когда стоит строить своё, а когда покупать?
Покупайте коробку ниже ~2 000 переведённых звонков в месяц при менее 4 языковых парах и общем контенте. Стройте кастом выше этого, а также когда нужны доменные глоссарии, локация данных (HIPAA / FERPA / on-prem в ЕС), нативный UX продукта или клонирование голоса на регулируемом контенте.
Готовы ли сквозные speech-to-speech к продакшену в 2026?
Для исследований и демо — да (Meta Seamless Streaming, Google Translatotron). Для 100+ языковых пар, кастомных глоссариев, отлаживаемости и соответствия — нет: каскад ASR + MT + TTS по-прежнему выигрывает продакшен в 2026.
Как сделать синхронный перевод HIPAA-совместимым?
Используйте ASR/MT/TTS-вендоров, подписывающих HIPAA BAA (Azure, GCP, AWS Transcribe/Translate/Polly, Deepgram Enterprise). Автоматически удаляйте «сырое» аудио после звонка; храните только переведённые расшифровки. Клонирование голоса — только с задокументированным согласием. Либо самостоятельно хостьте open-source-модели ASR/MT (Whisper, NLLB, Coqui) на своей HIPAA-совместимой инфраструктуре.
Что почитать дальше
Клонирование голоса
Клонирование и синтез голоса: подробный гид
Как современное клонирование голоса работает в продакшене — качество, цена, соответствие.
ASR-ландшафт
Лучшее ПО распознавания речи на базе ИИ
Подробный обзор ASR-движков, которые мы шорт-листим для синхронного перевода.
WebRTC
P2P vs MCU vs SFU
Архитектурный выбор, который решает, заработает ли задержка перевода.
Гид по интеграции
Видеозвонок с переводчиком: интеграция в WebRTC
Практический разбор того, как встроить перевод в WebRTC-стек.
Готовы запустить синхронный перевод в своём видеопродукте?
Синхронный перевод в видеоконференциях — уже не та недостижимая функция, какой он был три года назад. Стек 2026 года даёт субтитры быстрее секунды, переведённый голос менее чем за 3 с, клонирование голоса под спикера и стоимость минуты, которая нормально живёт внутри прайс-листа. Остались решения о том, какие ASR / MT / TTS совместить, под какой режим соответствия проектировать и завернуть ли всё это в свой SFU или арендовать сторонний виджет.
Если вы где-то на этом пути — от «нам нужны переведённые субтитры в следующем квартале» до «мы строим следующий Translinguist», — мы прошли его много раз. Принесите ТЗ, мы вернёмся с архитектурой, расчётом цены минуты и планом MVP на 12–16 недель.
Поговорите с командой, которая построила Translinguist
30 минут с архитектором решений Фора Софт — без вендорской предвзятости, честно про задержки и режимы соответствия.