Главное
• Шесть AI-паттернов стабильно доходят до продакшена в 2026 году. Голосовые ассистенты, распознавание и перевод речи в реальном времени, компьютерное зрение, генерация контента, рекомендации и модерация контента — всё остальное пока остаётся исследованием или красивыми слайдами.
• Покупайте модель, разрабатывайте функцию. GPT-5, Claude 4, Whisper и YOLOv8 сегодня — массовый товар. Ваше конкурентное преимущество — в рабочем процессе, данных, которыми вы их кормите, и UX, который показывает ответ, а не в обучении базовой модели.
• Большинство основателей переплачивают в 3–5 раз. Типичная первая AI-функция выходит за 1,1–3,7 млн ₽ на API-first архитектуре, а не за 15 млн ₽ и более, как оценивают агентства, которые всё ещё считают по меркам 2023 года. Мы запускаем за недели с помощью Agent Engineering.
• Стоимость токенов редко убивает функцию. Убивает плохой этап поиска, галлюцинации в юридическом или медицинском контексте, ложные срабатывания в модерации или задержка больше 1,5 с при голосовом взаимодействии. Сначала разберитесь с этим, а потом оптимизируйте расходы.
• Фора Софт довела до продакшена все шесть паттернов. FRP (голосовой ассистент для диджеев), BlaBlaPlay (модерация и рекомендации), FashionAI (компьютерное зрение), ALDA (генеративное обучение), Translinguist (перевод в реальном времени на 62 языка) — каждый с измеримым результатом, на который мы ссылаемся в этой статье.
Почему Фора Софт написала это руководство
Фора Софт создаёт видео-, аудио- и real-time-софт с 2005 года. За последние три года мы перестроили разработку вокруг Agent Engineering — спецификация в первую очередь, автоматическая генерация кода и непрерывные циклы оценки (evals), — чтобы выпускать production-функции с AI за недели, а не за кварталы. Для покупателя, который это читает, перемена важна: мы оцениваем быстрее и дешевле, чем агентства, которые до сих пор берут деньги за написанный вручную шаблонный код.
В этом руководстве собрано то, что мы поняли, внедряя AI в пять работающих продуктов — Franchise Record Pool, BlaBlaPlay, FashionAI, ALDA и Translinguist, — охватывающих шесть разных паттернов функций (голос, распознавание и перевод речи, зрение, генерация, рекомендации, модерация). Ниже мы разбираем каждый по имени: реальный стек, проблемы, с которыми столкнулись, и измеримые результаты. Загляните в наш сервис AI-интеграции или в кейс FRP, чтобы убедиться, прежде чем читать дальше.
Если вы основатель или CTO и решаете, чем для вас будет AI — функцией, разворотом или отвлечением, — вот короткая и прямая версия, которую мы даём своим потенциальным клиентам на установочном звонке.
AI — это правильная следующая функция для вашего продукта?
30 минут с нашим CTO — мы проверим ваш сценарий на прочность, назовём самый быстрый путь к рабочей версии v1 и честно скажем, если стоит подождать.
Шесть AI-паттернов, которые действительно доходят до продакшена
Почти каждая успешная AI-функция, которую мы выпустили, укладывается в один из шести паттернов. Если ваша идея не подходит ни под один из них, резко растёт вероятность, что вы занимаетесь исследованием, а не продуктом, — притормозите и сделайте прототип на готовом API, прежде чем тратить время из дорожной карты.
| Паттерн | Типичный сценарий | Технология первого выбора | Усилия на v1 | Где внедрила Фора Софт |
|---|---|---|---|---|
| Голосовой ассистент | «Собери плейлист в стиле латинопоп, 150 BPM» | Whisper + GPT-5 + Polly/ElevenLabs | 3–5 недель | FRP |
| Распознавание и перевод речи в реальном времени | Многоязычные видеозвонки и конференции | Deepgram + GPT-5 + ElevenLabs TTS | 6–10 недель | Translinguist (62 языка) |
| Компьютерное зрение | Распознавание объектов / одежды / лиц | YOLOv8 + CLIP + TFLite/CoreML на устройстве | 5–8 недель | FashionAI |
| Генерация контента | Учебные планы, плейлисты, образы, черновики | OpenAI Assistants + кастомная схема | 2–4 недели | ALDA |
| Рекомендации | Персонализированная лента, подсказки, плейлисты | Эмбеддинги + pgvector / Pinecone | 3–6 недель | BlaBlaPlay, FRP |
| Модерация контента | Язык вражды, PII, сигналы безопасности | Whisper + дообученный классификатор | 4–6 недель | BlaBlaPlay |
Обратите внимание, чего в списке нет: «обучить собственную базовую модель». За пределами исследовательских лабораторий с большими бюджетами в 2026 году это почти всегда неверный шаг. Интересная инженерия сегодня происходит в тех 20% стека, что ближе всего к пользователю, — поиск, UX, evals, защитные ограничители (guardrails), — а не в переизобретении GPT.
Паттерн 1 — Голосовые ассистенты и голосовой поиск
Голос — паттерн с самой высокой отдачей для любого продукта, где у пользователей заняты руки: диджеи во время сета, водители, хирурги, складские работники, авторы, родители. Вы заменяете многошаговый интерфейс одной фразой: «Собери плейлист в стиле латинопоп, 150 BPM, без Bad Bunny».
Для Franchise Record Pool — платформы для диджеев с 720 000 лицензированных треков от Sony Music, Universal и Virgin Records — мы выпустили голосового диджей-ассистента на базе Whisper (транскрибация), GPT-5 (извлечение намерения), поиска по каталогу FRP и Amazon Polly (голос ответа). Теперь диджеи проходят путь от идеи до сохранённого плейлиста одной фразой вместо прежнего интерфейса с пятью шагами фильтрации.
Анатомия продакшен-пайплайна для голоса
1. Захват. Моно-PCM 16 кГц с микрофона, передаётся потоком чанками по 250 мс. Эхоподавление и VAD происходят на стороне клиента (встроенных средств WebRTC достаточно).
2. Транскрибация. Whisper (large-v3 для пакетной обработки, gpt-4o-mini-transcribe для реального времени, ~0,45 ₽/мин), Deepgram Nova-3 (~0,57 ₽/мин), когда нужны частичные результаты быстрее 300 мс, или AssemblyAI, когда из коробки нужна разметка тональности и сущностей.
3. Понимание. Вызов LLM со строгой JSON-схемой и tool-use-промптом: намерение, сущности, значения слотов. Держите это за границей вызова функций, чтобы ваш бэкенд никогда вслепую не исполнял строки в свободной форме.
4. Действие. Вызовите свой реальный API. Эту часть пропускает любой туториал по AI. И именно она — 80% инженерных усилий.
5. Ответ. Синтез речи (TTS) обратно пользователю (Polly, ElevenLabs или Azure) или отрисовка в интерфейсе. Цель — меньше 1,2 с от начала до конца; всё, что дольше 1,5 с, ощущается как поломка.
Берите голосового ассистента, когда: у целевого пользователя руки заняты, у графа действий есть понятные глаголы (создать, найти, изменить), а экономия даже трёх кликов за сессию накапливается при ежедневном использовании.
Паттерн 2 — Транскрибация и перевод в реальном времени
Распознавание (ASR) и перевод речи в реальном времени — второй по частоте запрос на AI, который мы получаем. И здесь же плохие продуктовые решения обходятся дороже всего, потому что стриминг тарифицируется за минуту соединения, а не за сказанное слово.
Мы создали Translinguist (и родственную ему платформу Video Interpretations) для живых мероприятий с синхронным, последовательным и жестовым переводом на 62 языка. Каждый участник слышит только свой язык; субтитры генерируются автоматически; специальные термины и имена собственные сохраняются через слой кастомного глоссария. Подробнее об архитектуре — в нашем руководстве по многоязычному переводу в видеозвонках.
Whisper против Deepgram против AssemblyAI (наш вердикт за минуту)
Whisper / OpenAI Realtime. Самый дешёвый — ~0,45 ₽/мин в пакетном режиме. Лучше всего, когда вы готовы терпеть задержку 500–900 мс или работать асинхронно. С августа 2025 года API gpt-realtime даёт настоящий стриминг; внедрение быстро догоняет.
Deepgram Nova-3. Частичные результаты быстрее 300 мс, ~0,57 ₽/мин по факту использования. Первый выбор, когда нужен по-настоящему реальный масштаб времени (голосовые агенты, живые субтитры, hands-free в стиле диджеев).
AssemblyAI. ~0,31 ₽/мин по факту (тарифицирует длительность сессии, что на практике добавляет ~65% накладных расходов). Лучший вариант, если нужны транскрибация плюс анализ тональности, удаление PII и распознавание сущностей в одном пакете.
Берите перевод в реальном времени, когда: ваш продукт — это живая видео- или голосовая среда (конференции, телемедицина, зал суда, класс), и каждый участник говорит на своём языке. Если разговор может подождать 10 секунд, асинхронный Whisper обычно в 5 раз дешевле.
Паттерн 3 — Компьютерное зрение и распознавание объектов
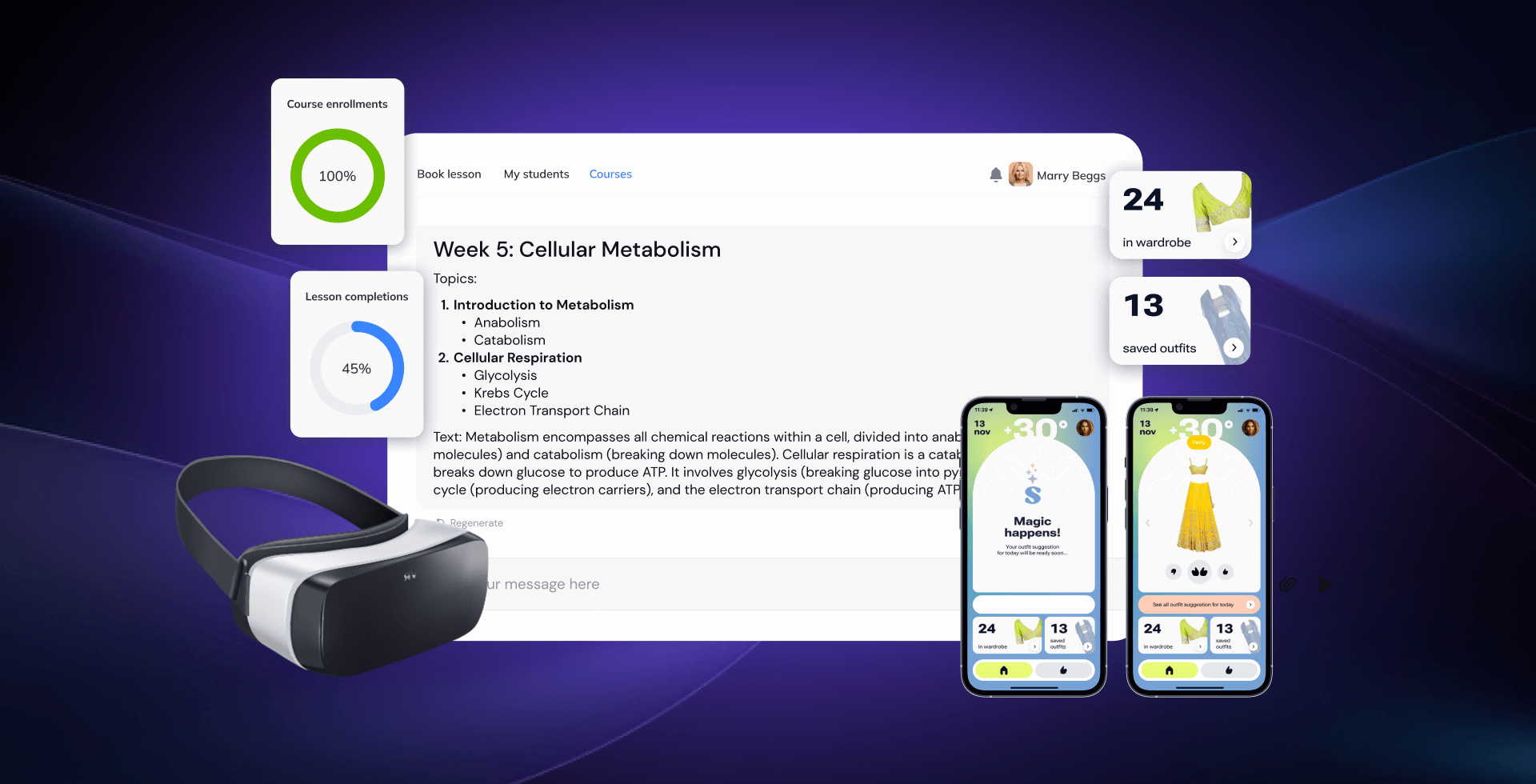
Компьютерное зрение вышло в массовый продукт в тот момент, когда YOLOv8 и CLIP стали достаточно компактными для мобильных устройств. Мы использовали оба в FashionAI — приложении для организации гардероба, которое мы обучили распознавать не только тип одежды, ткань, цвет и узор, но и длину рукава, форму выреза, мотивы узоров и категории индийской этнической одежды, которых нет в предобученных датасетах.
Стек: TensorFlow Lite с моделью YOLOv8m для детекции объектов, Apple Vision и PyTorch для более глубокого извлечения признаков и CLIP от OpenAI для семантических эмбеддингов, на которых работает рекомендация в духе «найди мне красную курту, в которой можно пойти на бранч». О том, как доводить это до продакшена, читайте в нашем руководстве по найму инженеров компьютерного зрения.
На устройстве или в облаке — решение, от которого зависит всё остальное
На устройстве (TFLite / CoreML / NNAPI). Нет платы за каждый инференс, приватность сохраняется, работает офлайн, но вы ограничены YOLOv8-nano или небольшими размерами моделей (~3–22 МБ). Используйте, когда инференс идёт по фото и видео пользователей и есть риск с хранением данных.
Облако. YOLOv8-m/l/x на GPU-машине, ~0,07–0,75 ₽ за изображение. Используйте, когда одно изображение стоит обращения к серверу (юридические документы, медицинские снимки, страховые заявки) или точность важнее задержки.
Гибрид. YOLOv8-nano на устройстве для обычных случаев, переход в облако для крайних случаев (edge cases). Именно так работает FashionAI — 95% фотографий гардероба обрабатываются за 180 мс на устройстве; необычная этническая одежда получает второе мнение из облака.
Берите компьютерное зрение, когда: ваши пользователи иначе вручную размечали бы то, что на изображении (одежда, чеки, помещения, еда, дефекты), и вы можете собрать более 2 000 размеченных примеров тех крайних случаев, которые упускают универсальные модели.
Паттерн 4 — Контент, сгенерированный AI, и черновики
Генерация контента — самый «очевидный» AI-паттерн и при этом тот, что быстрее всего проваливается при наивном внедрении. Выигрышный сценарий — это никогда не «нажми кнопку, получи 800 слов и надейся». Это «нажми кнопку, получи черновик на 70%, который следует моей схеме, а человек доводит остальное».
ALDA, наш AI-ассистент для преподавателей колледжей и университетов США, генерирует учебные планы, которые должны соответствовать шаблонам конкретного учебного заведения (зачётные часы, формат оценивания, теги аккредитации). Мы не используем свободные промпты к GPT; мы берём OpenAI Assistants со структурированной схемой, передаём шаблон учебного плана заведения как обязательную функцию и даём преподавателю редактировать в контексте. Преподаватели сообщают о примерно четырёхкратной экономии времени на черновиках.
Пять правил для генеративных функций, за которые не будет стыдно
1. Всегда структурированный вывод. Заставляйте модель отдавать вывод по JSON-схеме, а затем отрисовывайте его. Никогда не пускайте сырой текст модели прямо в интерфейс.
2. Опирайтесь на свои данные. Генерация с опорой на поиск (Retrieval-Augmented Generation, RAG) снижает галлюцинации на 42–68% в опубликованных бенчмарках; в узких вертикалях ответы с опорой на RAG достигают точности 89% против чуть выше 50% у LLM без опоры на данные.
3. По одному оценщику на функцию. Автоматические evals (Ragas, LangSmith или собственный набор на pytest) запускаются при каждом изменении промпта. Нет evals — на третьей неделе вы молча деградируете в качестве.
4. Для ответственного вывода всегда нужен человек в контуре (human-in-the-loop). Учебные планы, юридические тексты, медицинские заключения, финансовые советы — сначала черновик, потом подтверждение человеком. Без исключений.
5. Показывайте источники. Пользователи доверяют сгенерированному контенту примерно в 3 раза больше, когда рядом отображаются ссылки на источники. Это самая дешёвая победа в UX во всём AI-стеке.
Берите генерацию контента, когда: пользователи сейчас начинают с чистого листа, а первые 70% результата следуют предсказуемой структуре (учебный план, описание вакансии, план тренировок, план питания, спецификация продукта).
Паттерн 5 — Рекомендации и персонализированные ленты
Рекомендации — самая незаметная победа. Никто не пишет в соцсетях про хорошую ленту, но удержание, длительность сессии и доход от рекламы сразу идут вверх.
В BlaBlaPlay — анонимной соцсети голосовых карточек — мы использовали два слоя рекомендаций. Первый — генератор подсказок «о чём записать?» (OpenAI API с ежедневно меняющимся сидом на основе трендовых карточек). Второй — переранжировщик ленты, который сопоставляет эмбеддинги прослушанных и избранных карточек пользователя с пулом свежих карточек. После запуска обоих доля «молчаливых ответов» на голосовые карточки резко упала, а средняя длительность сессии выросла на ощутимые двузначные проценты.
В FRP тот же паттерн питает «похожие треки» и «другие диджеи, которые играли это, играли…» — классическую коллаборативную фильтрацию, перестроенную на эмбеддингах OpenAI + pgvector вместо старых пайплайнов матричной факторизации, которые требовали в 10 раз больше инженерной работы.
Эталонный стек для первой системы рекомендаций
Активность пользователя → Очередь событий (SQS / Redpanda)
↓
OpenAI text-embedding-3-small
↓
pgvector (или Pinecone при масштабе)
↓
ANN-запрос (top-k, косинус) + переранжирование (BGE / Cohere rerank)
↓
Feed API + A/B-флаг + логирование кликов
Берите рекомендации, когда: в каталоге более 500 элементов, есть хотя бы несколько тысяч активных пользователей, дающих сигнал, и есть лента или список, где текущий порядок — хронологический или случайный.
Паттерн 6 — Модерация контента, доверие и безопасность
У любого продукта с пользовательским контентом (UGC) рано или поздно возникает проблема модерации. AI-модерация перестаёт быть опцией, как только вы переваливаете за несколько тысяч постов в день: очереди только из живых модераторов плавятся, а платформенные модераторы (Apple, Google, Meta) могут вас отключить, если стандартные ML-классификаторы пометят ваше приложение раньше, чем это сделаете вы.
Слой модерации в BlaBlaPlay состоит из трёх этапов. Сначала Whisper транскрибирует каждую голосовую карточку на стороне сервера. Затем дообученный классификатор выявляет оскорбления, угрозы и адресную травлю. Наконец, помеченные карточки попадают в очередь модератора (не удаляются автоматически), где решение принимает админ. CoreML выполняет быстрый предварительный фильтр на устройстве, так что очевидные нарушения вообще не доходят до сервера.
Ловушка ложных срабатываний (и как её избежать)
Готовые API модерации ошибочно классифицируют идентичностные термины («мусульманин», «гей», лексику про инвалидность, AAVE) как оскорбительные гораздо чаще, чем нейтральный английский, — это хорошо задокументированное искажение. В прямых сравнениях Claude достигает точности 0,92 при всего 2,2% ложных срабатываний, тогда как Gemini часто перебарщивает с метками при точности ~0,77. Внедряйте тот классификатор, которому доверяете, добавьте слой человеческой проверки на первые 500 пометок в каждой категории и логируйте каждую апелляцию.
Берите AI-модерацию, когда: пользователи генерируют текстовый, голосовой или графический контент, очередь модерации растёт быстрее, чем вы успеваете нанимать, а ложное срабатывание стоит меньше (в доверии), чем пропущенное нарушение (в репутационном ущербе).
Стек AI, к которому мы обращаемся (и когда)
Мы намеренно высказываем мнение. Вот компоненты, которые мы выбираем по умолчанию в 2026 году, и альтернативы, к которым обращаемся, когда вариант по умолчанию не подходит.
| Слой | По умолчанию | Альтернатива | Когда переключиться |
|---|---|---|---|
| LLM | GPT-5 / GPT-5-mini (OpenAI) | Claude Sonnet 4.6 / Opus 4.6 | Длинный контекст, сложные рассуждения, агентные сценарии |
| Бюджетная LLM | GPT-5 Nano (3,7 ₽ / 30 ₽ за 1 млн токенов) | DeepSeek V3.2 / Gemini 2.5 Flash | Объёмные нагрузки, сценарии с минимальной ценой |
| ASR в реальном времени | Deepgram Nova-3 | AssemblyAI / OpenAI Realtime | Нужны удаление PII и тональность в комплекте |
| Пакетный ASR | Whisper (large-v3) | Self-hosted faster-whisper на GPU | Требования к хранению данных / изолированный контур |
| TTS | ElevenLabs / Amazon Polly | Azure Neural TTS | Корпоративные SLA, HIPAA |
| Зрение | YOLOv8 + CLIP | Detectron2, SAM2, GPT-5V | Много сегментации, zero-shot-задачи |
| Векторная БД | pgvector (Postgres) | Pinecone, Weaviate, Qdrant | Более 50 млн эмбеддингов, низкая задержка p99 |
| На устройстве | TFLite (Android) / CoreML (iOS) | ONNX Runtime Mobile | Кроссплатформенность, паритет ARM/x86 |
| Evals и наблюдаемость | Ragas + LangSmith | Свой pytest + OpenTelemetry | On-prem, регулируемые данные |
Разрабатывать, покупать или комбинировать — как решить
Консенсус 2026 года во всех серьёзных разборах «разрабатывать или покупать» одинаков: покупайте тяжёлое ядро, разрабатывайте то, что вас отличает, и связывайте всё слоем AI. Полугодовая разработка, требующая двух штатных инженеров на постоянной основе, редко выигрывает у покупки, если учесть обновления RAG-пайплайна, переобучение модели и поддержку интеграций.
Три варианта, которые мы предлагаем клиентам
Вариант A — Купить SaaS. Zapier/Make + готовый AI-SaaS (Jasper, Intercom Fin и т. п.). Самый быстрый. Потолок — это воображение вендора, а не ваше. Лучше всего, когда AI — это галочка в списке функций, а не суть ценности.
Вариант B — Разработать на API. OpenAI/Anthropic/Deepgram + ваш бэкенд + ваш UX. Это 80% того, что мы выпускаем. Вам принадлежат рабочий процесс и данные, вендорам — модели. Стоимость: 1,1–3,7 млн ₽ за v1, 3–8 недель с нашим процессом Agent Engineering.
Вариант C — Разработать с нуля. Обучите или дообучите собственную модель. Только когда ваши данные действительно уникальны и сама модель — конкурентное преимущество (редкость). Бюджет — от 75 млн ₽.
Берите вариант B (разработка на API), когда: AI — часть того, что делает ваш продукт лучше конкурентов, у вас есть отличающие данные или процесс, а ваша команда (или команда вашего партнёра) уже выпускает бэкенд и мобильные приложения в продакшен.
Нужно второе мнение по вопросу «разрабатывать или покупать»?
Мы сопоставим ваш AI-сценарий с одним из шести паттернов, назовём стек и дадим честную первую оценку за 30 минут.
Мини-кейс — голосовой диджей-ассистент FRP
Ситуация. Franchise Record Pool даёт более чем 40 000 профессиональных диджеев доступ к 720 тысячам лицензированных треков от Sony Music, Universal и Virgin Records плюс глубокую интеграцию с Serato DJ. Каталог и был фишкой — но поиск представлял собой интерфейс с пятью шагами фильтрации, к которому диджеи не прикасались во время сета.
План на 12 недель. Недели 1–3: связать вызовы функций Whisper + GPT-5 с поисковым API FRP. Недели 4–6: построить голосовой интерфейс, добавить ответ через Polly. Недели 7–9: обучить классификатор намерений на 2 000 залогированных запросов диджеев. Недели 10–12: распознавание музыки («Какой трек только что ремикснул другой диджей?») плюс набор evals на 500 реальных запросов.
Результат. Время создания плейлиста схлопнулось с пяти шагов фильтрации до одной фразы. Теперь сессии диджеев включают голосовое редактирование плейлистов прямо во время сета; распознавание музыки добавляет найденные треки сразу в крейт диджея. Архитектуру смотрите в полном кейсе FRP.
Мини-кейс — генератор учебных планов ALDA
Ситуация. Преподаватели колледжей США тратят 8–15 часов на курс, составляя учебные планы, рубрики оценивания и планы лекций, которые должны соответствовать шаблонам конкретного заведения (зачётные часы, теги аккредитации, таксономия результатов обучения). Существующие AI-инструменты выдавали обобщённый контент, который приходилось переписывать.
План на 12 недель. Недели 1–2: загрузить шаблоны учебных планов заведения, сопоставить их с JSON-схемой. Недели 3–6: построить OpenAI Assistant с вызовами инструментов для генерации разделов и редактирования по месту. Недели 7–9: слой RAG поверх прежних учебных планов и каталога курсов заведения. Недели 10–12: набор evals + UX с преподавателем в контуре.
Результат. Время на черновик учебного плана сократилось примерно в 4 раза. Преподаватели сохраняют полный редакторский контроль; черновик от AI из коробки соответствует шаблону их заведения. Смотрите страницу проекта ALDA.
Мини-кейс — живой перевод Translinguist на 62 языка
Ситуация. Международные мероприятия (конференции, залы суда, аудитории) всё ещё полагаются на живых синхронных переводчиков — дорого, их мало, и невозможно масштабировать на редкие языковые пары. Машинный перевод существовал, но простое соединение обычных ASR + машинного перевода (MT) + TTS звучало роботизированно и теряло смысл, вложенный говорящим.
План на 12 недель. Недели 1–3: определение языка + диаризация дикторов в живом аудиопотоке. Недели 4–6: передача в слой перевода на LLM с доменными глоссариями (юридический, медицинский, технический). Недели 7–9: нейросетевой TTS, сохраняющий темп, интонацию и паузы. Недели 10–12: дорожка жестового перевода + генерация субтитров.
Результат. Поддерживаются 62 языка от начала до конца, каждый участник слышит только свой целевой язык, субтитры генерируются автоматически, а специализированная терминология (названия дел, медицинские диагнозы, названия продуктов) переживает перевод благодаря глоссариям под каждое мероприятие. Полную архитектуру смотрите в кейсе Video Interpretations.
Сколько на самом деле стоит выпустить AI-функцию
Любой аналитический диапазон стоимости AI-разработки бесполезен без точки отсчёта. Опубликованные диапазоны 2026 года — от 3 до 30 млн ₽ «для большинства бизнес-сценариев». Это правда, но распределение бимодальное. Функции на API-first сгруппированы у нижней границы; кастомное обучение тянет вверх верхнюю.
| Масштаб функции | Типичная v1 | Диапазон Фора Софт | Токены / инфраструктура в месяц |
|---|---|---|---|
| Чат- или голосовой ассистент по существующим данным | 3–5 недель | 1,1–2,2 млн ₽ | 22 500–150 000 ₽ / мес |
| Генерация контента / инструмент черновиков | 2–4 недели | 750 тыс.–1,8 млн ₽ | 15 000–225 000 ₽ / мес |
| Рекомендации / переранжирование ленты | 3–6 недель | 1,3–2,6 млн ₽ | 15 000–112 500 ₽ / мес |
| Перевод в реальном времени / ASR-пайплайн | 6–10 недель | 2,6–5,2 млн ₽ | 0,75–1,5 ₽ за минуту пользователя |
| Компьютерное зрение (на устройстве + облако в резерве) | 5–8 недель | 1,8–4,5 млн ₽ | 3 750–75 000 ₽ / мес + данные |
| Модерация контента (голос или текст) | 4–6 недель | 1,3–3 млн ₽ | 7 500–75 000 ₽ / мес |
Две ремарки. Во-первых, эти диапазоны предполагают API-first архитектуру и наш процесс Agent Engineering — мы оцениваем быстрее, чем агентства, всё ещё берущие деньги за написанный вручную шаблонный код. Во-вторых, мы намеренно не приводим диапазоны для дообучения или обучения базовых моделей — правильный ответ там зависит от размера датасета и бюджета на вычисления, а мы не хотим называть с потолка цифру, за которую вы потом нас поймаете.
Фреймворк решения — выберите правильную AI-функцию за пять вопросов
Q1. Экономит ли функция время пользователей на задаче, которую они выполняют хотя бы раз в неделю? Если нет, вы, скорее всего, строите демо, а не функцию для удержания. Стоп.
Q2. К какому из шести паттернов она относится? Голос, ASR/перевод, зрение, генерация, рекомендации, модерация. Если ни один не подходит, вы в режиме исследования — сделайте прототип на готовом API за две недели, прежде чем писать ТЗ.
Q3. Сколько стоит неправильный ответ? Низкая цена (рекомендательная лента): выпускайте. Средняя (черновик учебного плана): добавьте проверку человеком. Высокая (медицина, право, финансы): обязательны подтверждение человеком, структурированный вывод и ссылки на источники.
Q4. Достаточно ли у вас собственных данных, чтобы сделать функцию лучше, чем у обычного API? Если да, у вас есть конкурентное преимущество — вкладывайтесь в RAG и evals. Если нет, купите SaaS и конкурируйте на UX.
Q5. Потянете ли вы худший сценарий по счёту за токены при 10-кратном росте DAU? Если ответ заставляет поморщиться, переделайте: агрессивно кэшируйте, используйте пакетную обработку, берите бюджетный уровень (GPT-5 Nano, Gemini Flash, DeepSeek) для простых вызовов и переходите на флагман только для сложных.
Пять ошибок, которые мы видим снова и снова
1. Запуск без evals. Самая частая ошибка. Функция работает в день запуска, молча деградирует на третьей неделе, когда OpenAI обновляет модель, и команда замечает это, только когда жалуются пользователи. Постройте набор evals до того, как построите функцию.
2. Свободные промпты в продакшене. Если ваш бэкенд принимает всё, что LLM возвращает как свободный текст, кто-нибудь через промпт-инъекцию проберётся в вашу базу данных. Всегда требуйте структурированный вывод (JSON-схема, вызовы функций), проверяйте его, а затем действуйте.
3. Игнорирование кэширования токенов. OpenAI и Anthropic в 2026 году дают около 90% скидки на кэшированный ввод. Большинство команд первые полгода не отслеживают попадания в кэш и переплачивают в 5–10 раз.
4. Чрезмерное доверие к API модерации. Универсальные классификаторы излишне помечают переосмысленные ругательства, AAVE и идентичностные термины. Всегда добавляйте путь для апелляции к человеку — не потому что вы не доверяете модели, а потому что модель относится к вашим пользователям с асимметричным недоверием.
5. Оценка по меркам 2023 года. Команды, которые до сих пор оценивают AI-функции в 11–22 млн ₽ за v1, либо берут по ставкам исследовательской лаборатории, либо не перешли на Agent Engineering. Если ваша оценка не улучшилась в 2–3 раза по сравнению с 2023 годом, вы оставляете на столе время и деньги.
KPI — как понять, что AI-функция себя окупает
KPI качества. Обоснованность (доля ответов, подкреплённых найденным контекстом, цель >0,9), доля галлюцинаций (цель <2%), успешность задачи (доля сессий, в которых намерение выполнено, цель >0,8), доля правок человеком (доля черновиков AI, отредактированных более чем на 20%, цель <0,5).
Бизнес-KPI. Прирост активации в сессиях с AI-функцией (цель +15–30% к контролю), прирост 30-дневного удержания (цель +5–15%), выручка с пользователя для платных AI-функций (выставляйте цену так, чтобы валовая маржа была >60% после стоимости токенов), отклонение обращений в поддержку (цель 10–30% для AI-чат-ассистентов).
KPI надёжности. Задержка p95 (голос: <1,2 с; генерация текста: <3 с), стоимость модели на активного пользователя (цель <15% от выручки с пользователя), доля попаданий в кэш (>50% в зрелых функциях), доля прохождения evals удерживается выше 0,85 при каждом изменении промпта или модели.
Когда НЕ стоит добавлять AI в продукт
Мы отказываемся от AI-проектов примерно на каждом втором установочном звонке. Самые честные сигналы, что AI — неправильная следующая функция:
- Ваш основной продукт ещё не нашёл product-market fit (PMF) — AI не решит проблему удержания, а лишь добавит запутанный интерфейс.
- Задача требует детерминированного вывода (расчёт налогов, документы для комплаенса, код, который обязан компилироваться). Используйте правила и типы; LLM по своей природе вероятностны.
- У вас меньше 500 документов / меньше 5 тысяч элементов. RAG раскрывается на масштабе; при таком объёме тщательно составленный FAQ обходит RAG-чатбот и по точности, и по стоимости.
- Бюджет задержки меньше 100 мс. Даже самые быстрые модели реального времени — это сотни миллисекунд; если нужен ответ за миллисекунды, считайте заранее и кэшируйте.
- Ваша команда никогда не выпускала в продакшен бэкенд и мобильные приложения. AI — это глазурь; сначала нужен сам торт.
Хотите похожую оценку для вашего продукта?
Мы скажем, какой из шести паттернов подходит, как выглядит первая готовая к выпуску v1 и сколько это примерно стоит, — за один 30-минутный звонок, без слайдов.
Частые вопросы
Как быстро Фора Софт может выпустить первую AI-функцию?
Для очерченной функции, относящейся к одному из шести паттернов, v1 обычно выходит за 3–6 недель с нашим процессом Agent Engineering. Сюда входят бэкенд, AI-пайплайн, evals и готовый к выпуску интерфейс — не прототип.
Нужно ли нам обучать собственную модель?
Почти никогда. Базовые модели 2026 года (GPT-5, Claude 4, Gemini 2.5) плюс RAG и лёгкое дообучение покрывают более 95% продуктовых сценариев. Обучение с нуля имеет смысл, когда ваши данные — это конкурентное преимущество и ни одна коммерческая модель не охватывает вашу область.
Каков типичный регулярный счёт за токены и инференс?
Для запущенной функции масштаба SaaS мы видим 0,75–6 ₽ на активного пользователя в день на стеках на базе API, что падает до 0,15–1,5 ₽ после внедрения кэширования и маршрутизации по уровням моделей (Nano/Flash для простых вызовов, флагман для сложных).
Как вы решаете вопросы приватности данных и комплаенса?
По умолчанию мы используем корпоративные эндпоинты OpenAI/Anthropic (данные не используются для обучения) или Azure OpenAI / AWS Bedrock для нагрузок под регулирование HIPAA, GDPR и SOC 2. При требованиях к хранению данных мы разворачиваем open-source-модели (Whisper, Llama, Mixtral) на собственной инфраструктуре клиента.
Сделает ли AI разработку моего продукта в целом дешевле?
Для самой AI-функции — да, кардинально. API-first архитектура плюс Agent Engineering сокращают время разработки функции в 2–3 раза по сравнению с нормами 2023 года. Для остального продукта (авторизация, интерфейс, платежи, комплаенс) стоимость почти не меняется — AI не уменьшает не-AI-часть, которую всё равно нужно построить.
OpenAI, Anthropic или open source — что вы рекомендуете?
OpenAI GPT-5 для большинства продуктовых поверхностей (дешевле на флагманском уровне, уровень Nano примерно в 20 раз ниже Claude Haiku для объёмных вызовов). Anthropic Claude, когда нужен длинный контекст или аккуратные агентные сценарии — у них гранулярное управление кэшем, а плоская цена на большой контекст непобедима. Open source (Llama, Mixtral, Whisper) — для развёртываний с требованиями к хранению данных или в изолированном контуре.
Что Фора Софт делает иначе, благодаря чему оценки ниже?
Agent Engineering — пайплайны со спецификацией в первую очередь, агентная генерация кода, непрерывные evals. Шаблонный код, на который раньше уходила неделя у двух инженеров, теперь занимает одно утро. Эту экономию мы передаём в оценку, а не оставляем себе как маржу — поэтому наши диапазоны для v1 ниже агентских норм.
Можете ли вы работать с нашей существующей командой?
Да — мы так же часто работаем по модели выделенной команды или усиления, как и над проектами под ключ. Мы работаем в паре с вашими инженерами над AI-пайплайном, evals и инфраструктурой и полностью передаём знания, прежде чем уйти.
Что почитать дальше
Методология
Agent Engineering на основе спецификаций
Как мы выпускаем production-функции с AI в 2–3 раза быстрее, чем в 2023 году.
Руководство
Как создавать приложения с AI
Сквозной паттерн для выпуска AI-native-приложений, а не просто прикрученных функций.
Глубокое погружение
Мультимодальные AI-агенты на LiveKit
Паттерн «голос + видео + tool-use», который мы используем для real-time-агентных продуктов.
Кейс
Многоязычный перевод в видеозвонках
Разбор архитектуры Translinguist — слои ASR, MT, TTS и глоссария.
Найм
Нанять разработчиков компьютерного зрения
На что смотреть при формировании команды компьютерного зрения — навыки, стек и сигналы готовности к продакшену.
Готовы выпустить AI, который действительно окупает счёт за токены?
Каждая AI-функция, которая в 2026 году выходит удачно, под капотом устроена примерно одинаково: стек «покупай модель, разрабатывай процесс», структурированный вывод, опора на поиск, evals и человек в контуре там, где ставки высоки. Шесть паттернов — голос, ASR/перевод, зрение, генерация, рекомендации, модерация — покрывают почти любую продуктовую идею, которую стоит реализовать в этом году.
Фора Софт сегодня выпускает все шесть в продакшен. Если вы дочитали досюда и у вас на уме есть конкретная функция, следующий шаг — 30-минутный звонок: мы сопоставим вашу идею с нужным паттерном, предложим стек и дадим оценку, настолько честную, что нам было бы стыдно потом от неё отказаться.
Давайте определим объём вашей первой AI-функции на этой неделе
30 минут, без слайдов. Вы уходите с конкретным паттерном, конкретным стеком и диапазоном оценки, который можно вынести на совет директоров.