
Главное
• NLU перестал быть просто связкой «намерение + сущность» — это гибридный стек. В 2026 году любой бот поддержки в продакшене сочетает классический NLU (Rasa, Dialogflow CX, Amazon Lex, Microsoft CLU) с веткой LLM + RAG и защищает всё это гардрейлами. Чисто правиловые боты закрывают 15–25% обращений; гибридные NLU-боты — 42–58%.
• Гардрейлы важнее «голой» точности. Классификатор намерений с точностью 88%, который маскирует персональные данные, проверяет намерение повторно и использует порог уверенности 0.65, работает лучше, чем классификатор с точностью 92%, но склонный к ошибкам вроде ложных обещаний возврата денег. Гибридные архитектуры снижают долю таких ошибок с 5–15% до 2–4%.
• Реалистичная экономика. Кастомный NLU-бот, собранный с подходом Agent Engineering, обходится примерно в 4,5–12 млн ₽ для небольшого и среднего объёма задач и окупается за 8–14 месяцев на любой команде поддержки, которая обрабатывает больше ~300 обращений в день. SaaS-решения (Ada, Cognigy, Intercom Fin) дешевле на старте, но дороже масштабируются после ~10 тыс. обращений в день.
• KPI, а не интуиция. Следите за долей обращений, закрытых без участия оператора (containment rate), долей решённых с первого раза, частотой галлюцинаций, количеством эскалаций к оператору, P95-задержкой и изменением стоимости обращения. Если вы не анализируете эти показатели каждую неделю, вы работаете не в том направлении.
• Не запускайте NLU-бота под каждый сценарий. Обращения с высокой эмоциональной нагрузкой, юридически значимые обязательства, редкие узкоспециализированные онтологии и очереди меньше 500 обращений в месяц лучше решать через продуманный FAQ и передачу на человека. Ниже разбираем, где проходит граница.
Зачем Фора Софт написала этот плейбук
Фора Софт 21 год разрабатывает диалоговые, AI- и видеопродукты — более 625 решений в e-learning, телемедицине, видеонаблюдении, OTT, маркетплейсах и корпоративном SaaS. Наша команда по искусственному интеллекту внедряла NLU в ботов поддержки, in-app-ассистентов, голосовые IVR и чаты для live-ecommerce и P2P-рынков. Мы не продаём готовую чат-бот-платформу — создаём индивидуальные NLU-системы поверх стека, выбранного заказчиком: Rasa, Dialogflow CX, Amazon Lex, Azure CLU или гибридный LLM + RAG-решение в GCP, AWS или на локальном сервере.
Этот плейбук — то, что мы рассказываем клиентам на первой неделе работы над NLU-ботом: какой подход выбрать, где классический NLU всё ещё лучше LLM, какие реальные бюджеты получаются с нашими AI-услугами и Agent Engineering, какие меры безопасности обязательны и в какой момент бот должен передать диалог человеку. Если хотите контекст по соседним AI-проектам, посмотрите наши материалы о API голосовых AI-ассистентов и мультимодальных агентах LiveKit.
Скоупите бота поддержки с NLU?
Тридцати минут с инженером Фора Софт обычно достаточно, чтобы выбрать архитектуру, оценить бюджет и выделить два-три сценария отказа, которые с наибольшей вероятностью могут сорвать пилот.
Что на самом деле делает бот поддержки на базе NLU
Если убрать маркетинг, слой NLU (natural language understanding, понимание естественного языка) превращает свободное сообщение пользователя в структурированные сигналы, на которые нижестоящая система может реагировать. Таких сигналов всегда четыре — в той или иной комбинации.
1. Намерение (intent). Что хочет пользователь — отменить подписку, проверить баланс, пожаловаться или записаться на приём? Это может быть выбор из фиксированного списка (у бота 20–200 вариантов) или определение «на лету» в системах, где в основе лежит LLM.
2. Сущности и слоты. Структурированные значения внутри сообщения: номер заказа, сумма, дата, SKU товара, идентификатор аккаунта. Извлечение сущностей позволяет боту реально что-то делать, а не просто перенаправлять сообщение.
3. Контекст и состояние сессии. Память бота о последних N репликах, аккаунт клиента, открытая заявка, текущий шаг в многошаговом сценарии («у нас всё ещё нет даты доставки»).
4. Сентимент и сигнал эскалации. Пользователь спокоен, раздражён, агрессивен или близок к уходу? Анализ настроения (сентимент) определяет, как вести диалог: спокойного клиента можно оставить боту, а раздражённого — сразу передать оператору, пока ситуация не ухудшилась.
Чем это отличается от правиловых ботов
Правиловые боты ищут ключевые слова или регулярные выражения: «если в сообщении есть refund, показать сценарий возврата». Они просты в разработке, но ненадёжны в реальной эксплуатации: пользователь, написавший «верните мне деньги», не попадёт ни в одно правило. Отраслевые бенчмарки показывают, что правиловые боты самостоятельно закрывают 15–25% обращений. Настоящий NLU-бот понимает смысл через классификатор на трансформере или через LLM и закрывает 42–58% того же объёма.
Бот можно считать «на NLU», если он умеет хотя бы обрабатывать перефразировки, удерживать многошаговый контекст, извлекать сущности и оценивать уверенность в распознавании намерений. Всё, что ниже этой планки, — это древовидная логика в обёртке чат-виджета.
Срез рынка: что цифры реально показывают в 2026
Диалоговый AI больше не нишевое решение. Вот несколько цифр, которые мы используем, чтобы обосновать бизнес-обоснование перед клиентом:
| Метрика | Значение на 2026 | Почему это важно |
|---|---|---|
| Рынок диалогового ИИ | ~1,3 трлн ₽ сейчас → ~3,1 трлн ₽ к 2030, ≈18% CAGR | Ваши конкуренты уже закладывают это в бюджет — а не планируют на следующий год. |
| Доля компаний, у которых есть хотя бы один бот | ~70% среднего бизнеса, >80% компаний из списка Fortune 500 | Совет директоров уже спрашивает не «нужно ли нам это?», а «почему мы отстаём?». |
| Доля автономно закрытых обращений у NLU-бота | 42–58% (у правиловых: 15–25%) | Тот же трафик — примерно в 2–3 раза больше обращений, которые закрываются без участия оператора. |
| Стоимость обращения | ~37–90 ₽ (бот) против ~225–375 ₽ (оператор) | Отсюда и получается ROI; подставьте свои цифры. |
| Доля галлюцинаций | Чистый LLM — 5–15%; гибрид NLU+LLM — 2–4% | Именно поэтому нельзя просто подключить GPT к хелпдеску и отдохнуть. |
| CSAT: NLU-боты против правиловых | ~3,8/5 против ~2,1/5 | Пользователи это чувствуют; ваш NPS тоже. |
| Прогноз Gartner на 2026 | >75% взаимодействий со службой поддержки автоматизировано; к 2027 году чат-боты станут основным каналом примерно для 25% организаций | Если в вашем роадмапе нет автоматизации, вы постепенно теряете конкурентоспособность по себестоимости обслуживания. |
Это ориентировочные диапазоны — отчёты Gartner, Forrester и Grand View Research показывают цифры примерно на одном уровне. Важно не точное значение, а то, что бизнес-обоснование для качественного NLU-бота уже не выглядит как «давайте попробуем». К 2026 году доля автоматизированных обращений в поддержку уверенно приближается к трём четвертям от общего объёма.
Три архитектуры, из которых вы реально выбираете
В 2026 году вы выбираете не между «чат-бот-платформой A» и «чат-бот-платформой B». Вы выбираете между тремя архитектурными подходами, а платформу уже подбираете под выбранную архитектуру.
1. Классический NLU (намерение + сущность + заполнение слотов)
Классификатор намерений на основе трансформера и экстрактор сущностей управляют детерминированным менеджером диалога. Платформы: Rasa, Google Dialogflow CX, Amazon Lex, Microsoft Azure Conversational Language Understanding (CLU).
Сильные стороны. Предсказуемость, возможность аудита, низкий риск галлюцинаций (<1%), скорость (P95 50–200 мс), пригодность для развёртывания на локальных серверах под требования HIPAA/GDPR, низкая стоимость эксплуатации при больших объёмах.
Слабые стороны. Требуется 500–2000 размеченных примеров для каждого намерения. Чувствителен к новым формулировкам. Возможны коллизии намерений (например, «отмена» — отмена заказа или подписки?). Стоимость переобучения растёт с увеличением числа намерений.
Берите классический NLU, если: пространство диалогов ограничено (банкинг, телеком, бронирование авиабилетов), задержка зафиксирована в SLA или требования комплаенса требуют развёртывания системы на локальном сервере.
2. LLM-first с retrieval-augmented generation (RAG)
Входящее сообщение преобразуется в вектор, из векторной базы данных (Pinecone, Weaviate, pgvector) подтягиваются top-к наиболее релевантных документов, и LLM (GPT-4o/5, Claude, Gemini, Llama) генерирует ответ, опираясь на них. Намерение определяется в процессе.
Сильные стороны. Не требует разметки намерений. Первый демо-результат — за несколько дней, а не недель. Хорошо работает с перефразировками и сложными рассуждениями. Подходит для вопросов, требующих глубоких знаний.
Слабые стороны. Галлюцинации — 5–15% без использования гардрейлов. Задержка — 800 мс–3 с. Стоимость токенов растёт с увеличением длины истории. Риск утечки персональных данных, если не маскировать их перед отправкой в модель. Сложнее проводить аудит.
Берите LLM + RAG, если: большинство запросов — это вопросы «как мне…?» по базе знаний (поддержка SaaS, документация по продукту), у вас нет чёткой разметки намерений или важна гибкость диалога, а не строгая предсказуемость.
3. Гибрид: сначала классический NLU, потом LLM, с гардрейлами вокруг и того, и другого
Это форма по умолчанию, которую мы сегодня используем в любом среднем и крупном сценарии поддержки. Классический NLU обрабатывает топовые 50–70% трафика — чистые намерения и структурированные транзакции — с помощью шаблонных ответов. Если уровень уверенности падает ниже порога (обычно 0.75–0.85), сообщение передаётся в LLM с RAG. Всё, что генерирует LLM, проходит проверку: маскировка персональных данных, повторная классификация намерения, фильтры по тональности и политикам — только после этого ответ отправляется пользователю. При уверенности ниже второго порога (0.60–0.65) диалог передаётся оператору с полным контекстом.
Сильные стороны. Отличная экономия при масштабировании (большинство запросов обрабатываются без обращения к LLM). Уровень галлюцинаций снижен до 2–4%. Удобна для соблюдения нормативных требований. Расходы на токены легко прогнозировать. При высокой нагрузке система постепенно замедляется, но не падает.
Слабые стороны. Больше движущихся частей при сборке и эксплуатации. Нужна хорошая наблюдаемость и система оценки качества. Требуется команда, которая умеет настраивать и классификатор, и промпт-пайплайн.
Берите гибрид, если: у вас есть и структурированные транзакции (возвраты, статусы, переоформление), и открытые вопросы; объём — выше ~1000 обращений в день; либо комплаенс действительно важен (финансы, здравоохранение, страхование).
Сравнение платформ: что мы реально рекомендуем клиентам
Мы выводили в продакшен большинство этих платформ. Матрица ниже — шпаргалка, которую используем в первый день нового проекта. Ценовые диапазоны указаны публично на момент написания; реальные сделки могут смещать цифры.
| Платформа | Подход | Цена (ориентир) | Сильные стороны | Ограничения | Когда подходит |
|---|---|---|---|---|---|
| Rasa | Классический NLU + LLM-хуки, open source | Open source — бесплатно; Rasa Pro — от ~2,6 млн ₽ в год | On-prem, полный контроль, поддержка нескольких языков, высокая точность заполнения слотов | Крутая кривая в DevOps, узкий рынок специалистов | Регулируемые отрасли, требования к хранению данных |
| Dialogflow CX (Google) | Классика + LLM Gemini | ~0,5 ₽ за текстовый запрос, ~4,5 ₽ за голосовую минуту | Визуальный конструктор сценариев, CCAI Voice, интеграции с GCP | Стоимость за запрос быстро растёт, зависимость от GCP | Компании, использующие GCP, реализуют омниканальные решения с голосовым IVR |
| Amazon Lex V2 | Классический NLU + опционально LLM Bedrock | ~0,05 ₽ за текстовый, ~0,3 ₽ за голосовой запрос | Дёшево за запрос, глубокая интеграция с AWS Connect | NLU проще, чем в Dialogflow, базовый тулинг | Контакт-центры на AWS, телефония с большим объёмом |
| Microsoft CLU | Классический NLU + Azure OpenAI | Обязательство по Azure от ~37 тыс. ₽/мес | Сильный NER по сущностям, нативная интеграция в Teams, корпоративный SSO | Lock-in на Azure, менее открытая, чем Rasa | Корпорации на M365, внутренние ИТ-хелпдески |
| Cognigy | Корпоративный гибрид + LLM-оркестратор | От ~375 тыс. ₽/мес, корпоративные тарифы — от 1,5 млн ₽ | Отраслевые шаблоны, работа с несколькими каналами, мощная аналитика | Высокая постоянная стоимость, корпоративная закупка | Большие контакт-центры (>200 операторов) |
| Ada | LLM-первый подход с встроенными защитными фильтрами | От ~150 тыс. ₽/мес, средний сегмент — ~600–900 тыс. ₽/мес | Самый быстрый запуск, сборка сценариев без кода, неплохая система оценки | Меньше возможностей для расширения, только модели от производителя | SMB и быстрорастущие компании, которым нужна автоматизация в этом квартале |
| Intercom Fin | LLM-первичный подход, нативная интеграция с Intercom CRM | ~74 ₽ за решённое обращение + лицензии Intercom | Тариф по результатам, глубокая интеграция с Intercom | Имеет смысл, только если вы уже работаете в Intercom | Действующие клиенты Intercom, поддержка SaaS |
| Kore.ai | Гибрид, ориентированный на отрасли (здравоохранение, финансы) | От ~150 тыс. ₽/мес, корпоративные сделки — значительно выше | Готовые отраслевые сценарии, соответствие требованиям HIPAA | Сложное внедрение, дорогая лицензия | Регулируемые отрасли (медицина, банки, страхование) |
| Кастом (наш вариант по умолчанию) | Гибрид: Rasa / CLU как NLU + Claude/ GPT через RAG | Стоимость разработки и хостинга; без лицензий на пользователей | Полный контроль, лучшая юнит-экономика на масштабе, интегрируется с любым стеком | Нужна команда, которая реально доведёт его до продакшена | Любой сценарий с более чем 2 тыс. обращений в день или с необычной доменной онтологией |
Правило большого пальца: если у вас меньше ~500 обращений в день и нет особых требований по комплаенсу — начинайте с Ada или Intercom Fin. При нагрузке от ~500 до ~2000 обращений в день обычно лучше подходит управляемая сборка на Dialogflow CX или Lex. А при более чем ~2000 обращений в день или жёстких требованиях к хранению данных — кастомный гибрид Rasa + LLM окупается меньше чем за год.
Не уверены, какая платформа подойдёт под ваш объём и стек?
Оценим ваш трафик, текущую архитектуру и требования по комплаенсу и подберём оптимальную архитектуру за 30-минутный разговор. Без презентаций. Без продажного шума.
Эталонная архитектура production NLU-бота
На какой бы платформе вы ни оказались, гибридный production NLU-бот следует одному и тому же пайплайну. Это та же форма, что мы используем в голосовых агентах на мультимодальных LiveKit-агентах или в чат-ботах на Rasa Pro. Меняются только вендоры.
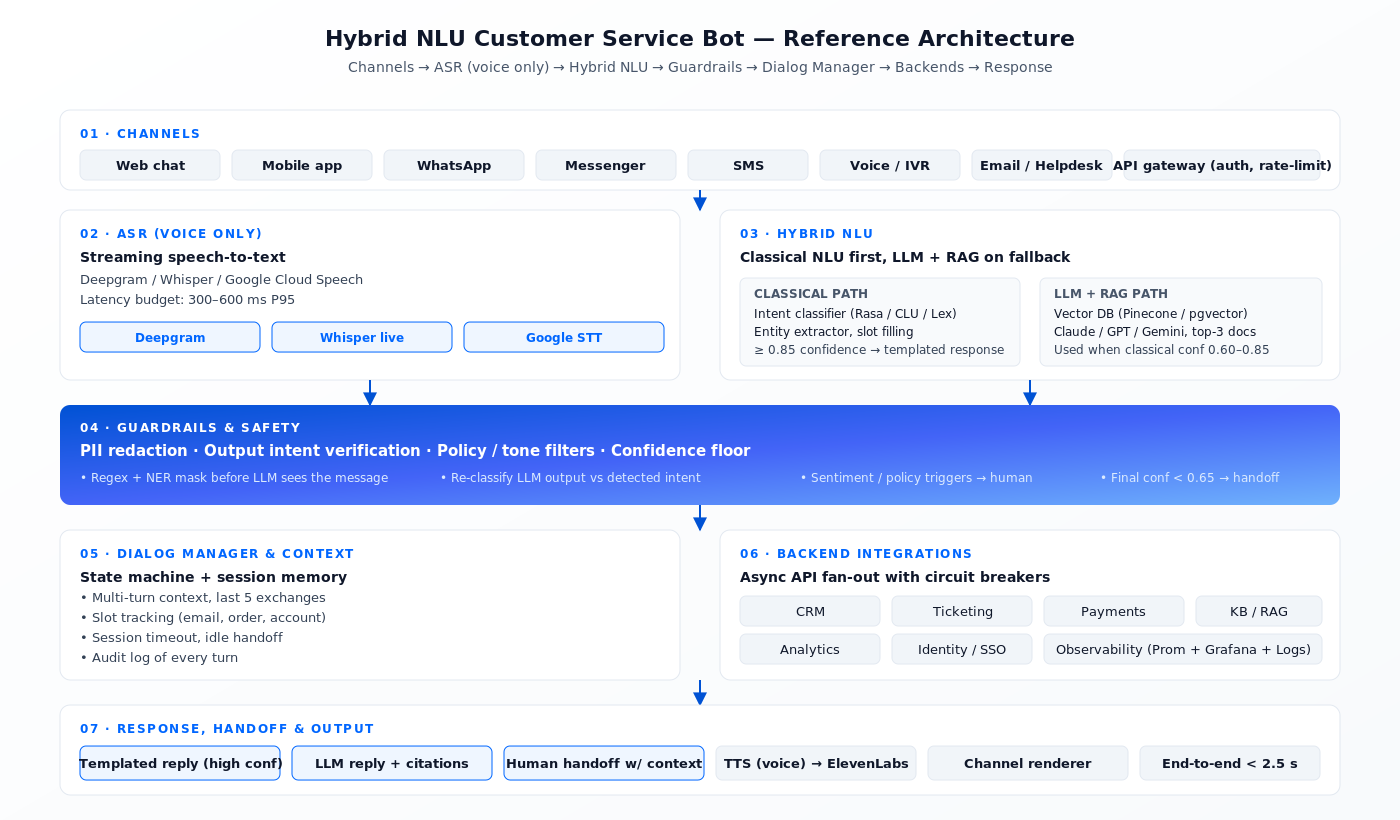
Рисунок 1. Пайплайн гибридного NLU-бота: каналы → ASR (голос) → гибридный NLU → гардрейлы → менеджер диалога → бэкенды → ответ → каналы.
Бюджет задержек, на который нужно ориентироваться при проектировании
| Этап | Целевой P95 | Тактика |
|---|---|---|
| ASR (голос) | 300–600 мс | Стриминговый ASR (Deepgram, Whisper-live) поверх REST |
| Классический NLU | <200 мс | Совмещённый с приложением классификатор, горячая модель в оперативной памяти |
| RAG + LLM | 800–1500 мс | Векторная БД top-3, короткие промпты, стриминг токенов |
| Гардрейлы | <150 мс | Регулярки + лёгкий NER; без второго вызова LLM |
| Бэкенд (CRM/заказы) | <800 мс | По возможности асинхронно, circuit breaker, кэшированные lookup-запросы |
| TTS (голос) | 300–800 мс | ElevenLabs / Google TTS с заранее созданными подсказками |
| Целевой end-to-end | <2,5 с в тексте, <2,0 с в голосе | Всё, что работает медленнее, пользователь воспринимает как сломанное |
Как выглядит гибридная маршрутизация в коде
Упрощённая версия маршрутизации, которую мы поставляем, — без обвязки интеграций — помещается в 30 строк:
async def handle_message(user_msg: str, session: Session) -> Response:
redacted = pii.redact(user_msg) # mask SSN, cards, emails
nlu = classical.predict(redacted, session) # intent + entities
if nlu.confidence >= 0.85 and nlu.intent in TEMPLATES:
return render_template(nlu.intent, nlu.slots, session)
if nlu.confidence >= 0.60:
docs = vector_db.search(redacted, k=3, filter=session.tenant)
llm_out = llm.generate(prompt(redacted, docs, session.history))
check = guardrails.verify(llm_out, expected_intent=nlu.intent)
if check.ok and check.confidence >= 0.65:
return Response(text=check.text, intent=nlu.intent)
# Low confidence or guardrail failure -> human
handoff.enqueue(session, reason="low_confidence", nlu=nlu)
return Response(text=HANDOFF_MESSAGE, intent="handoff")
Три важные детали: персональные данные скрываются ещё до того, как их увидит любая модель; LLM запускается только на тех случаях, где уверенность средняя; если уверенность низкая или сработал гвардрейл — задача передаётся человеку с полным контекстом, а не с безликим «я не понял».
Гардрейлы: фича, которая отличает игрушку от боевого бота
Самая частая причина смерти пилота NLU-бота после демо — отсутствие гардрейлов. Бот, который однажды самовольно вернул деньги, обходится дороже всей разработки, вложенной в него. Четыре гардрейла, которые мы считаем обязательными:
1. Детекция и маскирование персональных данных. Используем регулярные выражения для структурированных форматов (карта, СНИЛС, IBAN, телефон) и NER-обработку для имён и названий организаций. Перед отправкой сообщения в LLM заменяем найденные данные токенами ([EMAIL], [ORDER_ID]).
2. Проверка намерения на выходе. Повторно классифицируйте ответ LLM. Если он отличается от определённого намерения пользователя более чем на порог (мы используем 15%), передавайте оператору. Это не даёт боту тихо «уплыть» в постороннюю тему.
3. Фильтры политик и тональности. Проверки по правилам на запрещённые темы — например, обещания по ценам, которые нельзя давать, медицинские диагнозы, юридические советы — и триггер по тональности, который сразу фиксирует агрессивные или потенциально опасные для оттока диалоги.
4. Порог уверенности и аккуратная передача оператору. Если итоговая числовая уверенность ниже 0,60–0,65, клиента передают оператору вместе с полной перепиской и зафиксированным намерением. Ничто так не раздражает пользователя, как необходимость повторять всю историю после общения с ботом.
Закладывайте бюджет на гардрейлы в первую очередь: в наших проектах это примерно 15–20% всех инженерных усилий. Срезание этого угла — самый надёжный способ загубить пилот уже на третий день в продакшене.
Реалистичная экономика разработки кастомного NLU-бота
Диапазоны ниже — те, которые мы реально используем в оценках в 2026 году, с применением Agent Engineering для ускорения прототипирования и работы с данными. Они намеренно консервативны: мы предпочитаем заранее обозначить ожидания и сдать проект дешевле, чем выиграть сделку на завышенной оценке. Традиционные агентства за сопоставимый объём работы берут примерно на 30–40% больше.
| Скоуп | Что входит | Оценка с Agent Engineering | Сроки |
|---|---|---|---|
| Небольшой пилот | FAQ + 3–5 намерений, 1 канал, базовые гардрейлы, чтение CRM | ~4,5–8,2 млн ₽ | 6–9 недель |
| Средний production | 20–50 намерений, RAG по базе знаний, 2–3 интеграции, полный набор защитных механизмов, передача оператору | ~9–16 млн ₽ | 10–16 недель |
| Корпоративный | 100+ намерений, мультитенантность, голосовой канал, соответствие HIPAA / SOC 2, поддержка on-prem | ~16–33 млн ₽ | 16–26 недель |
| Поддержка (любой скоуп) | Переобучение, контур оценки, новые намерения, обновления гардрейлов | ~15–20% от годового бюджета разработки | Постоянно |
Расчёт ROI на конкретном примере
Команда поддержки из 15 человек, около 500 обращений в день. Полная стоимость одного обращения — около 390 ₽. Целевая доля обращений, закрытых без участия оператора, — 42%.
Закрыто без оператора за год: 500 × 250 рабочих дней × 0,42 ≈ 52 500. Экономия на одно обращение (оператор − бот): 390 − 63 = 327 ₽. Годовая экономия: ~17 млн ₽. При среднем бюджете проекта около 12 млн ₽, распределённом на три года, чистый эффект в первый год становится положительным примерно к 11-му месяцу, а к концу третьего года кумулятивный ROI достигает 250–330%. Эти цифры соответствуют данным публичных исследований Forrester TEI; наши проекты обычно показывают чуть лучшие результаты, потому что Agent Engineering сокращает сроки реализации.
Эвристика окупаемости: NLU-бот редко окупается при менее чем ~300 обращениях в день. При меньших объёмах лучше использовать качественный FAQ и отлаженный процесс работы операторов — это выгоднее по общей стоимости и выше по удовлетворённости клиентов (CSAT).
Мини-кейс: NLU в чате живого маркетплейса (Yard Sale Firm)
Не каждая задача NLU связана с поддержкой. На Yard Sale Firm — iOS-маркетплейсе локальных гаражных распродаж — мы внедрили чат между покупателями и продавцами с простым NLU, который обрабатывает каждое сообщение. Цель была не заменить людей, а сделать диалог безопаснее, удобнее и более сфокусированным на сделке.
Ситуация. Ранние пользователи начинали обсуждать цену, а потом отваливались до встречи. Проблемы возникали в трёх местах: не было удобного способа показать детали товара, мошенники пытались получить персональные данные, и контекст диалога терялся, когда покупатель возвращался в переписку через несколько часов.
Что сделали. Слой классического NLU извлекает из каждого сообщения цену, время, локацию и упоминания товара; детектор персональных данных подсвечивает любые попытки выманить телефон или адрес вне защищённого сценария; саммаризатор показывает каждой стороне краткое резюме («Покупатель предложил 3000 ₽ за газонокосилку, готов забрать в субботу»), когда они открывают тред заново. Подтверждение телефона через OTP завершает идентификацию, а сделку доводит сам чат.
Результат. Конверсия из сообщения во встречу заметно выросла, а число жалоб на 1000 тредов — снизилось. Те же NLU-примитивы — извлечение сущностей, маскировка персональных данных, суммаризация — являются основой любого бота поддержки, который мы создаём. Другой продуктовый интерфейс, тот же стек.
Хотите такую же 30-минутную оценку для своей диалоговой поверхности? Обычно после звонка у нас остаётся хотя бы один конкретный гарантированный барьер или исправление задержки, которое можно внедрить уже на следующей неделе.
Хотите честное второе мнение по своему роадмапу бота?
Если вендор уже выбран — проведём стресс-тест архитектуры. Если нет — составим шорт-лист из двух-трёх вариантов, даже если ответ будет «не мы».
Фреймворк решения — выберите подход NLU за пять вопросов
В1. Каков ваш дневной объём обращений? Меньше ~300 в день — не стоит делать бота, хороший FAQ и готовые ответы работают лучше любого кастомного решения. От 300 до 2000 — начинайте с управляемой платформы. Более 2000 — кастомный гибрид окупится за 18 месяцев.
В2. Большинство обращений структурированные или знание-ёмкие? Структурированные (возвраты, бронирование, статусы) — здесь работает классический NLU. Знание-ёмкие («как настроить X») — лучше справляется LLM + RAG. Смешанные — нужен гибридный подход.
В3. Каковы регуляторные ограничения? HIPAA, PCI-DSS, строгий GDPR по местоположению данных → on-prem Rasa или self-hosted LLM. Иначе все управляемые решения подходят.
В4. Есть ли у вас чистые обучающие данные сегодня? Исторические тикеты с разметкой по намерениям или хотя бы структурированная база знаний? Да → можно быстро запустить процесс. Нет → закладывайте 3–6 недель на разметку 500–2000 формулировок на каждое намерение, прежде чем система заработает.
В5. Кто будет владеть этим после запуска? Если ответ — «никто конкретно», остановитесь. NLU-боты деградируют за несколько месяцев без переобучения, разбора эскалаций и обновлений базы знаний. Назначьте хотя бы одного ML- или AI-платформ-инженера на полставки до первого спринта.
Пять подводных камней, которые мы видим почти в каждом NLU-проекте
1. Галлюцинации без гардрейлов. Команда подключает GPT к хелпдеску, пропускает обработку персональных данных и проверку политик — и просыпается со скриншотом в Twitter, где бот предлагает неавторизованные скидки. Лечение: всегда параллельно использовать классический NLU, маскировать данные до формирования промпта, проверять намерение на выходе и устанавливать порог уверенности перед отправкой ответа.
2. Коллизия намерений из-за грязных обучающих данных. Пересечение примеров между «отменить заказ» и «отменить подписку» незаметно снижает точность вдвое. Лечение: еженедельный разбор матрицы ошибок, эталонные датасеты и фолбэки с уточняющими вопросами, когда уверенность модели находится в диапазоне от 0,55 до 0,75.
3. Раздувание контекстного окна. На каждом шаге в промпт загружается вся переписка и десятки документов из базы знаний. Стоимость токенов удваивается каждый месяц. Решение: всё, что старше последних пяти реплик, нужно сокращать до краткого содержания, подтягивать только три самых релевантных документа вместо двадцати, а структурированные запросы держать полностью вне LLM.
4. Нет контура оценки качества. «Небольшая правка» в промпте тихо ломает поиск статуса заказа на две недели. Лечение: эталонный набор из 300–1000 размеченных примеров, прогон на каждый деплой, режим тени для модельных изменений и 10%-ная канарейка перед полной выкаткой.
5. Нет обратной связи от операторов. Бот передаёт запрос оператору, тот решает проблему — и всё. Обратная связь в модель не возвращается. Решение: фиксировать причину каждой эскалации, раз в неделю анализировать такие случаи, раз в месяц дообучать модель на успешных ответах операторов. Эта одна практика обычно увеличивает долю автономных решений на 10–15 процентных пунктов в первые полгода.
KPI: что измерять каждую неделю
KPI качества. F1 по намерениям ≥ 0,88, точность распознавания сущностей ≥ 0,92, частота галлюцинаций < 4% (гибридный подход) или < 5% (LLM-первый), доля фолбэков < 8%. Если какой-либо из этих показателей падает две недели подряд — приостановите добавление новых намерений и сначала исправьте классификатор.
Бизнес-метрики. Доля обращений, закрытых без участия оператора — 75–85%, решение с первого контакта — 60–75%, удовлетворённость клиентов (CSAT) — 4,0–4,5 из 5 по опросам после общения с ботом, снижение стоимости обращения по сравнению с работой оператора — не менее 70%. Эти показатели важны для финансов — выводите их на дашборд по клиентскому опыту, а не в презентации.
KPI надёжности. P95 end-to-end задержка < 2,5 с (текст) / 2,0 с (голос), доступность 99,9%, MTTR инцидента < 2 ч для утечек персональных данных или галлюцинаций, актуальность базы знаний < 14 дней. Относитесь к боту как к платёжной системе: если он не работает, теряется выручка — видите вы это или нет.
Безопасность и соответствие требованиям за 30 секунд
Большинство ботов поддержки работают с персональными данными. Вот краткий список того, о чём действительно стоит думать:
GDPR / CCPA. Право на доступ и удаление данных, ограничение целей обработки, минимизация информации. Храните переписку в соответствии с политикой удержания (30–90 дней для транскриптов диалогов с ботом — стандартный срок), шифруйте данные как при хранении, так и при передаче, а в аналитику отправляйте только анонимизированные логи.
HIPAA. Если в данных хоть раз встречается PHI, модель нужно держать локально или использовать с подписанным BAA (Azure OpenAI и AWS Bedrock поддерживают это; большинство сторонних API для LLM — нет). Ведите аудит-логи всех действий, связанных с PHI.
PCI-ДСС. Никогда не сохраняйте PAN карт в боте. Токенизируйте данные при вводе, отправляйте токен в платёжное хранилище, а оригинальное значение удаляйте сразу. Это архитектурное, а не политическое решение.
SOC 2. Шифрование данных, контроль доступа, реагирование на инциденты, управление изменениями, ежегодный аудит. Если среди потенциальных клиентов есть крупные компании, без этого не обойтись; первый раз получить сертификат занимает около 6–9 месяцев.
Когда NLU-бота поддержки лучше не делать
Боты предсказуемо проваливаются в определённых сценариях. Скажите «нет» — или сузьте скоуп — если видите что-то из этого:
Высокая эмоциональная нагрузка. Отмена услуги, поддержка при утрате близких, жалобы на насилие, кризисные ситуации. Ответ бота вроде «я понимаю, что это, должно быть, неприятно» только усугубляет положение. При признаках сильных эмоций — немедленно передавать разговор человеку.
Юридически или финансово значимые обязательства. Всё, где нельзя ошибиться — лимиты покрытия, условия договора, регулируемые цены — должно проверяться человеком. Пусть бот сортирует, а решает оператор.
Меньше 500 обращений в месяц. Стоимость разработки и поддержки будет выше, чем экономия. Хороший FAQ и шаблонные ответы по email — лучший вариант.
Узкоспециализированные онтологии без данных. Медицинское кодирование, деривативы, авиационные запчасти. Нужны 10 тыс.+ размеченных примеров или специализированная LLM; универсальные боты тут не справляются.
Регулируемые решения с критичным временем. Биржевой трейдинг, сортировка медицинских данных в реальном времени. Бюджет задержек и риск галлюцинаций превращают бота в обузу, а не в актив.
Как реально оценить NLU-бот до запуска
Эталонный датасет. 300–1000 размеченных формулировок пользователей, охватывающих все намерения и граничные случаи. Запуск на каждом деплое. Цель — F1 по намерениям не ниже 0,88.
Shadow-режим. Новая модель получает реальный трафик параллельно с продакшеном, но не отвечает пользователям. Сравните предсказания за 3–5 дней и разберитесь со всеми случаями, где расхождение превышает 5%.
Канареечная выкатка. 10% трафика на новую модель в течение 3–7 дней. Ежедневно отслеживайте CSAT, количество эскалаций и случаи галлюцинаций. При падении любой ключевой метрики на 2% — откатывайтесь.
LLM-ас-джудж с участием людей. Инструменты вроде Ragas, DeepEval и Weights & Biases автоматически оценивают точность ответов RAG, релевантность и токсичность, но делайте около 20 ручных проверок в неделю — это поможет сохранить здравый смысл.
Разбор эскалаций. Каждой эскалации присваивается метка: пробел в намерениях, пробел в базе знаний, ложное срабатывание гардрейла или ошибка оператора. Еженедельный разбор помогает подготовить следующую партию обучающих данных. Именно отсюда после первого месяца поступает большая часть реальных улучшений.
FAQ
Сколько стоит разработка бота поддержки на NLU в 2026?
С Agent Engineering небольшой пилот обходится примерно в 4,5–8,2 млн ₽ за 6–9 недель, средняя production-сборка — 9–16 млн ₽ за 10–16 недель, корпоративное развёртывание с голосом, HIPAA или on-prem — 16–33 млн ₽ за 16–26 недель. Поддержка после запуска — около 15–20% бюджета разработки в год. Традиционные агентства обычно берут на 30–40% больше при той же задаче. Это консервативные диапазоны; реальная стоимость зависит от количества намерений, интеграций и требований к соответствию нормам.
Что выбрать: Rasa, Dialogflow, Amazon Lex или управляемый SaaS вроде Ada?
Как ориентир: если обращений меньше ~500 в день или важна скорость запуска — выбираем Ada или Intercom Fin; от 500 до 2000 обращений в день на AWS — Amazon Lex; тот же объём на GCP — Dialogflow CX; компания на стеке Microsoft — Azure CLU; более 2000 обращений в день, строгие требования по комплаенсу или нестандартная предметная область — Rasa или кастомный гибрид. Конкретный выбор зависит от объёма, используемого облака, требований к комплаенсу и возможностей внутренней команды — обычно 30-минутный скоупинг-звонок помогает принять решение.
Сколько времени нужно, чтобы довести NLU-бота до production-качества?
Закладывайте 2–4 недели на подготовку данных (разметка 500–2000 формулировок по намерениям), затем 1–3 недели — чтобы поднять F1 по намерениям выше 0,88 на эталонном наборе. Реальное качество в продакшене — когда CSAT, доля автономно закрытых обращений и количество галлюцинаций находятся в нормальных пределах — обычно достигается за 8–12 недель после запуска. Это происходит благодаря еженедельному разбору эскалаций и ежемесячному переобучению модели.
Справляются ли NLU-боты с несколькими языками и диалектами?
Да, но не бесплатно. LLM-решения обрабатывают многоязычный ввод «из коробки» — GPT, Claude и Gemini хорошо справляются с основными языками. Классический NLU требует отдельных обучающих данных для каждого языка; Rasa и Dialogflow CX поддерживают мультиязычные модели. На каждый дополнительный язык закладывайте 20–40% дополнительных инженерных усилий. Подробнее — в нашем материале про мультиязычное взаимодействие.
Какое оборудование или инфраструктура нужны?
Для управляемых решений (Dialogflow, Lex, Ada) — никаких требований к инфраструктуре. Для self-hosted классического NLU (Rasa) — скромный Kubernetes-кластер на 4–8 ядер и 16 ГБ оперативной памяти справляется с десятками тысяч диалогов в день. Для self-hosted LLM реально нужны 1–2 GPU класса A100/Н100 на узел, либо аренда GPU-эндпоинтов в AWS, GCP или Azure. Большинство клиентов начинают с управляемых сервисов и переходят на self-host, только когда объём или требования к комплаенсу это делают необходимым.
Чем NLU отличается от чисто LLM-ботов?
Классический NLU дешевле на запрос, быстрее (P95 <200 мс), проще в аудите и не выдаёт вымышленные ответы, но плохо работает за пределами обучающих данных. Чистый LLM гибкий и быстро готов к демонстрации, но дорого масштабируется и опасен без защитных механизмов. Решение для продакшена в 2026 году — гибрид: классический NLU обрабатывает 50–70% трафика с чётко определёнными намерениями, а LLM + RAG — остальное, когда уверенность ниже порога, с обязательными гардрейлами.
Надо ли с первого дня думать про HIPAA, GDPR или SOC 2?
Да, если вы работаете в здравоохранении, финансах, страховании или обслуживаете резидентов ЕС. Это архитектурные решения: где хранятся данные, on-prem или облако, политика хранения, получение согласия, ведение логов аудита. Исправлять соответствие требованиям после запуска в 3–5 раз дороже, чем заложить его с самого начала. Мы подчёркиваем это на скоупинг-звонке, потому что это сразу сужает выбор доступных платформ.
Что если объём запросов слишком мал, чтобы NLU-бот окупился?
Тогда не стройте. Хорошо структурированный FAQ, портал самообслуживания по топ-10 проблем и слой шаблонных ответов в хелпдеске работают лучше плохо прописанного бота и по CSAT, и по общей стоимости. Мы отправляли клиентов с такой рекомендацией обратно к себе — это помогало экономить им шестизначные суммы. Когда объём перевалит за ~300 обращений в день, возвращайтесь — экономика быстро меняется в пользу бота.
Что почитать дальше
Голос и NLU
AI-ассистенты для звонков: практический гид по сторонним API
Когда канал поддержки — телефонная линия, а не чат: как выбирать, интегрировать и доводить до продаж голосовой NLU.
Мультимодальный ИИ
Гид по мультимодальным агентам LiveKit на 2026
Расширить NLU за пределы текста — голос, зрение и агенты в реальном времени в одном production-стеке.
Речь
Распознавание речи в шумных условиях в 2026
Бенчмарки WER и ASR-стек, который реально работает на телефонной линии контакт-центра.
Чат-боты + видео
Интеграция AI-чат-бота с видео: гид по внедрению на 2026
Сочетание диалогового NLU с живым видео для коучинга, онбординга и премиальной поддержки.
Мультиязычность
Мультиязычный перевод в реальном времени
NLU и перевод рядом — инструменты, бюджеты задержек, бенчмарки точности.
Готовы запустить NLU-бота, который действительно окупается?
Полезный бот поддержки на NLU в 2026 — это не просто чат-виджет поверх дерева правил. Это гибридный пайплайн: классический NLU на структурированных запросах, LLM + RAG — на неоднозначных, с гвардрейлами вокруг обоих подходов, полноценным контуром оценки качества и петлёй обратной связи с человеком, которая постоянно улучшает систему. Собранный так, он стабильно закрывает 40–50%+ обращений в поддержку, окупается за год на любой команде, обрабатывающей больше ~300 обращений в день, и делает клиентов довольнее, чем базовый сценарий «только операторы».
Пропущенные гвардреилы, неаккуратные намерения или отсутствие владельца бота после запуска — это сценарии сбоев, которые превращают тот же проект в шестизначный провал. Разница между успехом и провалом почти всегда сводится к тому, насколько серьёзно команда относится к рутинным задачам: разметке, оценке качества, разбору эскалаций и подбору архитектуры под объём.
Давайте оценим ваш NLU-бот поддержки
Тридцать минут, живой инженер, одностраничный план: архитектура, шорт-лист платформ, диапазон стоимости, сроки, чек-лист контрольных точек. Без слайдов.