
Если в 2026 году вы разрабатываете адаптивный продукт для электронного обучения, самый быстрый способ получить измеримый рост результатов учеников — собрать три компонента: модель состояния обучающегося, которая обновляется после каждого взаимодействия, LLM-движок генерации контента с обучением по вашей программе и аналитический инструмент для преподавателей, способный за семь дней выявить учеников из группы риска. Платформы, реализующие все три компонента, как правило, фиксируют рост результатов тестов на 20–30% и в 1,5–2 раза более высокую вовлечённость по сравнению со статическим контентом. Платформы, ограничившиеся «AI-рекомендациями» поверх жёсткого учебного плана, редко влияют на ключевые метрики.
Персонализированное обучение в 2026 году — это адаптивные траектории, генеративный контент и аналитика усвоения материала. Khanmigo, MagicSchool, Century Tech и DreamBox по итогам рандомизированных исследований 2025 года получили одобрение более чем у 70% преподавателей, но в государственных и частных закупках решение по-прежнему зависит от вопросов приватности данных и проверки галлюцинаций.
Почему эту статью пишет Фора Софт
Мы 21 год создаём мультимедийные и AI-продукты, у нас 100% успешных проектов на Upwork, а в команду попадают лишь около 2% кандидатов. Воронка найма в Форсофт — оффер получают примерно 1 из 50 — ориентирована на инженеров, которые умеют рассуждать о моделях состояния обучающегося, о тонкой настройке LLM и о реальных условиях контрактов при работе с данными в образовании.
В сегменте edtech мы создали ALDA — AI-ассистента для обучения, которым сегодня пользуются преподаватели университетов и колледжей США: он генерирует структурированные учебные планы, конспекты лекций и банки заданий на базе моделей класса GPT-4, при этом соблюдая требования конкретных учебных заведений. Ниже — то, что в 2026 году мы реально рекомендуем клиентам, выпускающим адаптивные обучающие продукты. Это не маркетинг, а рабочая методология.
Планируете адаптивный обучающий продукт?
Свяжитесь с нами — мы изучим вашу задачу, поможем выбрать между разработкой с нуля и готовым решением, определим примерный бюджет и предложим несколько вариантов LLM- и eval-стеков, подходящих под вашу учебную программу.
Реальный кейс: ALDA, наш AI-ассистент для обучения
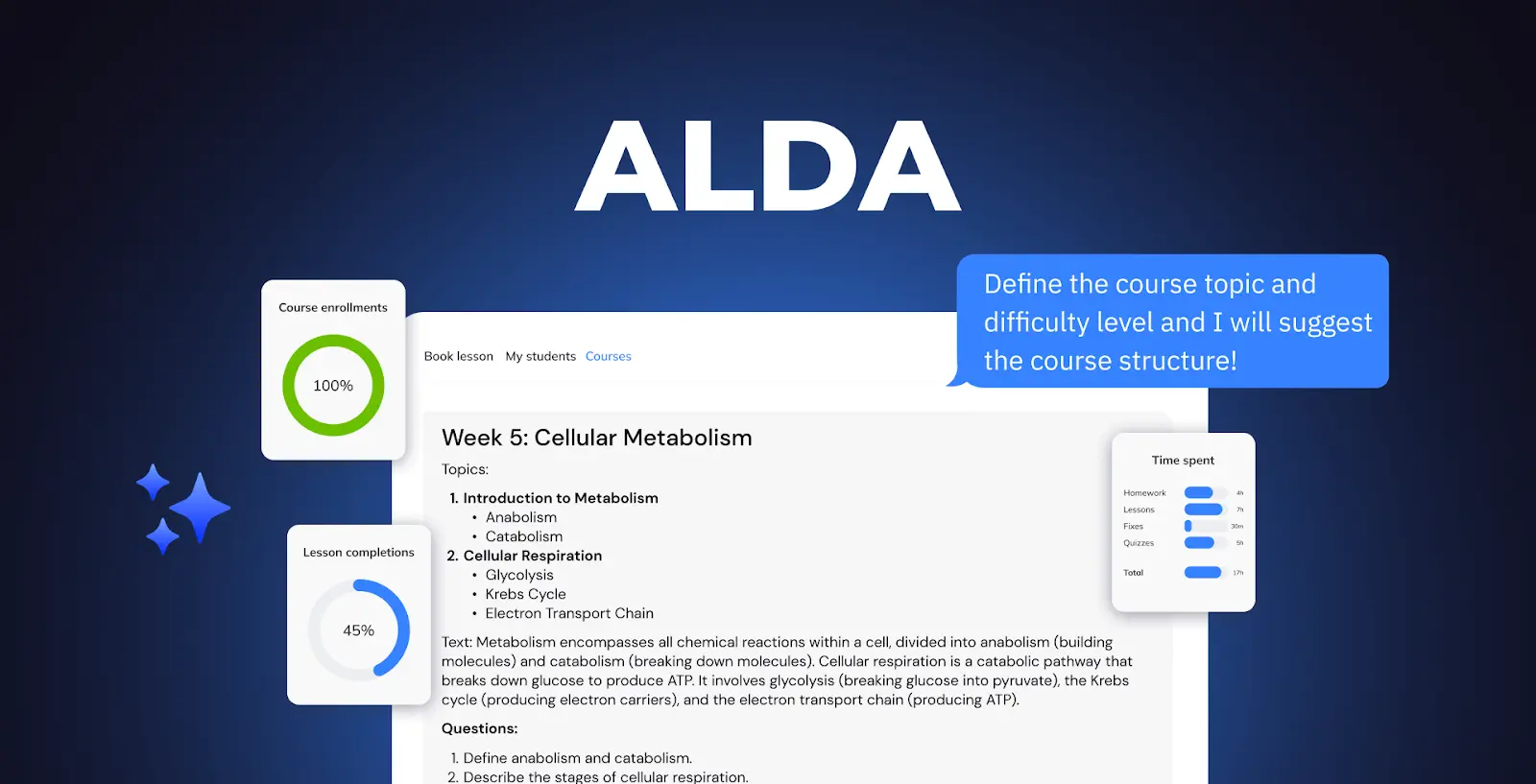
ALDA встраивается в LMS университетов и помогает преподавателям собирать персонализированный учебный контент по короткой подсказке — одной-двум строкам с темой, уровнем аудитории и целевым результатом. Под капотом — Assistants API от OpenAI на модели класса GPT-4, дополненный извлечением данных по утверждённым учебным программам и спискам литературы вуза. Три проектных решения оказались критически важными:
- Сначала грунтинг, потом генерация. Каждый промпт дополняется документами учебной программы вуза с помощью векторного хранилища, чтобы сгенерированные планы соответствовали требованиям конкретной кафедры.
- Структурированный вывод, а не свободный текст. Мы применяем JSON-схему к конспектам лекций (неделя → учебная цель → литература → активности → проверка). Это позволяет LMS отображать материалы единообразно и обеспечивает возможность регресс-тестирования.
- Правки преподавателя возвращаются в модель. Изменения, которые преподаватель вносит в черновик, становятся few-shot-примером для следующего запроса — персонализация накапливается в течение одного семестра.
Паттерн универсальный: персонализируете ли вы под отдельного ученика или под отдельного преподавателя — обучите модель документами вашей предметной области, определите формат вывода, а исправления пусть обучаются на следующем запросе. Всё, что ниже, — это тот же подход, но адаптированный под конечного ученика.
Трёхслойный адаптивный стек в 2026 году
У современной платформы персонализированного обучения три слоя, и все их нужно запустить одновременно. Пропустите хоть один — результаты рухнут:
Модель состояния обучающегося
Живой вектор на каждого ученика: уровень освоения, темп, вовлечённость, предпочитаемая модальность и признаки риска отчисления. Обновляется после каждого взаимодействия.
Контентный движок с грунтингом
LLM с извлечением данных из вашей учебной программы. Генерирует уроки, тесты, подсказки и ветки повторения под профиль ученика — со ссылками на одобренные источники.
Аналитический контур для преподавателя
Дашборды, которые превращают сырые данные о состоянии учеников в упорядоченный список действий: сначала — самые рискованные, с чётким указанием, какое именно заблуждение выявлено.
Слой 1: строим модель состояния обучающегося
В основе любой адаптивной платформы — живое представление о каждом ученике. Считайте его вектором сигналов, который обновляется после каждого осмысленного действия: отвеченный вопрос, просмотренное видео, запрошенная подсказка, время на разделе, повторное чтение фрагмента. Наша эталонная схема:
- Освоение по каждой теме (вероятность от 0 до 1, с еженедельным затуханием) — обновляется с помощью Bayesian Knowledge Tracing или модели в духе DKT.
- Темп (время до освоения относительно когорты, скользящее окно 14 дней).
- Вовлечённость (частота сессий, умноженная на глубину; двухминутный просмотр — это не то же, что 20 минут с выполненными упражнениями).
- Предпочитаемая модальность (визуальная / аудиальная / чтение / кинестетическая — определяется по тому, какие типы материалов помогают быстрее всего освоить материал, а не по результатам самооценки).
- Композитный риск (вероятность отвалиться в течение 14 дней, рассчитывается на основе перечисленного выше).
Имплементационная заметка: не начинайте с обучения собственной модели. В 2026 году базовая конфигурация — это управляемое хранилище признаков (мы используем лёгкую связку Postgres + Redis + векторную БД типа Qdrant или pgvector) плюс открытая реализация DKT, дообученная на ваших первых 10 тысячах сессий. Собственную последовательную модель пишите только тогда, когда у вас уже есть данные, оправдывающие это.
Доказательная база: Mozer et al. (2019) зафиксировали прирост удержания знаний на 16,5% при переходе со статического контента на адаптивный; Luo (2023) — прирост результатов тестов на 25% от полностью адаптивных платформ. Эти цифры достижимы, но при одном условии: состояние ученика обновляется непрерывно, а не только на границах тестов.
Слой 2: контентный движок с грувингом
Это тот слой, который чаще всего усложняют, не давая ему опоры в виде грунтинга. Паттерн, который реально работает в 2026 году:
- Учебная программа как корпус. Загрузите учебники, поурочные планы, утверждённые материалы и критерии оценивания в векторное хранилище. Разбивайте на фрагменты по учебным целям, а не по страницам.
- Ориентируйтесь на состояние ученика, а не только на вопрос. Когда вы создаёте подсказку для отстающего ученика, поисковый запрос учитывает не только сам вопрос, но и текущие вероятности конкретных заблуждений — так подсказка попадает точно в пробел в знаниях, а не просто затрагивает общую тему.
- Ограничивайте вывод. Используйте JSON-режим или tool-calling, чтобы задать структуру: у каждого сгенерированного задания должна быть формулировка, дистракторы, правильный ответ, тег темы, оценка сложности и ссылка на источник. Это делает проверку и работу преподавателя по QA реально выполнимыми.
- Оценка перед каждым деплоем. Прогоняйте эталонный датасет из 200–500 пар «состояние ученика — вопрос» через каждую новую модель или промпт и сравнивайте с размеченным ответником. Команды, которые пропускают этот шаг, незаметно выпускают регрессии в продакшен.
Выбор модели по состоянию на апрель 2026 года: GPT-4.1 и Claude Sonnet 4.5 лучше всего справляются с педагогическим рассуждением и точным выполнением инструкций при структурированном выводе; Llama 3.3 70B — самый надёжный вариант для локального развёртывания у клиентов, которым важна локализация данных. Для продуктов для детей младше 13 лет в формате K–12 рекомендуется использовать собственное хостинг-решение через vLLM — нормативная база для передачи детских данных в крупные облачные платформы пока недостаточно проработана.
Интерактив на базе NLP — интеллектуальные обучающие системы и диалоговые чат-боты — работает поверх того же стека. Системы пошагового тьюторинга показывают результат, сопоставимый с индивидуальным репетиторством (Gomes & Jaques, 2020), а оценивание по рубрике взаимодействия с чат-ботом повышает удержание у большинства учеников (Hmoud et al., 2024). Но эффективность этих решений почти полностью зависит от того, насколько хорошо организован нижний слой — «грунтинг».
Нужен ревью LLM-стека с грунтингом?
Мы запускали RAG-решения на GPT-4, Claude и локальной Llama для сферы образования, здравоохранения и корпоративных клиентов. Привозите свою учебную программу — вместе обсудим архитектурные компромиссы.
Слой 3: замыкаем цикл аналитикой для преподавателя
Аналитический слой — место, где платформы чаще всего проваливаются, и не из-за технических проблем, а из-за плохого дизайна. Дашборд преподавателя с 40 графиками хуже, чем список из пяти учеников, где у каждого выделено одно конкретное заблуждение. Правило дизайна, которым мы пользуемся с клиентами:
- Ранжируйте, а не визуализируйте. Главный экран — это список учеников, отсортированный по уровню риска, с одной фразой, указывающей на конкретный пробел в понимании.
- Вмешательство в один тап. У каждой строки есть действие «отправить повторение», которое запускает сгенерированный AI микроурок, ориентированный на конкретный пробел. Преподаватель утверждает или правит черновик перед отправкой.
- 5–7 дней от сигнала до вмешательства. Если между обнаружением риска и реакцией преподавателя проходит больше недели, ученики, как правило, уже отваливаются. Учитывайте этот срок как продуктовую метрику, а не как системный показатель.
- Еженедельный дайджест по когорте. Письмо в пятницу с тремя ключевыми показателями на класс — трендом освоения, трендом вовлечённости и количеством учеников в риске — по нашему опыту, используется преподавателями чаще, чем любой встроенный дашборд в приложении.
Ouyang et al. (2023) показали, что модели на основе ИИ, предсказывающие результаты обучения, значительно повышают оперативность вмешательств в инженерных программах вузов. В этом исследовании ключевым фактором оказался не уровень точности модели выше базового порога, а реакция преподавателя на сигнал тревоги. Поэтому при разработке систем сначала ориентируйтесь на готовность преподавателя реагировать.
Пять ошибок, которые мы часто видим у клиентов
- Пропуск модели состояния обучающегося. «Пусть GPT сам разберётся, что знает ученик, по диалогу» — работает в демо, но рушится в продакшене. Модель состояния обучающегося — это соглашение между вашим продуктом и вызовами LLM.
- Нет офлайн-стенда для оценки. Выпустите эталонный датасет в первый же день. Без него вы не сможете безопасно обновить модель, переписать промпт или хотя бы доверять своим результатам.
- Недостаточный грунтинг. Команды полагаются на базовые знания LLM вместо собственной учебной программы и потом удивляются, почему методисты отклоняют 30% сгенерированных тестовых заданий. Retrieval-augmented generation для образовательного контента — не опция.
- Приватность как заплатка, а не как проект. FERPA (США) и GDPR (Евросоюз и мир) — это решения по архитектуре: разделение PII, локализация данных, договоры с обработчиками данных, флоу отказа от обработки. Дописать их потом стоит в 3–5 раз дороже, чем заложить в первый день. Для продуктов K-12 соответствие COPPA — забота не релиза, а первого спринта.
- UX для преподавателя как побочная задача. Платформы, которые отлично продумывают интерфейс для учеников, но делают неудобный дашборд для преподавателей, теряют именно преподавателей — а в институциональных продажах именно они и являются покупателями.
Сколько реально стоит построить в 2026 году
Ориентировочные диапазоны по проектам, которые мы оценивали или запускали в этом году:
Адаптивный модуль внутри существующей LMS
13,5–21 млн ₽ разработка, 4–5 месяцев
Модель состояния обучающегося + RAG-движок контента + базовый дашборд преподавателя. Подключается к существующей LMS через LTI или API.
Самостоятельная адаптивная платформа
24–39 млн ₽ разработка, 6–9 месяцев
Все три слоя, а также аутентификация, биллинг, собственная система контента, мобильное приложение и подготовка к SOC 2 / FERPA.
Стоимость инференса на одного активного ученика
3–13 ₽ / MAU / месяц
Расчёт исходит из того, что 80% запросов обрабатывает модель класса GPT-4.1-mini, сложные случаи направляются на GPT-4.1 или Claude Sonnet, а для часто повторяющегося контента настроен агрессивный кэш.
Эти диапазоны рассчитаны на команду из пяти человек (техлид, два бэкенда, ML-инженер, фронтенд) по нашей смешанной ставке. Команды с офшорным уклоном могут уложиться в меньшие цифры; команды, состоящие только из инженеров из США, обойдутся в 2–3 раза дороже. Главное — не сам инжиниринг, а объём учебного контента, который нужно будет нормализовать и разметить, прежде чем RAG-слой заработает. Заложите 15–25% от сметы на инжиниринг дополнительно — на работу с контентом.
Посмотрите вживую: AI-генератор учебной траектории
Виджет ниже — упрощённое клиентское демо того, как модель состояния обучающегося из Слоя 1 управляет рекомендациями контента в Слое 2. Выберите стиль обучения, уровень подготовки, вовлечённость и конкретные сложности — генератор соберёт персональную траекторию и покажет инсайты для преподавателя. Это тот же паттерн, который мы закладываем в боевые платформы.
AI-генератор учебной траектории
Посмотрите, как ИИ адаптирует учебные материалы под данные об ученике
Профиль ученика
Данные об успеваемости
Учебные сложности
Учебная траектория от AI
Инсайты для преподавателя:
Матрица сравнения: разработка с нуля, готовое решение, гибридный подход или open-source для персонализированного обучения на основе ИИ
Быстрая таблица решений по четырём типовым сценариям в 2026 году. Выбирайте строку, соответствующую размеру команды, нормативной нагрузке и целевому сроку запуска — а не ту, что кажется наиболее амбициозной.
| Подход | Для кого подходит | Трудозатраты | Время до получения результата | Риски |
|---|---|---|---|---|
| Готовое SaaS-решение | Команды из менее чем 10 инженеров, типичный сценарий | Низкие (1–2 недели) | 1–2 недели | Зависимость от поставщика, ограничения по настройке |
| Гибрид (SaaS + собственный слой) | Средний бизнес, разнородные сценарии | Средние (1–2 месяца) | 1–3 месяца | Долг по интеграциям, две системы на сопровождении |
| Своя разработка (современный стек) | Крупный бизнес, уникальные данные или регуляторика | Высокие (3–6 месяцев) | 6–12 месяцев | Скорость инжиниринга, удержание сильных специалистов |
| Open-Source на собственных серверах | Чувствительные к стоимости, технически сильные команды | Высокие (2–4 месяца) | 3–6 месяцев | Эксплуатационная нагрузка, патчинг безопасности |
Часто задаваемые вопросы
Как удерживать сгенерированный AI контент в рамках учебных стандартов?
Грунтируйте генерацию векторным хранилищем одобренных учебных документов, навязывайте структурированный вывод (JSON-схема с полем для цитаты) и прогоняйте эталонный датасет с ответником от методиста перед каждым деплоем. Связка извлечения, структурированного вывода и оценки — то, что удерживает результат в рамках государственных стандартов, типового программного ядра или учебных целей конкретного вуза.
Какая архитектура приватности и безопасности нужна для деплоев в США и ЕС?
Для FERPA (K-12 и высшее образование США): разделение справочных данных и учебных записей, заключение договора обработки данных с каждым поставщиком LLM в пайплайне и настройка процесса получения согласия родителей на передачу любых персональных данных за пределы вашей VPC. Для GDPR (ЕС): контроль за локализацией данных (LLM должен находиться в зоне ЕС или работать на ваших серверах), сбор согласия пользователей в явной форме и обеспечение права на удаление данных, которое должно распространяться каскадно на feature-хранилище и векторную базу данных. COPPA требует получения согласия родителей для продуктов, предназначенных для детей младше 13 лет. Учитывайте все эти требования с самого начала — переделка обойдётся в 3–5 раз дороже.
Как стек работает с разными стилями обучения и доступностью?
Предпочитаемая модальность определяется на основе поведения — какие типы материалов позволяют ученику быстрее всего осваивать материал, — а не по результатам самооценки. Доступность (соответствие WCAG 2.2 AA, совместимость со скринридерами, автоматическая генерация субтитров и расшифровок, типографика для людей с дислексией) должна быть заложена в шаблоны контентного движка, а не добавлена позже. Мы рекомендуем включать требования к доступности как ограничение при генерации контента — наряду с вектором состояния ученика.
Можно ли интегрироваться с существующими LMS (Canvas, Moodle, Schoology, Google Classroom)?
Да — LTI 1.3 это стандартный способ интеграции для Canvas, Moodle, Schoology, Blackboard и большинства систем управления обучением. У Google Classroom и Microsoft Teams for Education свои API. Обычно мы сначала выпускаем адаптивный модуль как инструмент LTI 1.3, а потом постепенно добавляем более глубокие интеграции — передачу оценок, синхронизацию списка студентов, deep linking — по запросам клиентов.
Каков реалистичный бюджет на адаптивный модуль обучения в 2026 году?
Подключаемый адаптивный модуль обойдётся в 13,5–21 млн ₽ за 4–5 месяцев; самостоятельная платформа со всеми тремя слоями, аутентификацией, биллингом и подготовкой к SOC 2 / FERPA — 24–39 млн ₽ за 6–9 месяцев. Инференс стоит 3–13 ₽ на активного ученика в месяц — зависит от набора моделей и степени кэширования. К общей смете добавьте 15–25% на инженерную работу с учебным контентом — именно этот этап чаще всего недооценивают.
Какую LLM выбрать — GPT-4.1, Claude Sonnet 4.5 или self-hosted Llama?
На апрель 2026 года GPT-4.1 и Claude Sonnet 4.5 — два лидера по способности рассуждать в образовательных задачах и по качеству структурированного вывода. Claude немного опережает по работе с длинными текстами (что полезно при анализе целых учебников); GPT-4.1 лучше следует инструкциям. Для продуктов K-12, ориентированных на детей младше 13 лет, и при любых требованиях к локализации данных в ЕС реалистичный вариант развёртывания на собственном оборудовании — это self-hosted Llama 3.3 70B через vLLM. Обычно мы советуем использовать две модели: дешёвую и быструю (GPT-4.1-mini / Haiku 4.5) для 80% запросов и флагманскую — для сложных 20%.
Подведём итог
Персонализированное обучение в 2026 году — это трёхслойная система: живая модель состояния обучающегося, LLM-движок генерации контента с грунтингом и ранжированный аналитический контур для преподавателя. Если реализованы все три слоя — типичные приросты результатов составляют 20–30%, а вовлечённость повышается в 1,5–2 раза. Пропустите хоть один — получите продукт, который отлично выглядит на демонстрации, но проваливается в реальной эксплуатации. Команды, которые выигрывают в этом сегменте, непропорционально много времени тратят на рутинные задачи: нормализацию учебной программы, офлайн-стенд оценки и архитектуру приватности — с самого первого дня.
Готовы оценить разработку адаптивной платформы обучения?
Свяжитесь с нами — мы разработаем трёхслойную архитектуру под вашу учебную программу, выявим регуляторные ограничения на вашем рынке и определим бюджетный диапазон ещё до начала формирования команды.
Читайте дальше
Источники
Aggarwal, D., Sharma, D., & Saxena, A. (2023). Exploring the role of artificial intelligence for augmentation of adaptable sustainable education. Asian Journal of Advanced Research and Reports, 17(11), 179–184.
Gomes, J., & Jaques, P. (2020). A data-driven approach for the identification of misconceptions in step-based tutoring systems. Brazilian Symposium on Computers in Education, 1122–1131.
Hmoud, M., Swaity, H., & Anjass, E., et al. (2024). Rubric development and validation for assessing tasks' solving via AI chatbots. Electronic Journal of E-Learning, 22(6), 1–17.
Luo, Q. (2023). The influence of AI-powered adaptive learning platforms on student performance. Journal of Education, 6(3), 1–12.
Mozer, M., Wiseheart, M., & Novikoff, T. (2019). Artificial intelligence to support human instruction. PNAS, 116(10), 3953–3955.
Onesi-Ozigagun, O., Ololade, Y., & Eyo-Udo, N., et al. (2024). Revolutionizing education through AI. IJARSS, 6(4), 589–607.
Ouyang, F., Wu, M., & Zheng, L., et al. (2023). Integration of AI performance prediction and learning analytics. IJETHE, 20(1).
Sitthiworachart, J., Joy, M., & Mason, J. (2021). Blended learning activities in an e-business course. Education Sciences, 11(12), 763.
Когда подключать адаптивный контент: если у вас более 1 000 активных учеников и есть данные об их результатах. Ниже этой планки сигнал для персонализации слишком слабый.
Когда отказаться от генерации без преподавателя: если аудитория — K-12 или регулируемая сфера. Преподаватель в процессе — это гарантия доверия.
Приоритет формата: видео и интерактивные симуляции всегда работают лучше текста. Удержание информации растёт в три раза — это типичный результат.
Типовая ошибка: игнорирование приватности. FERPA, COPPA и GDPR-совместимость должны быть заложены в архитектуру с самого начала, а не добавлены потом.