
Главное
• Оценка разработки ПО — это инструмент принятия решений, а не дедлайн. Её задача — найти самый дешёвый путь к продукту, который можно продавать, а не предсказать будущее с точностью до второго знака.
• Точность покупается фиксацией скоупа, а не часами. Конус неопределённости (Cone of Uncertainty) показывает: ранние оценки совершенно законно могут попасть в диапазон от 0,25× до 4× — разброс в 16×, который сужается только по мере подписания решений.
• Используйте три метода, а не один. Аналоговый — для питча, bottom-up плюс трёхточечный PERT — для результатов discovery, Planning Poker — на каждый спринт. Любое одно число от любого одного метода неверно.
• Лучший контракт — оплачиваемый discovery, затем фиксированная разработка. Time-and-materials на первые 2–4 недели, чтобы сжать конус, фикс-прайс с дисциплиной change-order на остальное. Чистый фикс-прайс на пустой странице — это путь в те 52,7% проектов, что выходят за бюджет.
• Agent Engineering меняет математику в 2026 году. Грамотно используемые AI-агенты для кода сокращают чистое время разработки на 25–40% на greenfield-фичах — но только если в смете одновременно вырастут строки на ревью, QA и сеньорный надзор. Урежете их — и количество дефектов вырастет в 1,7×.
Почему Фора Софт написала это руководство
С 2005 года Фора Софт выпустила более 625 программных продуктов — в основном это платформы для видео реального времени, AI и аудио, где один неверный выбор SDK способен удвоить смету. За два десятилетия скоупинг-звонков мы писали, подписывали и сдавали оценки всех мыслимых форм: питчи на салфетке для основателей, 40-страничные Master Service Agreement для корпораций из списка Fortune, спринтовые burndown-планы, контракты на результат и всё, что между ними. Это руководство сжимает то, что реально выдерживает проверку подписанным заказом.
Мы запускаем discovery перед каждой фиксированной сметой, отслеживаем собственный разрыв между оценкой и фактом по каждому проекту и знаем, какие строки подрядчики систематически забывают — потому что когда-то забывали и мы. Если хотите получить второе мнение по уже имеющейся смете или чистый discovery вместо числа, которому вы не доверяете, посмотрите наш сервис планирования и аналитики или то, как Фора Софт ведёт разработку от начала до конца.
Получили смету от другого подрядчика и не вполне ей доверяете?
Пришлите нам PDF — мы отметим пропущенные строки, оспорим допущения и вернём второе мнение в течение 48 часов. Без обязательств и презентаций.
Что такое оценка разработки ПО (и чем она не является)
Оценка разработки ПО — это дисциплина прогнозирования того, сколько времени, денег и риска несёт проект, чтобы заказчик мог принимать решения. Это полное определение. Это не обещание, не дедлайн и не обязательство. Стив Макконнелл, написавший канонический труд по теме, проводит границу чётко: оценка — это вероятностный диапазон, цель — это бизнес-задача, а обязательство — это обещание попасть в цель. Подрядчики, которые сводят эти три понятия в одно число, не занимаются оценкой — они выставляют цену.
Для основателя или CTO, выбирающего партнёра, практический вопрос уже: «Что самое дешёвое, что я могу сделать прямо сейчас, чтобы перевести свою оценку из диапазона, на который нельзя опереться, в диапазон, на который можно?» Остаток этого руководства отвечает на этот вопрос, стадия за стадией.
Почему половина проектов до сих пор выходит за рамки бюджета
Цифры почти не сдвинулись за тридцать лет. CHAOS-отчёт Standish Group из года в год показывает: лишь около 31% проектов сдаются в срок и в бюджет, 52,7% превышают бюджет в среднем на 189%, а около 19% вовсе отменяются. Отчёт PMI Pulse of the Profession 2025 даёт глобальный показатель попадания в бюджет в районе 50%. CISQ оценил годовую стоимость низкого качества ПО только в США примерно в 180 трлн ₽, а технический долг — ещё примерно в 114 трлн ₽.
Основные причины удручающе одинаковы во всех исследованиях: scope creep (расползание скоупа — затрагивает 52–70% проектов), слабый сбор требований (упоминается в ~39% провалов), пропущенные нефункциональные работы (безопасность, доступность, производительность, девопс) и якорение — когда число подбирают под бюджет, а не под скоуп. Почти все они живут выше по течению от кода.
Конус неопределённости — у вашей оценки есть законный разброс
Барри Бём первым нарисовал, а Макконнелл популяризировал, конус неопределённости (Cone of Uncertainty): наблюдение, что вариативность оценки зависит от того, сколько уже решено, а не от того, сколько обсуждено. На стадии «первоначальной концепции» — первого 30-минутного звонка — строгая оценка совершенно законно может попасть в диапазон от 0,25× до 4× от итогового факта. Это разброс в 16×. Притворяться, что это не так, — профнепригодность.
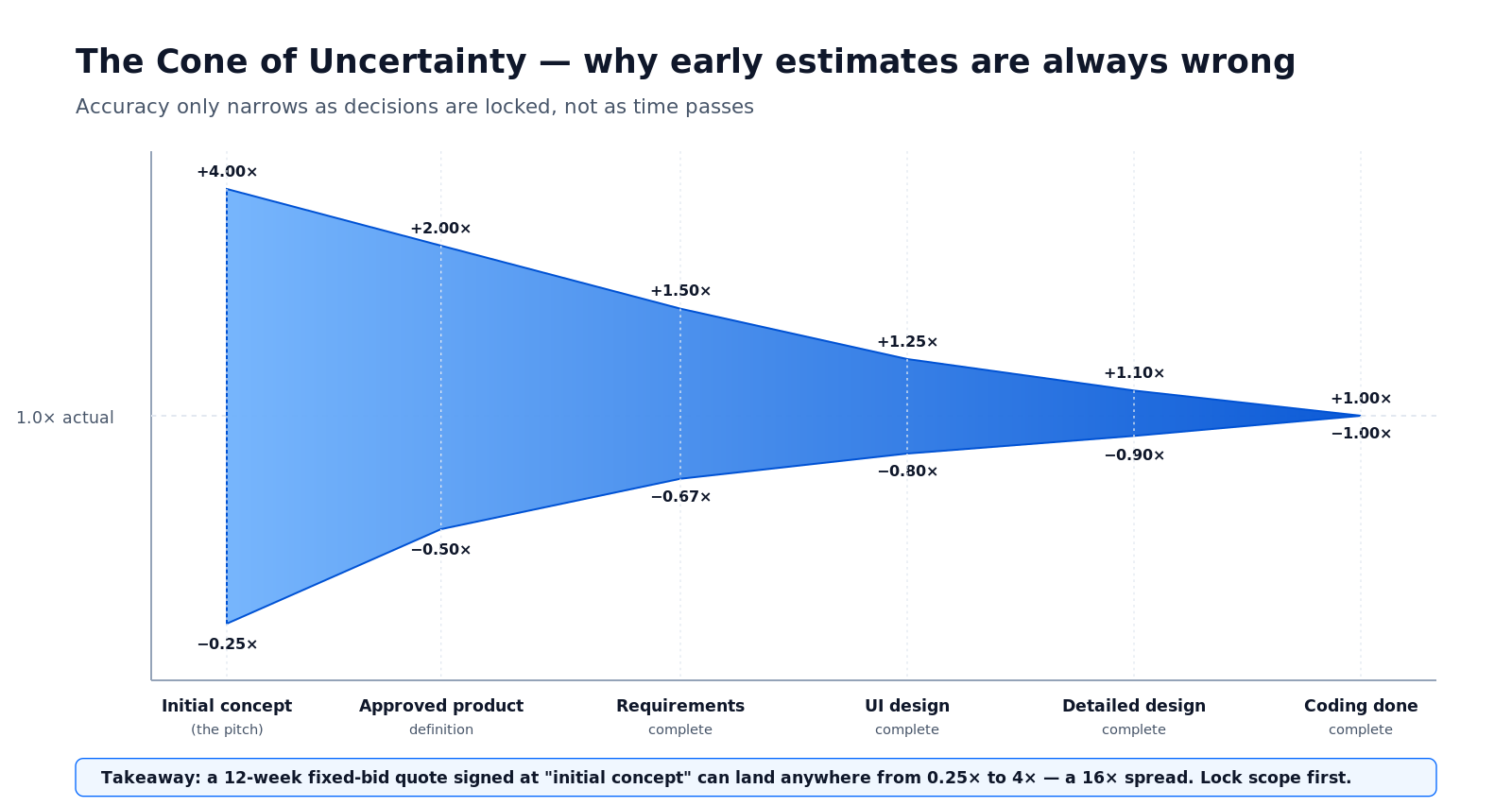
Рисунок 1 — Конус неопределённости. Каждая отметка по оси X — это решение, а не дата. Конус закрывается только тогда, когда решения подписаны.
Эту диаграмму опасно недочитывают с двух сторон. Основатели иногда думают, что конус сужается со временем — это не так. Команда, которая четыре недели «скоупит» без письменной карты пользовательских историй, NFR и критериев приёмки, всё ещё находится в диапазоне ±4×. Подрядчики иногда продают фикс-прайс на стадии «питча» и поглощают разброс, накручивая 2–3×. Либо накрутка верна и заказчик переплачивает, либо она неверна и проект умирает в середине разработки.
Вспомните про конус, когда: подрядчик называет одно жёсткое число за 6-месячную разработку после одного звонка по discovery. Спросите, на какой стадии конуса он находится — и почему.
Три типа оценок — подбирайте тип под решение, которое принимаете
Не каждая оценка требует одинаковой строгости. Потратить четыре недели на высокоточную оценку для решения стоимостью 2,2 млн ₽ — пустая трата. PMI Practice Standard делит оценки по точности, а ниже мы сопоставляем их с решениями заказчика.
| Тип | Точность | Трудоёмкость | Использовать для | Не использовать для |
|---|---|---|---|---|
| Грубый порядок величины (ROM) | −25% до +75% | 30–90 мин | Решения, стоит ли идея полноценного discovery | Подписания фиксированного контракта |
| Бюджетная | −15% до +25% | 1–2 недели | Одобрения советом, бюджетной строки CFO, решения go/no-go | Обязательств по календарной дате запуска |
| Определённая | −5% до +10% | 3–6 недель оплачиваемого discovery | Фикс-прайса, обязательства по дате запуска | Проверки гипотезы «стоит ли вообще строить» |
| Спринтовая | ±10% на спринт (после 3–4 спринтов) | 2–4 часа на спринт | Планирования спринта, прогноза по следующему релизу | Долгосрочных коммерческих обязательств |
Девять из десяти основателей, с которыми мы встречаемся, просят определённую оценку на стадии, которая поддерживает только бюджетную. Решение — не больше встреч, а оплачиваемый discovery, который сжимает конус достаточно, чтобы заработать дополнительную точность.
Шесть методов оценки, которые до сих пор использует серьёзный подрядчик
Это те методы, к которым мы реально обращаемся внутри Фора Софт, со шрамами, объясняющими почему. Считайте это набором инструментов, а не меню — на одну оценку стоит брать минимум два метода и сравнивать.
Аналоговый (экспертное суждение по прошлым проектам)
Поднимаете завершённый проект, архитектурно похожий на текущий, берёте его фактические показатели, корректируете на размер, стек и опыт команды, публикуете результат. Дёшево, быстро, честно по отношению к своим допущениям и удивительно точно, когда есть исторические данные. Проваливается, когда у нового проекта есть по-настоящему уникальный компонент (первая интеграция с LLM, первое FDA-устройство), для которого в истории нет аналогов. Хорошо работает на стадии питча или концепции.
Top-down (декомпозиция от проекта к эпикам)
Разбиваете проект на 6–10 эпиков, назначаете каждому диапазон по аналоговой истории, суммируете. Прекрасно для взгляда CFO. Слабо для планирования спринтов, потому что прячет детали из 300 пользовательских историй, которые и определяют реальное сгорание бюджета. Хорошо как первый проход в ходе discovery — для проверки bottom-up.
Bottom-up / Work Breakdown Structure
Декомпозируете до задач по 4–16 инженерных часов, оцениваете каждую, прибавляете накладные на PM, QA и DevOps. Самый точный метод, когда у вас уже есть полная карта пользовательских историй, критерии приёмки и архитектура. Дорогой в производстве — мы берём за него деньги в рамках discovery — и катастрофически ошибается, если на вход подаёте неполный скоуп. Именно на нём строится определённая оценка.
Параметрический (COCOMO II, Function Points)
Скармливаете модели (размер в KLOC или function points, факторы сложности, опыт команды) и получаете математический результат. Полезен как тай-брейкер, когда top-down и bottom-up расходятся. Оговорка: оригинальная калибровка COCOMO II относится к водопадным проектам 1990-х; академические исследования показывают, что некалиброванный COCOMO может давать ошибку ~100% на современных облачных, микросервисных и AI-ассистированных стеках. Если подрядчик ссылается на COCOMO, спросите, когда он в последний раз калибровал модель на собственных фактах.
Planning Poker (консенсус в story points)
Классика Майка Кона: вся инженерная команда показывает карточки модифицированного Фибоначчи (1, 2, 3, 5, 8, 13, 20, 40, 100) для каждой истории; те, кто на краях, объясняют, команда переголосовывает, приходит к консенсусу. Ловит скрытую сложность, которую индивидуальные оценки всегда упускают, и формирует у команды ответственность за план. Через 3–4 спринта скорость стабилизируется, и те же карточки конвертируются в надёжные дни. Не используйте на стадии питча — команды у вас ещё нет.
Трёхточечный PERT + Монте-Карло
Для каждой строки bottom-up фиксируем три числа: оптимистичное (O), наиболее вероятное (M), пессимистичное (P). Ожидаемая длительность — (O + 4M + P) / 6; стандартное отклонение — (P − O) / 6. Даёт честные интервалы доверия вместо точечных чисел с ложной точностью. Монте-Карло прогоняет 10 000+ смоделированных расписаний по этим распределениям и выдаёт кривую — например, «50% шанс уложиться в 14 недель, 90% шанс — в 18». Эта кривая — то, чем вы торгуетесь по пункту контракта о дате запуска.
Какой метод подходит для какой стадии — матрица соответствия
Матрица ниже сопоставляет каждый метод с каждой стадией принятия решения. Чем темнее ячейка, тем сильнее соответствие. Используйте минимум два метода на одну оценку — если они расходятся больше чем в 1,5 раза, ваш скоуп пока недостаточно зафиксирован.
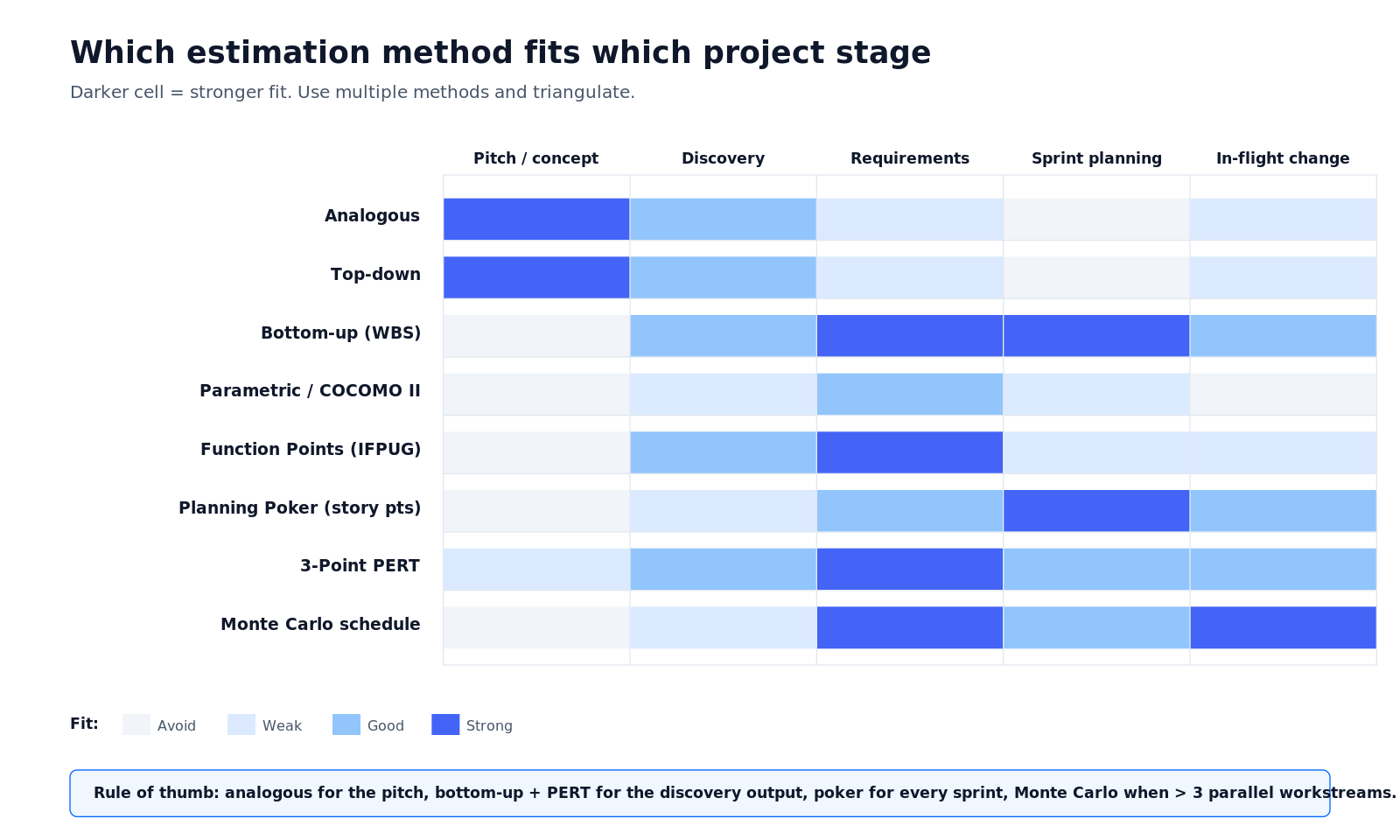
Рисунок 2 — Какой метод оценки подходит для какой стадии. Темнее = сильнее соответствие.
Как этап discovery сжимает оценку, шаг за шагом
Большая часть превышений бюджета в данных Standish растёт из одного паттерна: фикс-прайс подписан на стадии 1 конуса, а скоуп обнаруживается на стадии 4. Наш ответ — поэтапный discovery, где каждый артефакт покупает более узкую оценку.
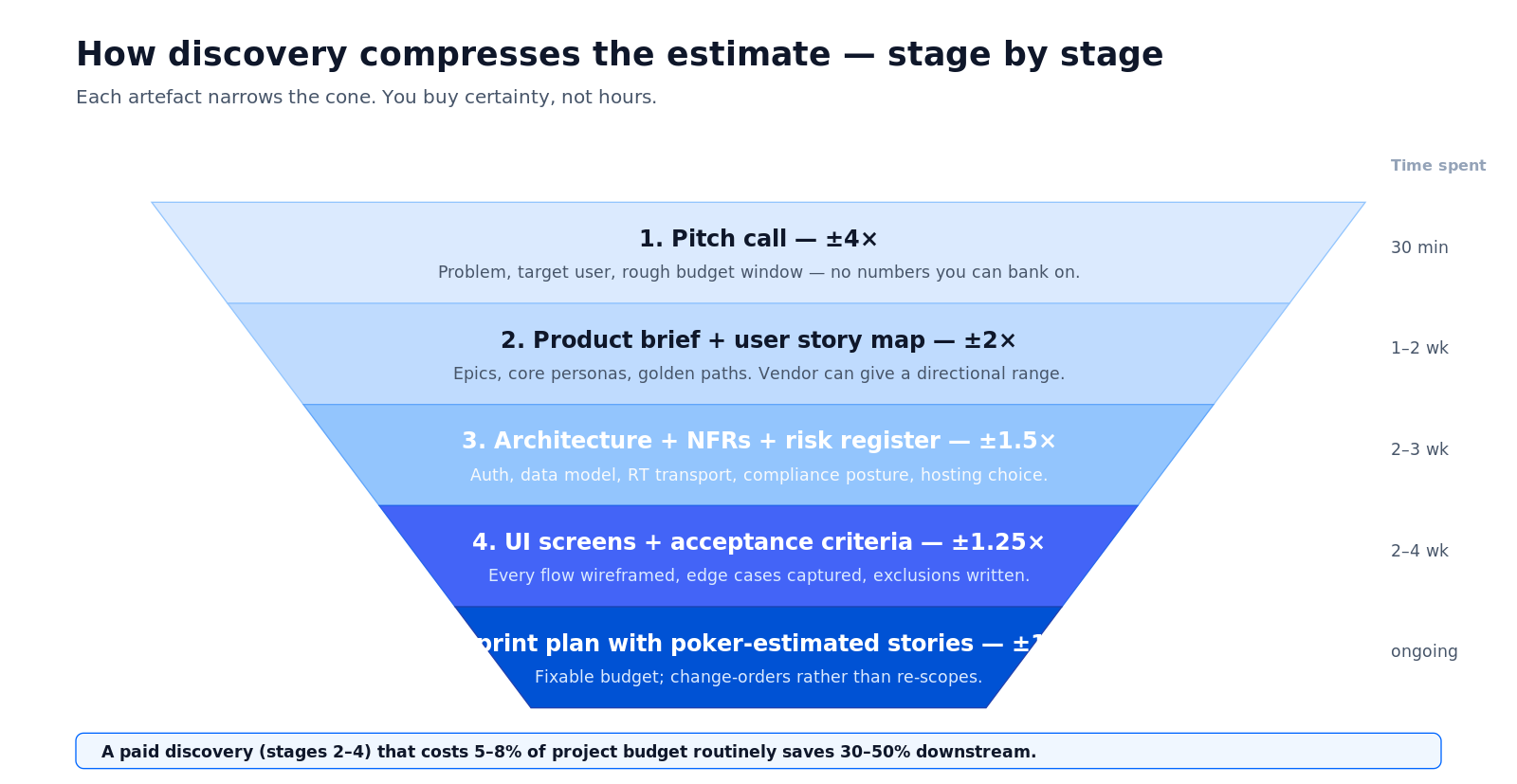
Рисунок 3 — Воронка discovery. Каждый артефакт сжимает конус прежде, чем вы подпишете контракт на разработку.
Стадии 2–4 обычно стоят 5–8% от общего бюджета — и по нашей собственной истории контрактов сэкономили 30–50% последующей разработки за счёт того, что плохие допущения были убиты до написания кода. О том, как мы обычно скоупим стадию 2, можно почитать в материале о том, почему запуск с урезанным функционалом выигрывает у разработки полного скоупа.
Что должна включать полная оценка (и что упускают 80% смет)
Большая часть заниженных смет случается потому, что строки на функциональные фичи правильные, а вокруг них — нет. Ниже — полный чек-лист, по которому работаем внутри компании; попросите любого подрядчика показать как минимум 12 из этих пунктов явно.
| Строка | Типичная доля | Часто отсутствует |
|---|---|---|
| Разработка фич (happy path) | 35–45% | — |
| Крайние случаи, обработка ошибок, пустые состояния | 10–15% | Почти всегда |
| QA (ручное + автоматизированное + регрессионное) | 15–25% | Часто занижено |
| UI / UX дизайн и итерации | 8–12% | Учитывают только первую версию экранов |
| DevOps, CI/CD, настройка инфраструктуры | 5–10% | Часто |
| Безопасность / комплаенс (SOC2, HIPAA, GDPR) | 5–15% | Почти всегда |
| Доступность (WCAG 2.2 AA) | 3–6% | Обычно |
| Производительность / нагрузочное тестирование | 2–5% | Обычно |
| PM, архитектор, тимлид и надзор | 10–15% | Спрятано внутри строки «команда» |
| Буфер на риски / контингенция | 10–20% | Часто замаскировано как «буфер» |
Если смета в сумме равна примерно стоимости часов на разработку фич, подрядчик оценил 35–45% реальной стоимости и либо планирует поглотить остальное, либо — чаще — добрать через change-order позже.
Модели контрактов: кто отвечает за риск, если оценка ошибочна
Оценка кормит контракт, а контракт распределяет риск. Пять форм ниже — те, что реально встречаются в наших MSA в 2026 году.
| Модель | Лучше всего для | Предсказуемость цены | Гибкость | Кто несёт риск оценки |
|---|---|---|---|---|
| Фикс-прайс | Зафиксированный, проверенный после discovery скоуп | Высокая | Низкая | Подрядчик (за счёт накрутки) |
| Time & materials (T&M) | Исследования, быстро меняющийся скоуп | Низкая | Высокая | Заказчик |
| T&M с потолком | Discovery, прототипные спринты | Средняя | Высокая | Общий |
| Discovery T&M + фиксированная разработка | Greenfield-продукт — наш дефолт | Средняя, затем высокая | Высокая, затем средняя | Общий |
| На результат (outcome-based) | Измеримые KPI, сильный baseline | Переменная | Средняя | Общий (с апсайдом для подрядчика) |
Берите «discovery T&M, затем фиксированная разработка», когда: вы основатель и строите новый продукт с нуля. Это единственная форма, в которой оценка успевает заработать свою точность до того, как вы её подпишете.
Параллельный взгляд на механику найма команды — в материале о том, как мы отбираем разработчиков под проект.
Нужен оплачиваемый discovery, который даст определённую оценку?
Двухнедельный спринт по фиксированной цене. На выходе — подписанная карта пользовательских историй, архитектура, реестр рисков и оценка разработки с разбросом ±10%, с которой можно идти к совету директоров.
Agent Engineering в 2026 году — что это реально меняет в вашей смете
Agentic-инструменты для кодинга сдвинули кривую стоимости, но неравномерно. Заголовочные цифры обнадёживают: отчёт Anthropic Agentic Coding Trends 2026 оценивает проникновение AI-инструментов примерно в 90% работающих разработчиков и указывает, что ~41% нового кода написано AI. Наша собственная внутренняя телеметрия (по проектам в области видео реального времени, AI и edtech) показывает сокращение часов на разработку фич на 25–40% в greenfield-работе, где предметная область хорошо представлена в обучающих данных.
Загвоздка дальше по конвейеру. Исследование производительности GitHub и State of AI 2025 от McKinsey отмечают один и тот же паттерн: AI-сгенерированный код несёт ~1,7× больше дефектов на ревью pull request, если усилия на ревью остаются прежними. Сеньорные инженеры извлекают примерно в 5 раз больше пользы, чем джуниоры. В переводе на смету это значит:
1. Разработка фич сжимается на ~25–40% на greenfield. Привычные стеки (CRUD, API-обвязка, тестовые каркасы, шаблонный код) получают максимальный буст. Кастомные видео-пайплайны, доменно-специфичный ML, интеграции SDK и работа на стыке с железом — почти не сдвигаются.
2. QA и ревью кода вырастают на ~15–25%. Больше кода в час — больше ревью в час. Урезание ревью — самый быстрый способ выпустить продукт с дефектностью в 1,7×.
3. Состав команды смещается к сеньорам. Связка сеньор-лид / мидл / джуниор, которая имела коммерческий смысл в 2022 году (примерно 1:2:2), сегодня лучше окупается в пропорции ~1:2:1, с одним-двумя сеньорными ревьюерами на под.
4. Чистый эффект на типичной 12-недельной разработке. Наши данные по разрыву оценки и факта говорят о чистом сокращении общей стоимости на 15–25%, а не на 40%, как рисуют маркетинговые презентации. Любой подрядчик, который называет плоское «AI делает это на 50% дешевле» без корректировки строк на ревью, надувает свою маржу.
Реальный случай поставки с цифрами есть в материале о том, как AI сократил время разработки на 40% на платформе видеостриминга в более чем 1 млн строк кода — эти 40% считаются на чистых часах кодинга, а не на всём проекте.
Мини-кейс — как discovery спас оценку в 31 млн ₽ от провала
Ситуация. Американский edtech-основатель пришёл к нам с фиксированной сметой от другого подрядчика: 31 млн ₽ за платформу для онлайн-репетиторства с живым видео, общей доской, AI-генерацией планов уроков и LTI-интеграцией с дюжиной LMS-продуктов. Смета состояла из 26 страниц списков фич — без NFR, без WBS, без реестра рисков. Разработка планировалась на 14 недель.
План на 12 недель. Мы запустили 3-недельный оплачиваемый discovery (~1,3 млн ₽). На выходе: карта пользовательских историй (147 историй), реестр рисков на 31 запись, эталонная архитектура, NFR-бриф с учётом FERPA и SOC 2, а также bottom-up + трёхточечный PERT с расписанием по Монте-Карло. Два решения, которые исходная смета не учла: (а) LTI-интеграции нужно было покрывать в 12 вариантах LMS, а не в одном, и (б) фича AI-генерации планов уроков требовала human-in-the-loop ревью для округов под FERPA.
Итог. Реальный скоуп с разбросом ±10% обошёлся в 40 млн ₽ / 18 недель — на 28% дороже и на 29% дольше исходной сметы. Основатель вернулся к первому подрядчику, и тот в итоге признал, что дельту всё равно бы добрал через change-order на третьем-четвёртом месяце. Клиент подписал нашу фиксированную разработку, сдал проект по плану на 18 недель, потратил 94% бюджета и избежал пересогласования в середине проекта, которое убивает большинство edtech-раундов. Похожий edtech-кейс с более чем 500 000 студентов — разработка ALDA, генератора AI-курсов.
Ориентировочная модель стоимости — типичные диапазоны 2026 года
Это диапазоны, которые мы видим в собственной воронке, а не бенчмарки. Используйте их как аналоговую референс-точку, а не как смету. Любой, кто называет точное число без discovery, гадает.
| Форма продукта | Диапазон MVP | Сроки | Ключевой риск |
|---|---|---|---|
| Внутренний инструмент / B2B-дашборд | 2,6–6,7 млн ₽ | 6–12 нед. | Интеграции с легаси-системами |
| Потребительское мобильное (1 платформа) | 4,5–10 млн ₽ | 8–16 нед. | Итерации дизайна, ревью сторов |
| SaaS с подпиской и админкой | 6,7–16,5 млн ₽ | 12–24 нед. | Платежи, роли, мультитенантность |
| Видео реального времени / телемедицина | 9,7–24 млн ₽ | 16–28 нед. | SFU / транспорт, комплаенс |
| AI-продукт (LLM + RAG) | 6,7–19,5 млн ₽ | 10–20 нед. | Eval-обвязка, стоимость инференса |
| Edtech-платформа с живыми сессиями | 13,5–36 млн ₽ | 20–32 нед. | FERPA, LMS-интеграции, видео |
Подробные разборы — в нашем гайде по стоимости мобильных приложений 2026 и в CTO-гайде по ценам на видеостриминг. Под большинство self-hosted нагрузок мы используем Hetzner серии AX и DigitalOcean и в каждой смете явно держим допущения по cloud egress.
Решение за пять вопросов — как принять смету подрядчика
Прежде чем подписать любую смету, пройдите по пяти вопросам ниже. Если подрядчик не может ответить на все пять письменно в течение дня, смета пока не заслуживает вашей подписи.
В1. На какой стадии конуса неопределённости вы выставляете число? Ожидаемый ответ: явная стадия («требования собраны, ±1,5×») и артефакты, которые до неё довели (WBS, карта историй, архитектура).
В2. Каковы топ-5 допущений и что происходит с числом, если каждое из них переворачивается? Ожидаемый ответ: список с дельтами в часах по каждому допущению. Нет допущений — нет оценки.
В3. Что явно не входит в скоуп? Ожидаемый ответ: короткий список исключений. «Не исключено ничего» — красный флаг.
В4. Какой интервал доверия — 50%, 80%, 90%? Ожидаемый ответ: пара P50 / P80 из PERT или Монте-Карло. Если число одно, это P50 со встроенной невидимой неопределённостью.
В5. Как устроен процесс change-order и как отслеживается velocity? Ожидаемый ответ: письменный SLA по change-order, спринтовый план velocity и постоянный еженедельный ритм переоценки. Молчаливое отслеживание velocity — это способ обнаружить перерасход на четвёртом месяце.
Подводные камни — пять способов, которыми оценка тихо губит проекты
1. Якорение на бюджет. Основатель говорит: «у нас 9 млн ₽». Подрядчик реверс-инжинирит скоуп, который суммируется в 9 млн ₽. Проект сдаётся за 14 млн ₽. Ошибка — разговорная: не называйте число, пока не обнаружен скоуп. Озвучьте решение («готовы инвестировать 9 млн ₽ в MVP, 15 млн ₽ всего за 18 месяцев») и попросите подрядчика подогнать скоуп под этот конверт.
2. Накрутка без её называния. Скрытый буфер («я просто удвою всё») непроверяем. Если проект сдан раньше срока — буфер становится прибылью подрядчика. Если есть перерасход — запас уже потрачен. Всегда просите явные строки на резервы.
3. Игнорирование нефункциональных требований. Усиление аутентификации, логирование, мониторинг, доступность, ревью безопасности, готовность к GDPR / HIPAA, нагрузочные тесты, наблюдаемость, CI/CD — ничего из этого нет в списке фич, но всё это стоит недель. Эти пункты заслуживают именованных строк.
4. Оптимистическая ошибка на интеграциях. «Там есть SDK» почти никогда не вся история. Платёжные провайдеры, SSO-вендоры, LMS-системы, IoT-шлюзы и SIP-стеки добавляют по 3–5 недель, которых не видно в документации SDK. Подробнее — в материале о том, что не стоит делать при урезании бюджета.
5. Оценить один раз и больше не пересматривать. Оценка — это гипотеза. После второго спринта у вас уже есть данные. Если подрядчик не публикует обновлённый прогноз против факта каждый спринт, конус никогда не закроется. Молчаливый дрейф оценки — крупнейший предиктор отмены проекта.
KPI — как измерять качество оценок
Качественные KPI. Коэффициент точности оценки (факт / оценка) на спринт. Цель: 0,9–1,1 после третьего спринта. Что-либо за пределами 0,7–1,3 два спринта подряд — тревога: расползание скоупа или недооценка.
Бизнес-KPI. CPI (Cost Performance Index) — заработанная стоимость / фактическая стоимость. Цель: ≥ 0,95. SPI (Schedule Performance Index) — заработанная стоимость / плановая стоимость. Цель: ≥ 0,90. Эти два числа вместе показывают, тратите ли вы бюджет, календарь или и то и другое.
KPI надёжности. Тренд разброса прогноза. Постройте на графике линию «оценка vs факт» по спринтам: плоская линия — оценки подрядчика заслуживают доверия, расширяющийся конус — нет. Частота change-order: больше одного существенного изменения на четыре спринта обычно означает не «требования поменялись», а «discovery пропустили».
AI в самом процессе оценки
LLM сегодня действительно полезны на этапе discovery: генерируют первую версию карты пользовательских историй из бизнес-брифа, превращают черновые экраны Figma в критерии приёмки, помечают вероятные пропуски в NFR и находят несоответствия между документом с требованиями и вайрфреймами за минуты, а не за дни. В Фора Софт мы используем их рутинно — в связке с человеческим ревью — и они сжимают стадии 2–3 воронки discovery примерно на 30%.
Чего они пока не могут: заменить экспертное суждение о том, 3-недельная это работа или 9-недельная. Это всё ещё аналоговая оценка от сеньорного инженера со шрамами в предметной области. О том, как мы запускаем AI внутри нашего пайплайна, можно почитать в материалах об AI в процессе разработки и об AI в проектировании архитектуры.
Когда не стоит запускать тяжёлую оценку
Тяжёлая оценка — не всегда ответ. Если вы покупаете двухнедельный прототип для проверки гипотезы, правильное решение — T&M-контракт с потолком и письменным kill-switch, а не трёхнедельный discovery и bottom-up WBS. Если работа — это обслуживание зрелого продукта со стабильной командой, история velocity точнее любой пересборки оценки.
Правило большого пальца: если проект меньше ~8 недель или меньше ~3 млн ₽, пропускайте тяжёлую оценку и берите спринт с потолком. Выше — математика discovery окупает себя каждый раз.
Оцениваете первую разработку для видео, AI или edtech?
Именно этим мы занимаемся с 2005 года — 625+ выпущенных продуктов, 21 год шрамов в реальном времени и AI. Опишите задачу одной фразой — и мы вернёмся с ROM, на который можно опираться.
FAQ
Насколько точной должна быть смета на разработку ПО?
Зависит от стадии. Грубый порядок величины на стадии питча честно лежит в диапазоне −25% до +75%. Бюджетная оценка после продуктового брифа — −15% до +25%. Определённая оценка после 2–4-недельного оплачиваемого discovery — −5% до +10%. Любой, кто обещает ±5% без discovery, накручивает.
Что лучше для MVP стартапа — фикс-прайс или time-and-materials?
Ни то, ни другое в чистом виде. Самая надёжная форма, которую мы видим: оплачиваемый discovery на T&M с потолком (2–4 недели, известный максимум), а затем фиксированная разработка с письменным SLA по change-order. Discovery покупает определённость, а согласованный change-budget сохраняет гибкость внутри каждого спринта.
Можно ли принять оценку, построенную только на Planning Poker?
Не для коммерческого обязательства. Planning Poker отлично работает внутри сформированной команды для спринтовых прогнозов, но предполагает наличие беклога с проработанными историями и измеренной velocity. Для предконтрактной оценки сложите его с bottom-up WBS и трёхточечным PERT; если три метода сходятся в пределах 1,5×, у вас защитимое число.
Сколько должен стоить этап discovery?
Примерно 5–8% от общего бюджета проекта для greenfield-продукта. На разработке за 15 млн ₽ это 750 тыс.–1,2 млн ₽ за две-четыре недели сеньорного времени, на выходе — подписанная карта пользовательских историй, архитектура, NFR-бриф, реестр рисков и определённая оценка разработки. Это рутинно окупается в 4–6 раз за счёт того, что плохой скоуп умирает до написания кода.
Как AI-кодинг влияет на оценку стоимости ПО в 2026 году?
Чистое сокращение на типичной 12-недельной разработке — примерно 15–25%, а не 40%+, как пишут в маркетинговых материалах. Разработка фич падает на 25–40%, но QA и ревью растут на 15–25%, потому что AI-сгенерированный код несёт в ~1,7 раза больше дефектов при неизменной нагрузке на ревью. Сеньорный состав команды с большим отрывом выигрывает у джуниорного.
Что такое конус неопределённости простыми словами?
Это наблюдение, что ранние оценки ПО совершенно законно могут ошибаться в 4 раза в любую сторону, и что диапазон сужается лишь по мере того, как подписываются реальные решения (скоуп, архитектура, UI, критерии приёмки). Само по себе время конус не закрывает — его закрывают решения. Четырёхнедельный неподписанный скоуп ровно так же размыт, как и четырёхдневный.
Можно ли применять COCOMO II или Function Points к современному облачному продукту?
Только как кросс-проверку, не как основной метод. Некалиброванный COCOMO II (чьи референсные данные взяты из водопадных проектов 1990-х) может давать ошибку около 100% на облачных, микросервисных и AI-ассистированных стеках. Function Points точнее, но всё равно требуют локальной калибровки. В качестве основного используйте bottom-up + трёхточечный PERT, параметрические модели — как проверку.
Какие красные флаги в смете подрядчика?
Одно точечное число, нет списка допущений, нет списка исключений, нет интервала доверия, нет строки на QA или DevOps, нет строки на PM-надзор, нет процесса change-order. Любые два из этих признаков вместе означают, что перед вами не оценка, а цена, — и риск приземлится на вас на третьем месяце.
Что читать дальше
Процесс
Семифазное руководство по разработке продукта в 2026 году
Как оценка, discovery и разработка укладываются в единый сквозной процесс поставки.
Гайд по стоимости
Стоимость разработки приложения для видеостриминга — CTO-гайд 2026
Реальные строки и диапазоны для самой часто недосчитываемой категории программных продуктов.
Бюджет
Что стоит делать, чтобы сократить расходы на программный проект
Четыре действия, которые реально снижают burn, не убивая продукт.
Кейс
Как AI сократил время разработки на 40% на видеоплатформе в 1 млн+ строк
Чистая разница в продуктивности от AI и что она делает с оценкой на практике.
MVP
Почему стоит урезать функционал и запускать продукт раньше
MVP-мышление — самый дешёвый маршрут к оценке, на которую можно опираться.
Готовы превратить шаткую смету в подписанный план?
Оценка ПО, в конце концов, — это дисциплинированный разговор между скоупом, уверенностью и риском. Инструменты (аналоговый метод, bottom-up, PERT, Planning Poker, Монте-Карло) важны меньше, чем привычки: называть стадию конуса, оценивать невидимые строки, держать форму контракта честной и пересматривать прогноз каждый спринт. Сделайте эти четыре вещи — и ваша оценка перестанет быть гаданием и станет планом, который можно показать CFO.
В Фора Софт мы запускаем этот плейбук каждую неделю — на платформах видео реального времени, AI-продуктах и edtech-разработках — и охотно применим его к смете, которая лежит перед вами прямо сейчас. Позвоните или напишите — в течение получаса мы проведём вас по вашей текущей смете через пять вопросов из этого руководства. Принесите PDF — мы пройдёмся по нему с пометками.
Получите второе мнение по вашей смете
Бесплатный 30-минутный разбор — пять вопросов, размеченный PDF, честный вердикт: защитима ли ваша текущая смета.