
Главное
• Видеостриминг и видеоконференции — это две разные задачи масштабирования. Стриминг «один ко многим» масштабируется через CDN, ферму транскодеров и адаптивный битрейт. Конференции «многие ко многим» масштабируются через SFU/MCU, каскад серверов и жёсткий бюджет задержки. Решать обе задачи одной архитектурой — самая частая и самая дорогая ошибка.
• Масштабируемость — это структурная задача, а не вопрос количества серверов. Накидывать инстансы на origin, который всё ещё рассылает поток каждому зрителю, бесполезно. Реально двигают цифры stateless API, доставка через CDN на edge, горизонтальные SFU, автомасштабируемые транскодеры и чёткая граница данных.
• Большинство «горящих» платформ можно стабилизировать за 2–6 недель. Точечный аудит обычно выявляет два-три узких места (origin, транскодер, конкуренция за БД, ёмкость TURN), на которые приходится больше 80% инцидентов. Их починка даёт 10× запас по нагрузке до момента, когда понадобится переписывание с нуля.
• Бюджет задержки определяет архитектуру. Меньше 1 с для broadcast (HLS/DASH + CMAF LL), меньше 500 мс для интерактивного live (LL-HLS, WebRTC поверх HLS), меньше 200 мс mouth-to-ear для конференций (WebRTC SFU). Бюджет выбираете до того, как выбираете инструменты.
• KPI, которые действительно важны. Время старта, доля ребуферизации, P95 задержки glass-to-glass, число одновременных зрителей на origin/SFU, стоимость одного одновременного потока, MOS. Если этого нет в реальном времени на дашборде — вы летите вслепую.
• Фора Софт делает такие проекты постоянно. От небольших интерактивных аудиторий e-learning (BrainCert, Scholarly) до глобальной трансляции чемпионатов по бильярду (Kozoom) и корпоративных WebRTC-флотов — мы знаем, где именно цифры начинают «ломаться», и закладываем настройку заранее.
Почему этот гид написала Фора Софт
Фора Софт уже 21 год создаёт продукты для real-time видео и стриминга. В нашем портфолио — масштабная live-видео-обучалка BrainCert, broadcast-уровень трансляций бильярда на Kozoom, телемедицина, WebRTC-залы суда, OTT-платформы и системы видеонаблюдения. Мы построили, проаудировали и спасли больше таких систем, чем готовы посчитать.
Этот гид — то, что мы рассказываем клиентам в первую неделю проекта по масштабированию: чем на самом деле различаются стриминг и конференции, где платформы ломаются первыми, как честно посчитать нагрузку и как выглядит реалистичное решение. В основе — конкретные технологии, которые мы используем в продакшене: bare-metal Hetzner серии AX под транскодинг, Cloudflare на edge, mediasoup и LiveKit для SFU-кластеров, managed Kubernetes там, где он окупается, плюс сравнение разработки на заказ с managed-видео уровня Agora.
Если вы сейчас смотрите на дашборд, который краснеет на демо для клиентов, наши кастомные модули масштабируемости спроектированы так, чтобы встать рядом с вашим текущим стеком и купить вам запас по нагрузке до того момента, когда переписывать архитектуру всё-таки придётся.
Платформа не выдерживает реальный трафик?
Получаса разговора обычно достаточно, чтобы назвать те два-три узких места, которые блокируют рост на следующий порядок. Бесплатно, без продажного шоу.
Стриминг и конференции: две разные задачи масштабирования
Решения по масштабированию начинаются с одного вопроса: какой трафик-паттерн у продукта? Broadcast (один публикующий, много зрителей) и конференции (много публикующих, много зрителей) выглядят похоже на питч-слайде, но в продакшене ведут себя совершенно по-разному.
| Параметр | Стриминг «один ко многим» (OTT/live) | Конференции «многие ко многим» |
|---|---|---|
| Форма трафика | 1 публикующий, 10 тыс.–10 млн зрителей | 2–1000 публикующих, столько же зрителей |
| Бюджет задержки (glass-to-glass) | 2–30 с стандартно, <1 с на LL-HLS/CMAF, <500 мс на WebRTC-over-CDN | <200 мс для интерактива, <50 мс для критичных сценариев |
| Базовый примитив | Ingest → транскодер → пакетирование → CDN → плеер | WebRTC-пир → SFU → (опционально) каскад → пир |
| Главное узкое место | CPU/GPU транскодера, исходящий трафик origin | Порты и полоса пропускания SFU, ёмкость TURN |
| Структура затрат | Доминирует egress, CDN тарифицирует за ГБ | Доминирует compute, хостинг SFU за CCU |
| Единица масштабирования | PoP + кэш-слой на регион | Узел SFU на 300–1000 одновременных потоков |
| Плеер | HLS/DASH + ABR-лестница | WebRTC SDK (браузер/нативный) |
Правило большого пальца: если вам нужна большая аудитория и вас устраивает задержка 2–10 с — ставьте на HLS + CDN. Если нужна интерактивная задержка меньше секунды и много публикующих — ставьте на SFU. Гибридные продукты (live-уроки, watch-party, интерактивный спорт) требуют и того, и другого, причём спроектированных вместе.
Почему видеоплатформы реально ломаются — и почему «купить ещё серверов» не помогает
Когда видеоплатформа падает на вебинаре, финале по крикету или виртуальном уроке, проблема почти никогда не в общем количестве CPU. Почти всегда это один из пяти структурных сбоев.
1. Один origin раздаёт поток каждому зрителю. Нет CDN или он слишком маленький. Egress упирается в первую сетевую карту, которая выходит на потолок; буферизация расползается регион за регионом.
2. Транскодер на универсальной VM с общими ресурсами. ABR-лестницы дорогие по CPU. Запускать 1080p60 H.264 на shared t-class VM — учебниковый источник обрывов потока.
3. SFU размером «как было вчера». SFU для конференций упираются в исходящую полосу или количество портов. Один узел спокойно держит 300–1000 одновременных аудио+видео-треков; за этой границей нужен каскад или автомасштабирование.
4. Stateful-серверы приложений. Если состояние сессии живёт в процессе приложения, горизонтально это не масштабируется без sticky-сессий или общего состояния. Состояние должно жить в Redis, Postgres или отдельном хранилище сессий.
5. Никакой наблюдаемости. Нет дашборда по доле ребуферизации, нет P95 времени старта, нет алерта на CPU SFU — вы узнаёте о проблеме из Twitter. Мониторинг стоит дёшево. Перестраиваться в огне — нет.
Простой стоит дорого. По свежим данным Gartner и Information Technology Intelligence Consulting, средняя стоимость простоя в корпоративных системах — от 420 тыс. ₽ до 675 тыс. ₽ за минуту. На потребительском live-стриме это лишь часть потерь по рекламе, отписок и удара по бренду. Один точечный аудит почти всегда дешевле, чем следующий инцидент.
Как на самом деле проектируются масштабируемые видеосистемы
Одни и те же шесть принципов проектирования встречаются в каждом хорошо отмасштабированном видеопродукте. Это не секретные приёмы, а базовый стандарт.
1. Stateless-вычисления, stateful-хранилище. API-сервисы не держат пользовательское состояние в памяти. Сессии живут в Redis; медиа-состояние — в SFU или origin; бизнес-данные — в Postgres. Любой сервис может умереть или масштабироваться без липкой маршрутизации.
2. Доставка через CDN. Для broadcast: HLS/DASH пакетируется на origin, кэшируется на CDN (Cloudflare, Fastly, Akamai, AWS CloudFront). 95–99% трафика зрителей не доходит до origin. Для low-latency — LL-HLS или WebRTC-over-CDN (Cloudflare, Phenix), чтобы держать задержку ниже секунды.
3. Адаптивный битрейт (ABR). Лестница рендиций (например, 240p, 480p, 720p, 1080p при 400 Кбит/с / 1,2 Мбит/с / 3 Мбит/с / 6 Мбит/с) позволяет каждому зрителю выбрать максимальное качество, которое выдержит его соединение. Доля ребуферизации падает на порядок.
4. Горизонтальный SFU с каскадом. Каждый SFU имеет потолок (скажем, 500 одновременных медиа-потоков). Когда комната перерастает потолок, её каскадируют на второй SFU. mediasoup, LiveKit, Jitsi и Janus всё это умеют — детали реализации различаются.
5. Транскодинг на правильном железе. Для серьёзного broadcast мы запускаем транскодеры на bare metal Hetzner серии AX с GPU (NVENC) или выделенным CPU. На пиках добавляем эластичный burst в AWS MediaConvert или Cloudflare Stream. Транскодинг на shared VM — это ловушка.
6. Мониторинг и плавная деградация. Дашборд по P95 времени старта, доле ребуферизации, error rate по регионам, CPU SFU, полосе TURN. Алерты на 70% ёмкости. Когда что-то идёт не так — сначала отключаем неважное: симулькаст-слои, 4K-рендиции, навороченные фильтры. Базовый поток должен жить.
Эталонная архитектура масштабируемой видеоплатформы
Схема ниже — то, к чему мы по умолчанию приходим для всего, что выше нескольких тысяч одновременных пользователей. Маленький продукт использует подмножество; корпоративный продукт добавляет региональные реплики и резервирование private origin.
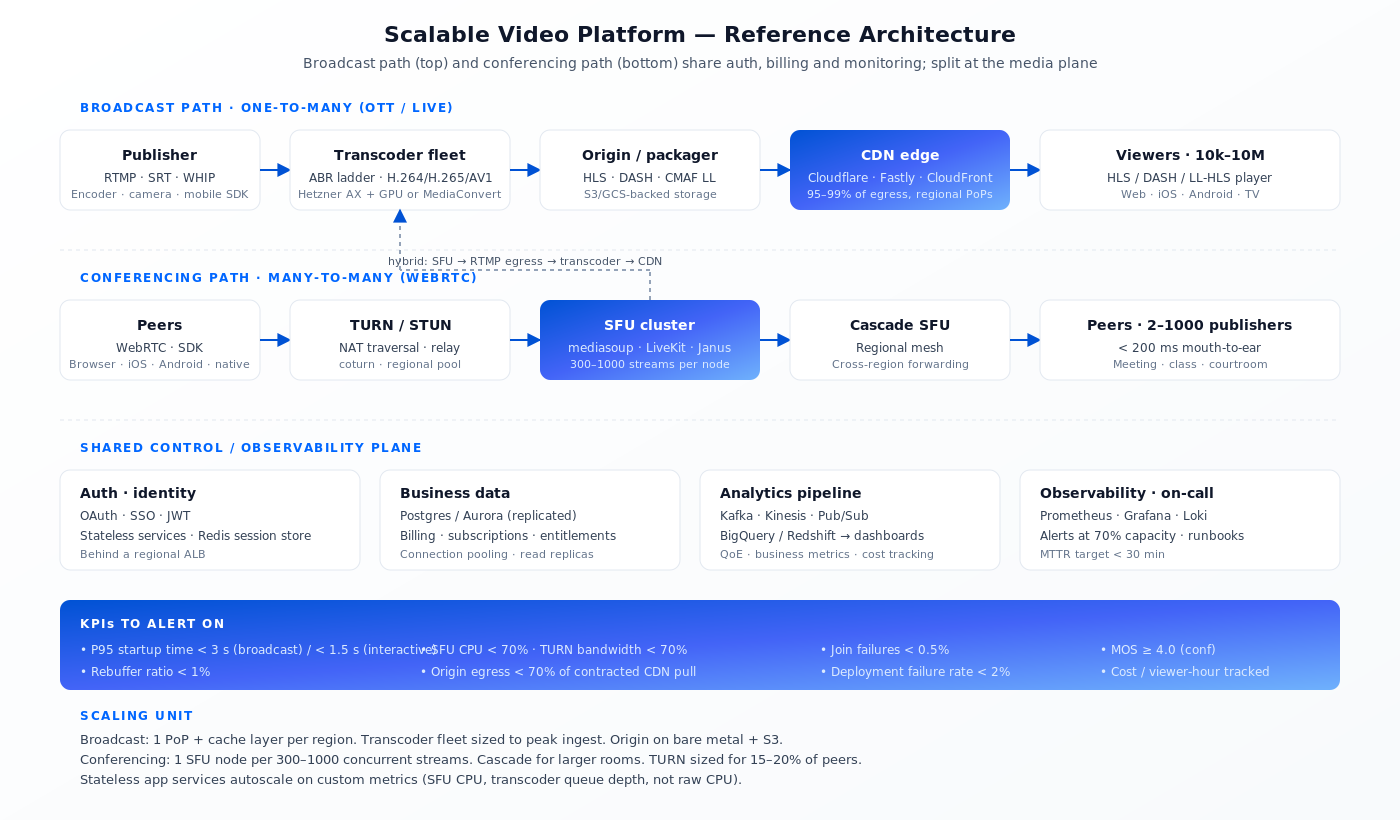
Рисунок 1. Путь broadcast (сверху) и путь конференций (снизу) делят авторизацию, биллинг и мониторинг, но расходятся на медиа-плоскости.
Путь broadcast (OTT, live-события)
Ingest (RTMP, SRT или WebRTC-WHIP) → ферма транскодеров, выдающая ABR-лестницу → origin, который пакетирует поток в HLS/DASH + CMAF LL → edge CDN → плеер. Типичная единица масштабирования — региональная ферма транскодеров под пиковый ingest, плюс автомасштабируемая группа на всплески.
Путь конференций (встречи, комнаты, интерактивный live)
WebRTC-пир → кластер SFU → (опционально) каскадный SFU → WebRTC-пир. TURN-серверы масштабируются отдельно, в зависимости от того, сколько в вашей аудитории клиентов за симметричным NAT (правило большого пальца — 15–20% пользователей нуждаются в TURN). Для интерактивных live-продуктов (watch-along, e-learning) этап конференции может уходить в путь broadcast через server-side RTMP-egress.
Общий слой (авторизация, биллинг, аналитика)
Идентификация, биллинг, пользовательские записи и аналитика общие для обоих путей. Эти сервисы — stateless, горизонтально масштабируемые, за региональным балансировщиком, ходят в реплицированный Postgres или Aurora. События аналитики льются в Kafka или managed-аналог, оседают в BigQuery/Redshift для отчётов и в time-series-хранилище (Prometheus, Grafana Cloud) для эксплуатации.
Бюджеты задержки, которые диктуют архитектуру
До того как выбирать инструменты, выберите бюджет задержки. Всё остальное вытекает из него.
| Сценарий | Цель glass-to-glass | Подходящий стек |
|---|---|---|
| VOD / OTT-библиотека | не применимо (старт < 3 с) | HLS/DASH + CDN, VOD-пакетировщик |
| Стандартный live (спорт, концерты) | 5–30 с | HLS/DASH с сегментами 6 с + CDN |
| Low-latency live (ставки, аукционы) | 1–3 с | LL-HLS, CMAF low-latency |
| Интерактивный live (e-learning, онлайн-фитнес) | 300 мс–1 с | WebRTC-over-CDN или SFU с RTMP-egress |
| Групповой видеозвонок | <200 мс | WebRTC SFU (LiveKit, mediasoup, Jitsi) |
| Зал суда, операционная, трейдинг | <50 мс | WebRTC SFU с региональным TURN, сеть с QoS-настройкой |
Частая ловушка: требовать задержку меньше секунды от платформы, спроектированной с 6-секундными HLS-сегментами. Это не «подкрутить параметр» — это переписывание архитектуры.
Нужно второе мнение по плану масштабирования?
Мы прогоним вашу архитектуру по бюджету задержки и реальной форме трафика. Если план рабочий — так и скажем.
Когда платформа уже горит: план стабилизации
Большинство платформ, которые мы аудируем, не сломаны навсегда. У них два-три узких места, на которые приходится подавляющая часть инцидентов. Точечная работа на 2–6 недель даёт 10× запас. Стандартная последовательность:
Неделя 1 — аудит и базовые метрики. Замеряем P95 старт, долю ребуферизации, CPU SFU, исходящий трафик origin, пул соединений с БД. Находим топ-3 узких места. Письменный аудит кода и архитектуры становится картой действий.
Недели 1–2 — поставить CDN перед origin. Быстрая победа дня для broadcast. Cloudflare или Fastly на HLS/DASH-эндпоинте сокращают исходящий трафик origin на 95–99% почти мгновенно.
Недели 2–3 — контейнеризация и автомасштабирование. Stateless-сервисы переезжают в контейнеры (Docker + Kubernetes или ECS). Автомасштабирование — по кастомным метрикам (CPU SFU, глубина очереди транскодера), а не только по CPU.
Недели 3–4 — вывести транскодинг с пути приложения. Транскодеры уезжают на выделенное железо или managed-сервисы (AWS MediaConvert, Cloudflare Stream, Wowza). Обработка через очередь, не внутри запроса.
Недели 4–5 — каскадировать SFU. Для конференций. Каждый SFU ограничен известной полосой или количеством участников; комнаты каскадируются по узлам, маршрутизация — по географии.
Недели 5–6 — наблюдаемость и runbooks. Дашборды Grafana по KPI ниже. Алерты на 70% ёмкости. Runbooks по топ-5 инцидентов. Blue-green или canary-деплой, чтобы релизы перестали быть авариями.
Типичный результат: платформы, разваливавшиеся на 200–500 одновременных пользователях, выходят на стабильные 5–20 тыс. CCU за шесть недель — без вмешательства в основной код продукта. Полная миграция занимает дольше, стабилизация — нет.
Модель затрат: куда на самом деле уходят деньги
Два паттерна, которые надо запомнить:
В broadcast доминирует egress. Когда у вас уже есть CDN, compute стоит копейки, а полоса — дорого. На большом масштабе цена — 0,3–3 ₽ за ГБ в зависимости от контракта с CDN и региона. Поток на 2 Мбит/с при просмотре в течение часа — это около 900 МБ, то есть примерно 0,3–2,7 ₽ egress на час просмотра. Транскодинг — это фиксированная стоимость флота, размазанная по всем зрителям.
В конференциях доминирует compute. Managed-сервисы (Agora, Twilio, Daily, LiveKit Cloud) тарифицируют за одновременного пользователя или за минуту — типичный managed WebRTC обходится в 0,2–0,7 ₽ за минуту участника. Self-hosted SFU на Hetzner или Equinix может быть дешевле в 3–5× на устойчивом масштабе, но требует своей платформенной команды.
| Профиль нагрузки | Подходящий хостинг | Ориентир по цене | Комментарии |
|---|---|---|---|
| VOD / OTT-библиотека | Объектное хранилище + CDN | 0,3–1,5 ₽ / час просмотра | Зависит от hit-rate; на масштабе origin почти ничего не стоит |
| Live-событие (с пиками) | Облачный транскодер + CDN | 1,5–4,5 ₽ / час просмотра | Удобно для всплесков, выше цена за ГБ |
| Live-стриминг в устойчивом режиме | Bare metal под транскодинг + CDN-контракт | 0,6–2,2 ₽ / час просмотра | Hetzner AX + Cloudflare — наш частый выбор |
| Managed-конференции | Agora / Twilio / LiveKit Cloud | 0,3–0,7 ₽ / минута участника | Без расходов на эксплуатацию, но привязка к вендору |
| Self-hosted SFU | mediasoup/LiveKit на Hetzner | 0,06–0,2 ₽ / минута участника | Нужна своя платформенная команда; большая экономия на масштабе |
Точка перехода: self-hosted SFU выигрывает у managed примерно на 30–50 тыс. минут участников в день — зависит от географии. Ниже этого порога managed-конференции почти всегда дешевле по совокупной стоимости владения с учётом времени инженеров.
Мини-кейс: стабилизация live-видео-платформы для e-learning
Ситуация. Live-видео-продукт для e-learning, построенный на монолитном Node-сервере с одним SFU, разваливался на 300–400 одновременных пользователях во время вечернего часа пик в Азии. Вебинары деградировали до аудио, участники отваливались, CSAT в магазине приложений рухнул.
Что мы изменили за шесть недель. Перенесли stateless-сервисы за ALB и автомасштабировали их в Kubernetes. Каскадировали SFU-кластер (mediasoup) с четырьмя региональными узлами — два в ЕС, один на восточном побережье США, один в Сингапуре. Вынесли TURN в отдельный пул. Добавили дашборды Grafana по P95 старта, отказам подключения и CPU SFU, с алертами на 70% ёмкости.
Результат. Стабильные 8–10 тыс. CCU на том же коде продукта, P95 подключения меньше 1,5 с, доля ребуферизации снизилась с 4,1% до 0,6%. Месячная стоимость инфраструктуры выросла примерно на 450 тыс. ₽, при этом удалось избежать переписывания, оценённого в 30 млн ₽, и разблокировать новый корпоративный тариф. Эта схема повторяется на масштабируемых системах видеонаблюдения и в интерактивных live-инструментах в целом.
Хотите такую же оценку по своей платформе? Позвоните нам по номеру +7 (911) 236-51-91 — обычно мы оставляем после разговора одностраничный список действий, который можно начать выполнять уже в следующий спринт.
Фреймворк решений — масштабируйте видеоплатформу за пять вопросов
В1. Broadcast или интерактив? Один публикующий на много зрителей → HLS + CDN. Многие ко многим с интерактивом меньше 200 мс → WebRTC SFU. Гибрид (live-урок с Q&A) → и то, и другое, спроектированные вместе.
В2. Какой реальный бюджет задержки? Запишите его в миллисекундах. Не давайте никому потом «передоговориться» о нём, не переделав пайплайн.
В3. Какой пик одновременных пользователей? Пиковый CCU — это число, под которое вы размеряете флот. Обычный трафик скрывает проблему. Моделируйте худшую минуту худшего дня, который вам важен.
В4. Managed или self-hosted медиа? До ~30 тыс. минут участников в день managed выигрывает по совокупной стоимости. Выше этого порога self-hosted окупается за квартал, если у вас есть команда.
В5. Кто на дежурстве? Видео работает 24/7. Если нет ротации с runbooks — за это вы заплатите простоями вместо зарплат.
Пять подводных камней почти на каждом проекте по масштабированию
1. Один origin для broadcast. Без CDN, без кэш-слоя. Первые 500 зрителей насыщают NIC; качество падает регион за регионом.
2. Stateful-серверы приложений. Состояние пользователя или сессии прибито к процессу. Горизонтально не масштабируется; sticky-сессии становятся новым узким местом.
3. Один SFU на весь мир. Прекрасно работает до первого глобального события. Каскад и региональные SFU становятся обязательными выше ~500 одновременных потоков.
4. Транскодинг на VM приложения. Всплески CPU роняют API. Транскодинг — на отдельный флот или managed-сервис.
5. Нулевая наблюдаемость. Нет дашборда по ребуферизации, нет гистограммы времени старта, нет алерта на CPU SFU. Узнаете о проблеме из жалобы клиента в Twitter, не раньше.
KPI: что мониторить каждую неделю
KPI качества. P95 времени старта < 3 с (broadcast) или < 1,5 с (интерактив). Доля ребуферизации < 1%. Отказы старта видео < 0,5%. MOS ≥ 4,0 (конференции). P95 glass-to-glass — в пределах бюджета вашего сценария.
Бизнес-KPI. Одновременные зрители, длительность сессии, доля досмотров, отток по регионам, стоимость на час просмотра или на минуту участника. Эти метрики оправдывают всю программу.
KPI надёжности. CPU origin и SFU (алерт на 70%), утилизация полосы TURN, error rate по регионам, P99 задержки подключения, доля провальных деплоев, MTTR меньше 30 минут. Относитесь к видеоплоскости как к платёжной системе: если она лежит — выручка течёт.
Когда не стоит строить кастомное масштабирование
Ранний MVP с непредсказуемым спросом. Берите managed-сервисы (Mux, Cloudflare Stream, LiveKit Cloud, Agora, Daily), чтобы выиграть время. Кастомная разработка окупается, когда у вас уже есть устойчивая кривая роста.
Очень маленькая аудитория, очень долгий жизненный цикл. 200 активных пользователей в репетиторском приложении — managed навсегда. Инженерная стоимость DIY перекрывает любую экономию.
Команда без экспертизы по WebRTC и стримингу. Self-hosted SFU и транскодеры не прощают ошибок. Если такого опыта нет — и нанять некого — оставайтесь на managed.
Стандартный сценарий внутри чужой экосистемы. Виджет встреч внутри EMR-системы обычно живёт на Amazon Chime SDK или Zoom SDK — не на собственном флоте SFU.
Думаете о миграции с Agora или Twilio?
Мы делали такие миграции уже не раз (mediasoup, LiveKit, Janus). Скажите ваш CCU — мы вернёмся с дельтой по TCO и реалистичным сроком.
FAQ
Что вообще значит «масштабируемый» для видеоплатформы?
Это значит, что система может вырасти по числу одновременных пользователей или сессий минимум на порядок, без пропорционального роста стоимости, задержки и отказов. На практике: P95 старта и доля ребуферизации остаются в пределах бюджета, CPU SFU и origin держится ниже 70%, а добавление мощности — это масштабирование группы, а не передеплой стека.
Строить на WebRTC, на HLS или на обоих?
Broadcast (VOD, спорт, концерты) с допустимой задержкой 5–30 с — HLS/DASH + CDN. Групповые звонки, интерактивные комнаты, залы суда, телемедицина — WebRTC SFU. Интерактивный live (онлайн-классы, фитнес-стримы, аукционы) обычно требует обоих: WebRTC для активных участников и HLS/LL-HLS для пассивной длинной аудитории.
Почему маленькие платформы так легко ломаются на росте?
Ранние версии обычно полагаются на один origin, stateful-процесс на Node и общую VM, обслуживающую и API, и транскодинг. Под реальным трафиком все три падают. Лечить нужно не размером, а структурой — CDN, stateless-сервисы, выделенный транскодинг, мониторинг.
Масштабируемость — это просто докупить серверов?
Нет. Железо не лечит структурное узкое место — оно просто делает падение громче. Можно поставить десять серверов за одним origin и всё равно отправлять 100% зрителей в этот origin. Сначала тратьте на CDN, stateless-перепроектирование и мониторинг; и только потом увеличивайте compute.
Можно ли стабилизировать перегруженную систему без полного переписывания?
В большинстве случаев да. Точечная программа на 2–6 недель — CDN, stateless-сервисы, каскад SFU, выделенный транскодинг и мониторинг — обычно даёт 10× запаса по безопасной нагрузке. Полное переписывание иногда необходимо (например, если всё приложение построено вокруг сломанного WebSocket-сигналинга), но это исключение.
Сколько занимает масштабирование видеоплатформы?
Быстрые победы (CDN перед origin, асинхронный транскодинг, базовые дашборды) — несколько дней. Полная программа стабилизации с каскадом SFU, автомасштабированием, blue-green-деплоями и наблюдаемостью — 4–8 недель для большинства платформ. Кастомная разработка с нуля — 4–9 месяцев в зависимости от объёма.
Как понять, что моя платформа реально масштабируется?
Проведите нагрузочный тест на 2× ожидаемого пика и смотрите KPI. P95 старта остаётся < 3 с, ребуферизация < 1%, ни один регион не падает ниже целевого качества, CPU SFU держится < 70%. Сюда же — chaos-тест (убить регион, уронить узел): если платформа выдержала, всё хорошо. Если хоть что-то покраснело — у вас есть пробел в масштабировании.
Делает ли Фора Софт бесплатный аудит масштабируемости?
Да. Первый разговор по объёму работ — бесплатный. Если нужен формальный аудит кода и архитектуры, мы делаем его как фиксированный пакет на одну неделю — на выходе вы получаете приоритезированный список действий и реалистичный диапазон бюджета на стабилизацию.
Что читать дальше
Архитектура
Гид по архитектуре WebRTC для бизнеса (2026)
SFU, MCU, каскад и TURN — простыми словами для продуктовых руководителей, выбирающих стек для конференций.
Миграция
Альтернатива Agora.io: кастомный WebRTC на LiveKit, mediasoup, Jitsi и Janus
TCO и план миграции, когда managed-конференции на масштабе становятся слишком дорогими.
VMS
Масштабируемые системы видеонаблюдения в 2026
Пять инженерных решений, которые действительно важны, когда VMS уходит за несколько тысяч камер.
Затраты
Как оценить стоимость серверов для видеоплатформы
Модель затрат, опирающаяся на CCU, с реальными цифрами под реальную нагрузку.
Гид по разработке
Разработка стримингового приложения: VOD, live и видеоконференции
End-to-end гид по разработке для основателей, выбирающих правильный видеопаттерн с первого дня.
Готовы масштабировать видеоплатформу, не сломав её?
Масштабируемость в видео — это никогда не «купить ещё серверов». Это набор структурных решений: stateless-вычисления, доставка через CDN, ABR, горизонтальные SFU, выделенные транскодеры, серьёзный мониторинг. У стриминга и конференций своя версия этого плана; решать обе задачи одной архитектурой — самая дорогая ошибка в категории.
Большинство платформ, которые сейчас «горят», можно стабилизировать за шесть недель. Оставшимся 20% нужна более серьёзная переделка архитектуры, и обычно её имеет смысл затевать только после того, как стабилизация купит время для нормального планирования. В любом случае — измеряйте правильные KPI, держите людей в петле принятия решений и проектируйте под ту кривую роста, которую вы реально ожидаете, а не на которую надеетесь.
Давайте оценим вашу программу масштабирования
Тридцать минут, реальный инженер, одностраничный план: узкие места, приоритеты, реалистичный бюджет и срок. Бесплатно.