Ключевые выводы
• Выбирайте уровень клонирования под задачу. Zero-shot (образец 3–6 секунд) — для интерактивных агентов, few-shot (1–3 минуты) — для стабильных продуктовых голосов, Professional Voice Cloning (30 минут и больше) — для аудиокниг и вещания.
• End-to-end задержка меньше 500 мс достижима в 2026 году. Cartesia Sonic, Inworld TTS-1.5 Max и ElevenLabs v3 укладываются в 300 мс до первого аудио; узким местом обычно становится LLM, а не TTS.
• Согласие и водяные знаки — это часть архитектуры, а не юридическая приписка. EU AI Act (статья 50), Tennessee ELVIS Act и Illinois BIPA требуют письменного согласия, отслеживания происхождения и явного раскрытия. Дорабатывать это задним числом дорого и больно.
• Стоимость у разных провайдеров отличается в 10 раз. Cartesia — около 0,04–0,07 ₽ за 1 000 символов, ElevenLabs — 0,2–1 ₽, OpenAI Realtime — около 2 ₽ за минуту. Self-hosted XTTS-v2 на A100 выходит в плюс при 3 000 и более одновременных потоков.
• Качество — это цикл, а не разовый запуск. Сходство голоса (ECAPA-TDNN cosine ≥ 0,80), MOS ≥ 4,0, ошибки произношения < 2 % — измеряемые каждую неделю на отложенной выборке — вот что удерживает голосовой продукт в форме.
За два года клонирование голоса в реальном времени прошло путь от исследовательского демо до производственной фичи. В 2026 году вы можете отправить трёхсекундный референсный аудиофрагмент на WebSocket-эндпоинт и получить обратно поток почти идеальной синтетической речи с задержкой до первого аудио 40–150 мс. Это открывает целый класс продуктов — AI-агенты колл-центров, синхронный дубляж, восстановление голоса для людей с инвалидностью, многоязычный перевод встреч, персональные ассистенты, — которые год назад были невозможны по такой цене. Это же создаёт реальные риски: дипфейк-мошенничество, голосовые скам-звонки, нелицензированные имперсонации. Этот гайд проводит вас по тому, как грамотно использовать технологию: какие решения принять, кого выбрать в качестве вендора, как уложиться в требования регуляторов, как посчитать стоимость и каких ловушек избегать.
Целевая аудитория: CTO, основатели, продакт-лиды и руководители разработки, которые проектируют продукт с клонированием голоса — AI для колл-центра, инструмент доступности, дубляж медиа, NPC в играх, образовательные ассистенты. Всё ниже привязано к реальному протоколу, вендору, модели или цифре; оценки стоимости намеренно консервативные.
Почему Фора Софт написала этот гайд
У Фора Софт 21 год опыта в инженерии видео, аудио и AI в реальном времени — выпустили 625+ продуктов с серьёзной концентрацией в голосе, стриминге и разговорном AI. Мы построили кастомные голосовые пайплайны на ElevenLabs, Cartesia, OpenAI Realtime, self-hosted XTTS-v2 и NVIDIA Riva в проектах по телемедицине, дистанционному образованию, синхронному переводу и поддержке клиентов. Мы делаем продукты в области интеграции AI и кастомной обработки видео и аудио, где бюджет задержки измеряется десятками миллисекунд, а профиль соответствия требованиям меняет архитектуру.
Этот гайд собирает в одну справочную статью то, что мы вынесли из этих проектов, плюс исследования по продакшен-клонированию голоса 2025–2026 годов. Его можно передать своей команде разработки или внешнему партнёру. Если нужно второе мнение по выбору вендора, архитектуре или модели затрат — позвоните или напишите нам в конце статьи. Наш Agent Engineering-процесс быстро и недорого превращает proof of concept в работающий прототип.
Проектируете голосовой продукт в реальном времени?
Расскажите нам о целевой задержке, наборе языков и регионе соответствия требованиям. За 30 минут мы набросаем правильного вендора, реалистичную стоимость минуты и план proof of concept на 4 недели.
Что на самом деле означает «клонирование голоса в реальном времени» в 2026 году
Клонирование голоса генерирует речь голосом целевого спикера из произвольного текста, опираясь на референсный аудиосэмпл. «Реальное время» сужает это до бюджетов задержки, которые поддерживают живой диалог: меньше 500 мс end-to-end для агента, отвечающего, пока человек ещё договаривает фразу; меньше 1 секунды для живого дубляжа; меньше 3 секунд для пакетной озвучки. Отличайте это от обычного TTS (фиксированная библиотека голосов, без персонализации) и от voice conversion (вход — аудио, выход — то же содержание чужим голосом, без генерации).
| Уровень | Нужен сэмпл | Типичное сходство голоса | Где уместен |
|---|---|---|---|
| Zero-shot | 3–6 секунд | 0,70–0,82 | Агенты, NPC, временные пользовательские клоны |
| Instant / few-shot | 30–90 секунд | 0,80–0,88 | Брендовые голоса, подкасты, образовательные тьюторы |
| Professional Voice Cloning (PVC) | 30 минут и больше | 0,90–0,96 | Аудиокниги, дубляж для вещания, лицензирование голосов знаменитостей |
| Дообученная кастомная модель | 8–16 часов | 0,95 и выше | Сохранение исторического бренд-голоса, долгоживущие IP-голоса |
Берите zero-shot, если: ваш продукт должен подключать нового спикера в каждой сессии (NPC под каждого игрока, голос клиента для персонализированного IVR). Качество достаточно хорошее для разговорного UX, но не для контента уровня аудиокниги.
Берите few-shot, если: голос — это продуктовый актив, которому нужна устойчивая личность: бренд-агенты, тьюторы, постоянные игровые персонажи. Лишняя минута на сбор сэмпла окупается с лихвой.
Берите PVC, если: результат распространяется наружу: аудиокниги, дублированные фильмы, YouTube-серии. Zero-shot никогда не звучит на уровне вещания, а PVC звучит.
Где клонирование голоса в реальном времени реально окупается
Не каждому продукту нужен клонированный голос. В 2026 году ROI однозначно положительный в нескольких категориях.
AI-агенты колл-центров. Замена или усиление поддержки первой линии круглосуточным многоязычным агентом с постоянным приятным голосом — в идеале клонированным с вашего лучшего человеческого оператора. Стоимость минуты по управляемым тарифам 2026 года — копейки, экономия по сравнению с почасовым аутсорсом проявляется сразу же на средних объёмах звонков.
Синхронный дубляж и многоязычный перевод. Живой перевод встреч, вебинаров, спортивных комментариев с сохранением голоса оригинального спикера на целевом языке. Работа CAMB.AI на Паралимпиаде 2026 года с Eurovision Sport — показательный кейс. Для слоя перевода связывайте клонирование голоса со стеком из наших гайдов по синхронному переводу встреч и многоязычному переводу видеозвонков.
Доступность и банкинг голоса. Пациенты с БАС, болезнью Паркинсона и предоперационные пациенты записывают сэмпл 30–90 секунд, который система использует, чтобы восстановить их собственный голос на устройстве AAC или в коммуникационном приложении. Ставки максимально высоки; PVC-качество оправдано; согласие и раскрытие должны быть железобетонными.
Разговорные аватары и ассистенты. Персональный брендинг для инфлюенсеров, кастомный голос для домашних ассистентов, многоязычные боты поддержки. Cartesia Sonic и Inworld TTS вытягивают это с задержкой меньше 200 мс.
Локализация медиа и автоматизация озвучки. Контент креаторов на YouTube, TikTok, LinkedIn, производство аудиокниг, дубляж корпоративных тренингов. Пакетные процессы теперь достаточно быстры, чтобы создатель локализовал час контента за несколько минут.
Игровые NPC с динамическими диалогами. Процедурно сгенерированные деревья диалогов, озвученные в реальном времени; раньше это было запретительно дорого из-за оплаты актёров. Сейчас — несколько копеек за NPC-час.
Партнёры в изучении языков. Голос тьютора, который подстраивается под предпочтения учащегося по диалекту, или партнёр, который интерактивно исправляет произношение. Связывайте с ASR для замкнутой петли обратной связи.
AI-ассистенты звонков и исходящие продажи. Для стека, специфичного для звонков (VoIP-мост, бюджет задержки, barge-in), смотрите наш гайд по API AI-ассистентов звонков.
Ландшафт вендоров: кто лидирует по задержке, качеству и цене
Выбирайте вендора по трём осям, которые реально важны для вашего продукта: время до первого аудио, верность голоса и стоимость за минуту. Разница в качестве у верхнего эшелона небольшая; разница в стоимости — огромная.
| Вендор | Время до первого аудио | Сэмпл для клонирования | Стоимость | Где уместен |
|---|---|---|---|---|
| ElevenLabs | 150–300 мс | 1–3 мин (instant) / 30 мин и больше (PVC) | ~0,2–1 ₽ за 1 000 символов | Продукты, где важно качество, вещание, инструменты подтверждения подлинности |
| Cartesia (Sonic / Sonic Turbo) | 40–90 мс | 3 секунды (zero-shot) | ~0,04–0,07 ₽ за 1 000 символов | Агенты с критичной задержкой, чувствительный к цене масштаб |
| OpenAI Realtime / Voice Engine | 500 мс end-to-end | Кастомный голос с защитными ограничениями | ~2 ₽ за минуту (Realtime) | Все-в-одном агенты ASR + LLM + TTS |
| Resemble AI | <500 мс | 5 мин и больше | ~0,3 ₽ за 1 000 символов | Корпоративное клонирование голоса и дообучение |
| Respeecher | <1 с в стриминге | 30 мин и больше, уровень вещания | Кастомный корпоративный | Кино, ТВ, премиальная реклама |
| Camb.ai | <500 мс | Полный референсный клип | Корпоративный | Живой дубляж, спорт, вещание |
| Microsoft Azure Personal Voice | <500 мс | 1–2 минуты | ~0,7–1,8 ₽ за 1 000 символов | Экосистема Azure, HIPAA, корпоратив |
| Google Chirp 3 / Custom Voice | 400–600 мс | Кастомный голос (превью) | ~0,3 ₽ за 1 000 символов | Стеки на GCP, поддержка 90+ языков |
| Coqui XTTS-v2 (open-source) | 150–200 мс на GPU | 6 секунд | Только стоимость self-host | On-prem, ограничения приватности, изолированные деплои |
Более широкий ландшафт TTS-вендоров (включая нон-клонирующие синтетические голоса) разбирается в нашем обзоре лучших библиотек синтетического голоса для разработки приложений. Для апстрим-инструментов ASR и обработки аудио карта полного стека — в обзоре 7 лучших AI-инструментов для аудиоприложений.
Референсная архитектура продукта с клонированием голоса в реальном времени
Продукт с клонированием голоса в реальном времени сшивает четыре подсистемы: захват, реестр клонов, пайплайн синтеза и доставку. Пятая — соответствие требованиям — гейтит всё остальное.
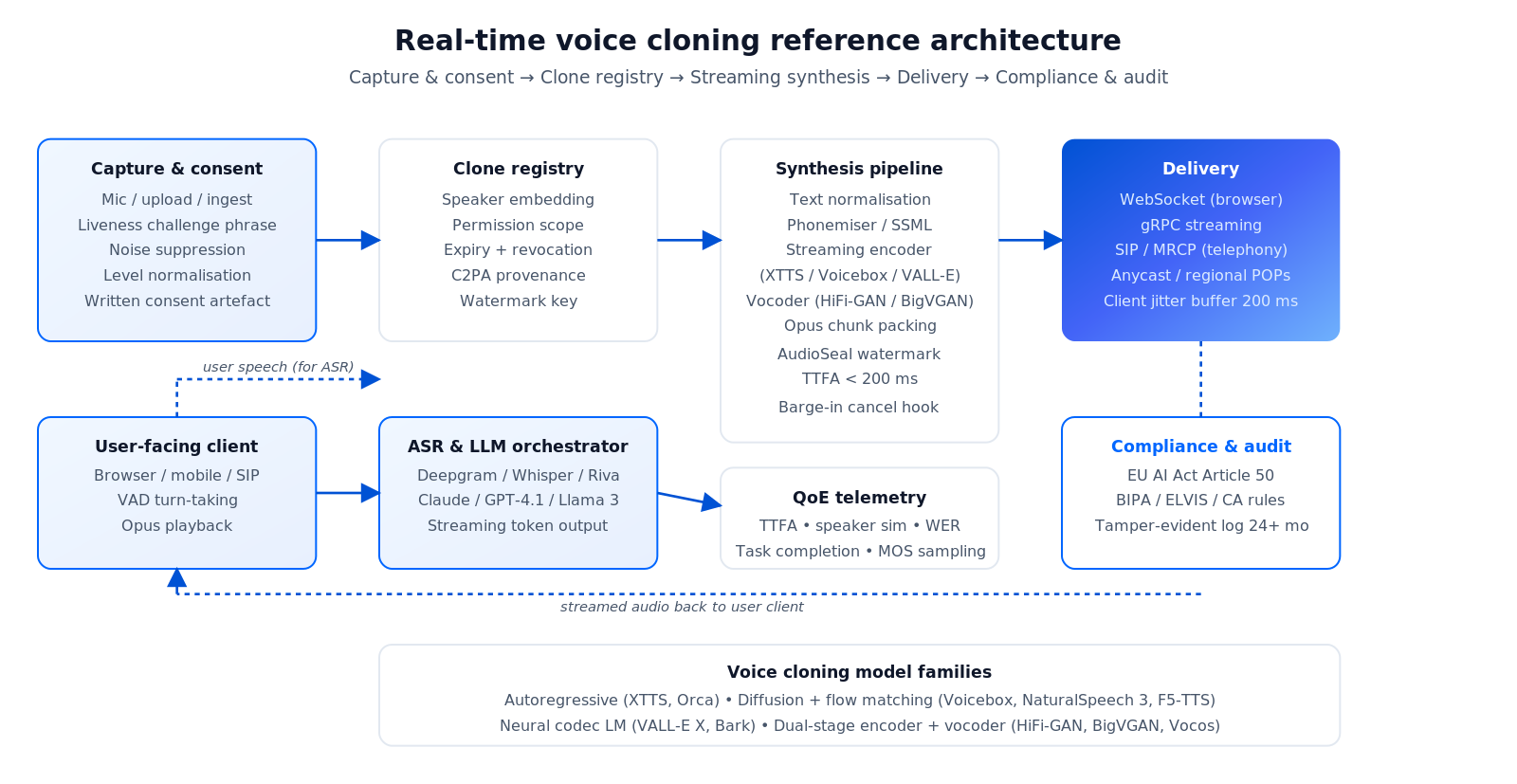
Рисунок 1 — Референсная архитектура: согласие и захват → реестр клонов с водяными знаками → стриминговый синтез TTS → доставка (WebSocket / gRPC / SIP) → слой согласия и аудита, гейтящий каждый запрос.
Захват и согласие
Референсные сэмплы приходят через захват с микрофона, загрузку файла или ингест контента (фильм, подкаст, видео). Каждый сэмпл получает: явное письменное согласие, проверку живости, где спикер читает динамическую фразу, очистку метаданных от персональных данных и качественную предобработку — подавление шума, нормализацию уровня, приведение частоты дискретизации к 24 кГц / 48 кГц, детекцию клиппинга, диаризацию спикеров, если их несколько.
Реестр клонов
Реестр хранит: эмбеддинг спикера, область разрешения (внутреннее / внешнее / дистрибуция), дату истечения, ключ водяного знака, метаданные происхождения (совместимые с C2PA). Каждый запрос на инференс несёт ID клона и проверяется по реестру — истёкшие или отозванные клоны фейлятся по умолчанию.
Пайплайн синтеза
Нормализация текста (числа, даты, аббревиатуры, URL) → фонемизатор / прогон SSML → стриминговый энкодер (авторегрессионный или диффузионный с flow matching) → вокодер (HiFi-GAN, BigVGAN, Vocos) → чанки с кодеком Opus. Каждый чанк проходит через аудиоводяные знаки (AudioSeal, Perth, ElevenLabs AI Authenticity), прежде чем покинуть сервер.
Доставка и barge-in
WebSocket — для связи браузер-сервер, gRPC — для корпоратива и телефонии, SIP-мост — для колл-центров. На клиенте джиттер-буфер 200–300 мс гасит сетевые колебания. Серверный VAD детектит начало реплики пользователя и отменяет TTS / LLM, генерирующиеся в этот момент: barge-in (возможность перебить агента) — обязательная фича для настоящего диалога.
Слой соответствия требованиям
Каждый инференс логирует: вызывающего, ID клона, текст, временную метку, водяной знак, происхождение. Лог аудита защищён от подделки (S3 Object Lock или эквивалент), хранится 12–36 месяцев в зависимости от юрисдикции.
Семейства моделей, реально работающие в продакшене клонирования голоса
Авторегрессионные трансформеры (XTTS-v2, Orca, GPT-подобные TTS). Генерация токен за токеном, низкая задержка (150–200 мс), естественно стримятся. Дефолт для агентов в реальном времени. Дешевле в продакшене, проще дебажить, иногда зацикливаются на очень длинных выводах.
Диффузия + flow matching (NaturalSpeech 3, Voicebox, F5-TTS, MaskGCT). Самое высокое качество и лучшая эмоциональная палитра; по умолчанию медленнее (200–500 мс), но догоняют за счёт ускоренного семплинга. Выбор там, где нужно качество уровня вещания.
Нейронные кодек-языковые модели (VALL-E X, Bark, Outlines-TTS). Предсказывают дискретные аудиотокены GPT-подобной моделью; сильный zero-shot от 3–6 секунд, отличный многоязычный перенос. Лёгкие артефакты от квантизации токенов.
Двухстадийный энкодер + вокодер (HiFi-GAN / BigVGAN / Vocos). Классический модульный пайплайн, до сих пор используется в моделях ElevenLabs эры v2 на огромном масштабе. Хорошо изучен, надёжен, не стримится нативно.
Сайзинг GPU. Одна A10 тянет около 3–5 одновременных zero-shot клонов с задержкой меньше 300 мс; A100 поднимает это до 10–15; H100 — до 25 и больше. Coqui XTTS-v2 на потребительской RTX 4090 даёт 5–10 одновременных потоков для домашних экспериментов. Деплои колл-центров на 1 000 и больше одновременных агентов требуют управляемых API или выделенного парка GPU.
Нужно выбрать между Cartesia, ElevenLabs и self-host?
Поделитесь ожидаемой одновременной нагрузкой, набором языков и правилами резидентности данных. За 30 минут мы дадим рекомендацию по вендору и модель затрат — на основе продакшен-опыта, а не из спеков.
Инженерия задержки: как уложиться в 500 мс end-to-end
В голосовом агенте воспринимаемая задержка — это полный круг: пользователь договорил → ASR транскрибировал → LLM ответила → TTS произнёс. В 2026 году TTS редко становится узким местом. Стек должен агрессивно перекрывать стадии.
1. Стриминговый ASR. Deepgram, Whisper-streaming, NVIDIA Riva ASR возвращают частичные транскрипты быстрее 200 мс. Скармливайте их LLM по мере прихода.
2. Стриминговая LLM. 4-битная квантизированная Llama 3 8B или Claude Haiku стримят первые токены за 150–400 мс. Избегайте моделей без поддержки стриминга — они убивают бюджет задержки.
3. Стриминговый TTS. Как только LLM выдала чанк размером с предложение, отправляйте его в TTS. Cartesia и ElevenLabs выдают первое аудио быстрее 200 мс. Чанкинг по знакам препинания убирает срывы посреди фонемы.
4. Клиентский буфер и VAD. Клиентский буфер 200–300 мс гасит сетевой джиттер. Silero VAD ловит начало реплики пользователя меньше чем за 50 мс — агент успевает замолчать, как только пользователь заговорит снова.
5. Региональные эндпоинты. Anycast или региональный деплой срезает 50–100 мс по сравнению с единственным эндпоинтом в США. Для глобальных продуктов разделяйте APAC и EU в отдельные кластеры.
По стороне ASR пайплайна — особенно в шумных условиях — смотрите наш гайд по точности распознавания речи в шумных средах и обзор инструментов для speech-to-text в стриминге.
Шаблоны интеграции: REST, WebSocket, gRPC, SIP
REST (батч). Отправляете текст — получаете URL MP3. Подходит для озвучки, дубляжа видео, генерации аудиокниг — всего, где 5–15 секунд ожидания приемлемы. Легко кэшируется на CDN.
WebSocket (реальное время). Поддерживается браузером нативно, дружелюбен к фаерволам, время до первого аудио меньше секунды. Дефолт для веб-агентов и разговорных приложений.
gRPC с двусторонним стримингом. Корпоративные агенты и телефонные мосты. Меньше накладных расходов, чем у WebSocket, строгая типизация, поддержка из коробки в NVIDIA Riva и у корпоративных вендоров.
SIP / MRCP-мост. Для подключения к Asterisk, FreeSWITCH, Twilio Voice и другим телефонным стекам. Большинство вендоров клонирования голоса предлагают прямой SIP-адаптер; те, кто не предлагает, требуют медиа-шлюз на вашей стороне.
SSML и стилевые токены. Просодия, эмоция, высота тона, скорость. ElevenLabs v3 и Cartesia принимают пер-чанковые эмоциональные токены. Azure и Google поддерживают SSML. Держите паттерн подсказок одинаковым у всех вендоров — замена обойдётся дёшево.
Соответствие требованиям, согласие и риск дипфейков
Клонирование голоса — один из самых быстро регулируемых AI-доменов. Картина соответствия требованиям в 2026 году: EU AI Act (фаза запретов с февраля 2025, полное вступление в силу с августа 2026, статья 50 о прозрачности дипфейков), Illinois BIPA, Tennessee ELVIS Act, законы Калифорнии о синтетических медиа, рекомендации по этике от ЮНЕСКО. Несоответствие — это банкротство для бизнеса и потенциальная уголовка для физических лиц.
1. Письменное согласие, а не устное. Каждый клонированный голос нуждается в задокументированном разрешении от спикера — область применения (внутреннее / внешнее / коммерческое распространение), дата истечения, процедура отзыва. Храните артефакт согласия рядом с клоном.
2. Проверка живости голоса. Динамическая фраза-вызов при записи сэмпла доказывает, что говорит человек у микрофона, а не запись. Предотвращает согласие на основе украденного аудио.
3. Водяные знаки и происхождение. Незаметные аудиоводяные знаки (AudioSeal, Perth, ElevenLabs AI Authenticity) плюс C2PA Content Credentials на аудиофайле и метаданных. Детектируемость важна и для соответствия требованиям, и для восстановления доверия, если клип стал вирусным.
4. Раскрытие в пользовательских интерфейсах. Статья 50 требует пометки «это аудио сгенерировано с помощью AI» в большинстве потребительских деплоев. Заранее закладывайте это в UX — ненавязчиво, но явно.
5. Отзыв. Спикер должен иметь возможность выключить клон. Это значит — живая проверка реестра на каждом инференсе, а не одноразовый ключ.
6. Законы штатов США. Illinois BIPA трактует голосовые отпечатки как биометрические данные. Tennessee ELVIS Act защищает голосовую узнаваемость. Правила Калифорнии охватывают выборы и интимные изображения. Если продаёте в США — ожидайте, что придётся работать со всеми тремя.
Модель стоимости: рабочий пример для колл-центра на 1 000 агентов
Сценарий. 1 000 одновременных агентов, 8 часов в день, 20 рабочих дней в месяц — примерно 160 000 минут TTS-синтеза в месяц, выдаются через 20 разных клонированных голосов.
| Вариант | За 1 000 символов | В месяц (примерно) | Компромисс |
|---|---|---|---|
| ElevenLabs (управляемый) | ~0,2–0,7 ₽ | ~37 500–120 000 ₽ | Самое высокое качество, сильный инструментарий соответствия |
| Cartesia Sonic | ~0,04–0,07 ₽ | ~6 000–12 000 ₽ | Самая низкая цена, лучшая задержка, более узкий каталог голосов |
| OpenAI Realtime end-to-end | н/д (за минуту) | ~375 000 ₽ (оплата по минутам) | Объединяет ASR + LLM + TTS; самая простая интеграция |
| Self-hosted XTTS / VALL-E | Амортизируется на GPU | ~1,1–2,2 млн ₽ (парк A100 + эксплуатация) | Под контролем, приватно, выходит в плюс выше ~3 000 одновременных |
Добавьте ASR (~0,3 ₽ за минуту на Deepgram), LLM (~0,2–2 ₽ за минуту в зависимости от размера модели) и эксплуатацию. Реалистичная стоимость минуты звонка для среднего стека: 1,5–4 ₽. Для сравнения, человеческие оффшорные операторы первой линии стоят 30–75 ₽ за минуту разговора, так что даже дорогой стек экономит ощутимо на средних объёмах звонков. Эти оценки мы держим консервативными и переоцениваем по реальным метрикам после 30-дневного пилота.
Метрики качества, которые стоит снимать каждую неделю
Сходство голоса. Косинусное расстояние эмбеддингов спикера (ECAPA-TDNN или x-векторы). Цель — ≥ 0,85 для PVC, ≥ 0,75 для zero-shot. Падает, когда тренировочные данные дрейфуют или клон промахивается мимо акцента спикера.
Mean Opinion Score (MOS). Оценка естественности от 1 до 5 живыми слушателями. Цель — ≥ 4,0 для вещания. Собирайте 20 и больше слушателей на снапшот.
Word Error Rate (WER) на ретранскрипции. Прогоните синтезированное аудио обратно через ASR и сравните с исходным текстом. Цель — < 3 % для вещания, < 5 % для агентов. Быстро ловит регрессии произношения.
Ошибки произношения. Сравнение на уровне фонем. Цель — < 2 % для многоязычных деплоев.
Время до первого аудио (TTFA) p50/p95. p50 ниже 200 мс, p95 ниже 500 мс. Пики обычно означают конкуренцию за GPU или холодные старты на управляемых эндпоинтах.
Сохранение эмоций. Оценка слушателями или сравнение через классификатор эмоций. Имеет значение только в дубляже и нарративных сценариях; для плоских колл-центровых агентов можно игнорировать.
Мини-кейс: двуязычный голосовой агент для образовательной платформы
Ситуация. Клиент в e-learning хотел тьютор-агента, говорящего постоянным «брендовым» голосом на английском и испанском, отвечающего быстрее 500 мс и проходящего ревью преподавателей перед запуском каждого нового голоса в работу со студентами. Развернули на их существующей LMS, по соседству с BrainCert.
Что мы построили. Захват согласия с проверкой живости, Professional Voice Cloning для двух брендовых голосов, Cartesia Sonic для стримингового синтеза с TTFA меньше 150 мс, Whisper-streaming ASR с кастомным словарём, заточенным под жаргон курсов, маленький Claude Haiku-агент, оркестрирующий диалог с RAG-поиском по учебным материалам. AudioSeal-водяные знаки на каждом выводе. UI ревью для преподавателей — одобрить или отозвать голос. Лог хранения с 24-месячной защитой от изменений для аудита.
Результат. End-to-end задержка держалась ниже 450 мс в продакшене. Преподаватели одобрили 100 % проверенных голосов к запуску, ни один не отозвали за полгода. Вовлечённость студентов на ветке голосового тьютора заметно выросла по сравнению с текстовой; двуязычный брендовый голос убрал трение от появления «нового синтетического лица». Нужен похожий проект? Позвоните или напишите — пройдёмся по архитектуре.
12-недельный план запуска вашего первого продукта с клонированием голоса
Недели 1–2 — Результат, профиль соответствия требованиям, шортлист вендоров. Зафиксируйте целевую задержку, набор языков, регуляторный регион и один главный KPI. Набросайте процесс получения согласия и механизм отзыва. Сократите список до двух вендоров.
Недели 3–4 — Пайплайн захвата. Выкатите UI сбора сэмплов с проверкой живости, очисткой персональных данных, предобработкой аудио и явными артефактами согласия. Стандартизируйтесь на 24 кГц стерео WAV с шумовым шлюзом на −50 дБ.
Недели 5–7 — Реестр голосов и синтез. Поднимите реестр клонов (истечение, область, отзыв), подключите стриминговый TTS API, сцепите ASR → LLM → TTS с перекрытием стадий, подтвердите TTFA ниже 300 мс на дев-корпусе.
Недели 8–9 — Водяные знаки и UI ревью. Добавьте AudioSeal или эквивалент; выкатите дашборд для ревьюера, где администратор одобряет или отклоняет новые голоса перед запуском.
Недели 10–11 — Barge-in и QA. Добавьте прерывание по VAD, прогоните стресс-тесты на регрессии эха и barge-in, измерьте сходство голоса и WER на отложенной выборке, чините регрессии.
Неделя 12 — Пилот и план раскатки. Пригласите 5 % пользователей; снимите TTFA p50/p95, WER, MOS, запросы на отзыв, юридические инциденты. Расширяйтесь, когда сигналы зелёные.
Пять ловушек, которые топят проекты с клонированием голоса
1. Плохое референсное аудио. Шум, разные частоты дискретизации, реверберация, неровный уровень — всё это за ночь роняет сходство голоса с 0,88 до 0,65. Чините захват раньше, чем модель.
2. Zero-shot в вещании. Трёхсекундного референса достаточно для агента колл-центра, но никогда не хватит для аудиокниги. Используйте PVC там, где качество критично, и закладывайте 30-минутный сбор сэмпла.
3. Нет barge-in. Пользователи говорят поверх агента, и их игнорируют. Голосовые продукты без обработки прерываний кажутся сломанными в первые секунды.
4. Нет согласия или водяных знаков. Регуляторный и брендовый риск. Один инцидент с использованием неавторизованного клона для мошенничества — и продукт снимают. Согласие плюс водяные знаки должны быть архитектурой первой недели.
5. Недостаточный объём GPU. Разработка крутится на одной A10; в продакшене всплеск до 1 000 одновременных агентов; TTFA взлетает, начинается отток. Автоскейлите парк GPU или закладывайте цену управляемого API на реалистичный пик.
Когда не стоит использовать клонированный голос
Есть продукты, которым клон не нужен: общий TTS-голос подойдёт и его проще доказать с точки зрения соответствия требованиям. Не клонируйте, когда пользователи будут счастливы с «Rachel» от ElevenLabs или Studio-голосами Google; не клонируйте, когда не можете получить полноценное согласие; не клонируйте, когда сценарий может быть принят за подмену личности (выборы, юридические коммуникации, финансовая авторизация). Берите клонирование только когда голосовая идентичность — это фича продукта (бренд, доступность, развлечения, локализация) и вы контролируете петлю согласия.
Фреймворк решения — выберите свой стек за пять вопросов
В1. Бюджет задержки end-to-end? < 300 мс → Cartesia Sonic или Inworld. < 500 мс → ElevenLabs, OpenAI Realtime, Azure Personal Voice. < 3 с → пакетный REST у любого крупного вендора.
В2. Уровень качества? Вещание → ElevenLabs PVC или Respeecher. Продуктовые голоса → ElevenLabs few-shot или Cartesia PVC. Временные пользовательские клоны → любой zero-shot.
В3. Регуляторный регион? EU → раскрытие по статье 50, водяные знаки AudioSeal, региональные эндпоинты. США → покрытие BIPA / ELVIS / правил Калифорнии. APAC → локальные контракты по резидентности; проверяйте каждую страну.
В4. Целевой масштаб на второй год? < 500 одновременных → управляемый API. 500–3 000 → управляемый API с объёмным контрактом. 3 000 и больше → оценивайте self-hosted XTTS / Riva, ценовая кривая разворачивается.
В5. Кто эксплуатирует систему? Нет выделенного ML Ops → управляемый вендор от и до. Маленькая ML-команда → управляемый TTS с собственной оркестрацией. Полноценная ML-платформа → DIY на open-source моделях.
Готовы запустить голосовой продукт в реальном времени?
Мы выпустили кастомные голосовые пайплайны в телемедицине, образовании, синхронном переводе и поддержке клиентов. Расскажите о целевом сценарии — спроектируем 12-недельный план с консервативной моделью затрат.
KPI: четыре числа, по которым видно, что голосовой продукт здоров
1. Время до первого аудио p95. Цель — < 500 мс. Единственная метрика, определяющая, ощущается ли диалог естественным.
2. Скользящее среднее сходства голоса. Цель — ≥ 0,85. Падает, когда дообучение дрейфует, референсное аудио деградирует или вы меняете вендора.
3. Процент выполнения задачи (для агентных продуктов). Цель — ≥ 75 % по заявленным интентам. Бизнес-результат, оправдывающий весь стек.
4. Инциденты с согласием на 1 000 клонов. Цель — ноль. Запросы на отзыв, юридические претензии, пробелы в происхождении — любой всплеск этих сигналов означает остановку конвейера.
FAQ
Сколько аудиосэмпла мне на самом деле нужно?
3–6 секунд для zero-shot клонов уровня агента. 30–90 секунд для стабильных брендовых и тьюторских голосов. 30 минут и больше чистого аудио для Professional Voice Cloning. Качество сэмпла важнее голой длины — шумные 5 минут обойдут чистые 30 секунд, только если оба правильно обработаны.
Законно ли клонирование голоса в реальном времени?
Законно — при наличии явного согласия, раскрытия и подтверждения происхождения. Незаконно — для подмены личности, неавторизованного использования голосовой узнаваемости, вмешательства в выборы и большинства форм мошенничества. EU AI Act, Illinois BIPA и Tennessee ELVIS Act формализуют границы. Всегда выстраивайте процесс получения согласия в первую очередь.
У какого вендора лучшая задержка сегодня?
Cartesia Sonic Turbo лидирует с ~40–90 мс до первого аудио, Inworld TTS-1.5 Max рядом. ElevenLabs v3 даёт 150–300 мс с более широкой поддержкой языков. Для end-to-end агентов OpenAI Realtime упаковывает ASR + LLM + TTS примерно в 500 мс с самой простой интеграцией.
Можно ли self-host клонирование голоса?
Да. Coqui XTTS-v2 и варианты VALL-E X крутятся на потребительских GPU (RTX 4090) на малом масштабе и на парках A100 / H100 в продакшене. Self-host окупается по сравнению с управляемыми API примерно с 3 000 одновременных потоков или для деплоев с ограничениями по приватности (здравоохранение, оборонка, юридические сервисы).
Каков минимальный жизнеспособный процесс согласия?
Письменный документ о согласии, динамическая фраза-вызов на записи сэмпла, дата истечения на каждом клоне, кнопка отзыва в дашборде пользователя, водяной знак на каждом выводе, лог с защитой от изменений на 24 месяца и больше. Пропустите хоть один пункт — и вы в одном инциденте от кризиса.
Как работать с несколькими языками?
Берите многоязычную zero-shot модель (XTTS-v2, ElevenLabs Multilingual v2, Cartesia Sonic, Camb.ai) для кросс-языкового переноса с одного референсного сэмпла. Для максимальной достоверности по каждому языку обучайте отдельные дообучения на одном и том же спикере. Проверяйте на вариантах акцентов, а не только на доминирующем диалекте.
Как понять, что клип — это дипфейк-клон?
Три слоя: детекция водяного знака (AudioSeal / Perth / ElevenLabs AI Authenticity), проверка происхождения (C2PA credentials) и классификатор дипфейков (Resemble Detect, Pindrop, AI or Not). Ни один слой не идеален; комбинация поднимает детектируемость к 95 % и выше.
Может ли Фора Софт построить продукт с клонированием голоса для нас?
Да. Мы строим голосовые пайплайны под ключ: захват, согласие, реестр клонов, стриминговый синтез, barge-in, водяные знаки, аудит-логи, ревью соответствия требованиям. Типичный объём — 8–12 недель на продакшен-пилот, 12–20 недель на полноценное коммерческое развёртывание. Позвоните или напишите, чтобы обсудить ваш проект.
Что почитать дальше
TTS-вендоры
6 лучших библиотек синтетического голоса для разработки приложений
Широкий ландшафт TTS, который соседствует с клонированием голоса.
Аудиостек
7 лучших AI-инструментов для аудиоприложений
ASR, улучшение звука, шумоподавление и полный аудиопайплайн.
Синхронный перевод
Разработка платформы AI-синхронного перевода в 2026 году
Соседний гайд по многоязычным голосовым продуктам.
Колл-центр
AI-ассистенты звонков: сторонние API для бизнеса
VoIP-мост, barge-in и слой телефонии для клонированных голосов.
ASR
Точность распознавания речи в шумных средах
Решения по апстрим-ASR, определяющие общую задержку агента.
Готовы внедрить клонирование голоса в реальном времени в свой продукт?
Клонирование голоса в реальном времени — это уже работающая в продакшене технология 2026 года. Время до первого аудио меньше 300 мс доступно у нескольких вендоров, качество в уровне PVC соответствует вещанию, юнит-экономика складывается в колл-центрах, доступности, дубляже, играх, образовании и локализации медиа. Продукт, который доходит до продакшена, отличается от того, что застрял в пилоте, дисциплиной по четырём слоям: подобрать уровень клонирования под задачу, уложиться в бюджет задержки за счёт перекрытия ASR/LLM/TTS, заложить согласие и водяные знаки как архитектуру первого класса, измерять сходство голоса и WER на еженедельной основе.
Если вам нужна команда, которая выпустила это в телемедицине, образовании, синхронном переводе и поддержке клиентов и может дать консервативную модель затрат с реалистичным 12-недельным таймлайном, позвоните или напишите нам. Наш Agent Engineering-процесс быстро выводит первый продакшен-пилот к реальным пользователям.
Соберём ваш продукт с клонированием голоса
21 год инженерии мультимедиа и AI, 625+ выпущенных продуктов. Бронируйте 30 минут — уйдёте с рекомендацией по вендору, реалистичной стоимостью минуты и 12-недельным планом под ваш сценарий.