Главное
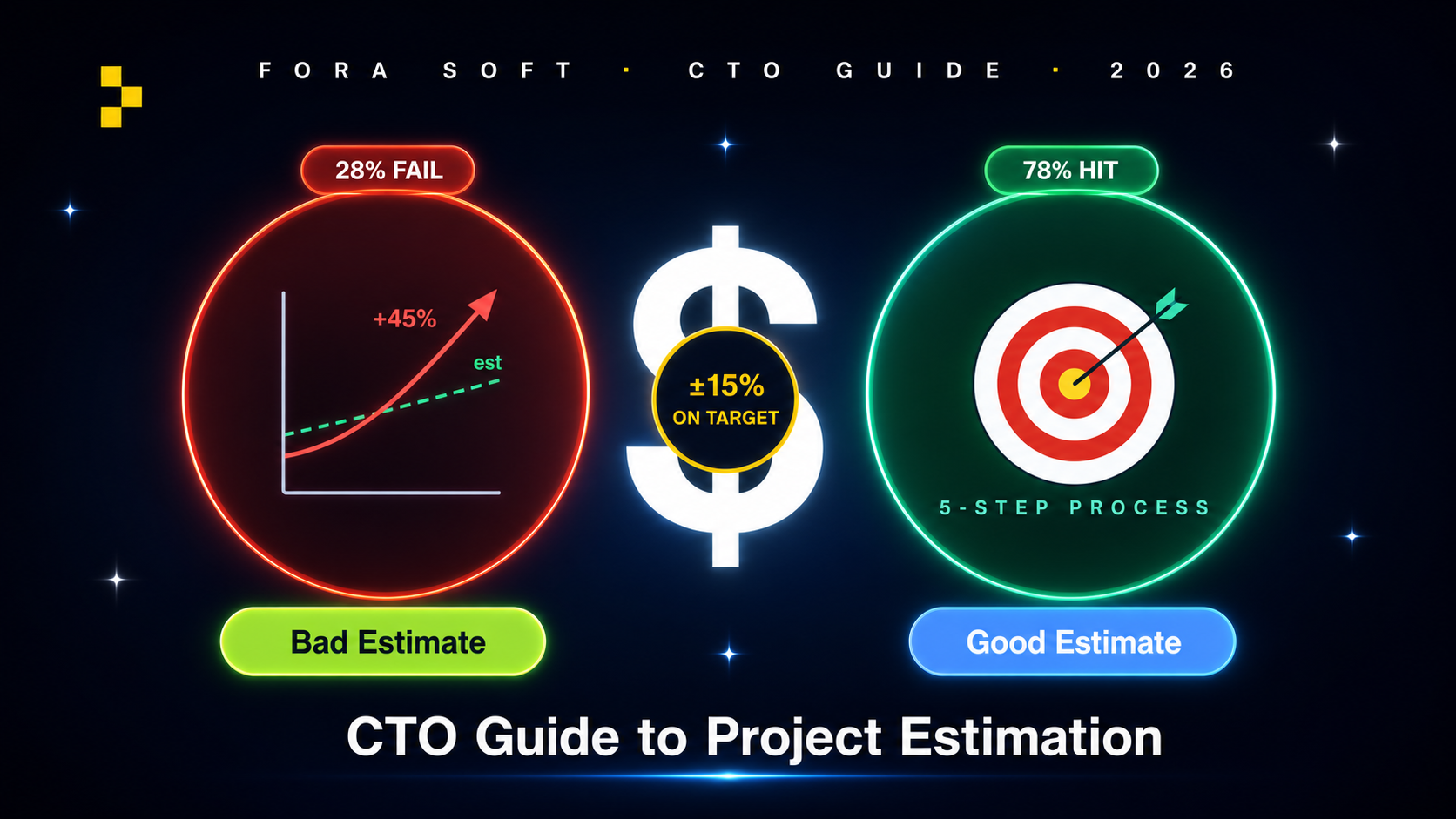
• 28 % проектов не укладываются в смету. Данные исследования PMI, подтверждённые многократно по разным отраслям. Большинство провалов — не инженерные ошибки, а ошибки дисциплины оценки.
• Пять корневых причин предсказуемы. Размытые требования (главный убийца), якорение на оптимизме, игнорирование нефункциональных требований, недооценка рисков сторонних зависимостей, «скидка от основателя». Все пять встречаем каждый квартал.
• Bottom-up даёт лучшую точность при ясном объёме. Top-down по аналогам — быстрее всего, но даёт меньше всего гарантий. PERT с тремя точками выручает при неопределённости. Метод подбирают под характер неизвестных.
• Скрытые расходы — 30–50 % от итога. Discovery, проектное управление, проверка кода, аудиты на соответствие требованиям, дежурства — редко выделены отдельной строкой в коммерческом предложении. Подрядчик, который их перечисляет, честнее того, который умалчивает.
• Качество брифа определяет качество оценки. Бриф на 2 страницы даёт пятикратный разброс оценок между подрядчиками. Бриф из 12 разделов с NFR и реестром рисков — разброс в пределах 15 % и наглядно показывает, кто из подрядчиков действительно вник в задачу.
Почему этот гид написала Фора Софт
С 2005 года Фора Софт выпустила более 625 проектов для 400+ клиентов. Мы оцениваем порядка 80 новых проектов в год. Доля проектов, сданных в пределах 15 % от исходной оценки, у нас около 78 % — заметно выше планки PMI. Те 22 %, что промахиваются, почти всегда упираются в один из пяти провалов дисциплины оценки (разбор — в §3).
Знаковые проекты, на которых мы калибруем оценки: BrainCert (e-learning-платформа с годовой выручкой 750 млн ₽), StreamLayer (NBC, CBS, Red Bull), CirrusMED (HIPAA-телемедицина), VALT (650+ юридических организаций), TransLinguist (NHS Великобритания), EyeBuild (видеонаблюдение на солнечной энергии с AI). По каждой из этих оценок у нас есть post-mortem, который мы используем в следующих расчётах.
Если вы CTO, основатель или вице-президент по продукту и сейчас собираете коммерческие предложения от подрядчиков, этот гид подскажет, какой метод оценки соответствует вашим неизвестным, где прячутся скрытые расходы, какие красные флаги ловить в RFP подрядчиков и как написать бриф, который сжимает разброс оценок.
Нужна оценка с фиксированной ценой, которая действительно держится?
Пришлите бриф или раннее ТЗ. Через 5 рабочих дней вернёмся с разбором оценки в 5 шагов. Бесплатно.
Цифра 28 % — что показало исследование PMI
Исследование Pulse of the Profession от Project Management Institute показало: 28 % провалов проектов связаны с неточными оценками стоимости. Отчёт CHAOS от Standish Group называет ещё более жёсткую цифру — около 60 % программных проектов перерасходуют исходный бюджет минимум на 25 %. По данным McKinsey 2020 года (выборка из 5 400 ИТ-проектов), крупные проекты в среднем уходят за бюджет на 45 %, опаздывают на 7 % и приносят на 56 % меньше ценности, чем планировалось.
Конкретное число зависит от источника, но вывод одинаковый: дисциплина оценки — это водораздел между проектами, которые сдаются в бюджет, и проектами, по которым через полгода приходится объясняться на уровне совета директоров.
Пять причин, по которым оценки рушатся
1. Размытые требования (убийца №1). «Сделайте нам приложение как Uber для X» — это не бриф. За такой формулировкой скрыто 50 решений: платежи, KYC, разрешение споров, диспетчеризация, динамические тарифы — и каждое из них даёт десятикратный разброс стоимости в зависимости от выбранного варианта.
2. Якорение на оптимизме. Первая прозвучавшая оценка становится точкой отсчёта. Если подрядчик сказал «3 месяца» и ваш CFO это услышал, любая последующая оценка будет сравниваться с тремя месяцами и отклоняться, если окажется больше. Настоящие оценки — это диапазоны, а не одно число.
3. Игнорирование нефункциональных требований. «Сделать функцию» — это половина задачи. «Сделать так, чтобы доступность была 99,95 %, чтобы соблюдался GDPR, чтобы выдерживало 100 тыс. DAU, чтобы работало на iOS 14+» — вторая половина. Оценки, которые игнорируют NFR, теряют 30–60 % работы.
4. Недооценка рисков сторонних зависимостей. «Мы интегрируемся с API подрядчика X» предполагает, что у этого API есть документация, что он стабилен и подходит под BAA. Однажды мы потеряли 6 недель, потому что сторонний API упёрся в лимиты, о которых нигде не было ни слова в документации.
5. «Скидка от основателя». Когда оценку даёт сам основатель, побеждает оптимизм. Основатели не закладывают запас, потому что хотят, чтобы проект был запущен. Поэтому мы всегда отдаём внутренние оценки дороже 7,5 млн ₽ на независимую проверку старшему инженеру.
Пять методов оценки
| Метод | Затраты | Точность | Когда применять |
|---|---|---|---|
| Bottom-up | Высокие | Высокая (±15 %) | Объём ясен, контракт с фикс. ценой |
| Top-down по аналогам | Низкие | Средняя (±30 %) | Питч продаж, оценка-диапазон |
| Параметрический | Средние | Средне-высокая | Повторяемые типы проектов (e-comm, SaaS) |
| PERT с тремя точками | Средние | Высокая при неопределённости | Часть неизвестных, нужен доверительный интервал |
| Монте-Карло | Очень высокие | Очень высокая | Корпоративное бюджетирование с учётом рисков |
Bottom-up. Декомпозируйте до пользовательских историй или функциональных точек, оцените каждую, сложите, добавьте накладные расходы и резерв на риски. Дефолтный выбор для контрактов с фиксированной ценой. Затраты времени: 1–3 дня для проекта на 15 млн ₽.
Top-down по аналогам. «Проект X для клиента Y занял 6 месяцев и 18 млн ₽; этот — похожий». Полезно для первичных питчей, опасно для контрактов. Разброс ±30 % при оптимистичном сценарии.
Параметрический (COCOMO II, FPA). Оценка строится по модели с весовыми параметрами — строки кода, функциональные точки, факторы сложности, продуктивность команды. Требует исторических данных для калибровки. Внутри мы используем облегчённый FPA для первичной проверки на здравый смысл.
PERT с тремя точками. Оцените оптимистичный (O), наиболее вероятный (M) и пессимистичный (P) сценарии. Считайте среднее по PERT = (O + 4M + P) / 6 и стандартное отклонение = (P − O) / 6. Получите доверительный интервал. Применяйте, когда есть значимые неизвестные, но бюджета на полный Монте-Карло нет.
Симуляция Монте-Карло. Распределение вероятностей для каждой задачи, прогон 10 000 виртуальных проектов, на выходе — кривая доверия. Применяется только на корпоративных проектах от 75 млн ₽ с серьёзными рисками.
Берите bottom-up, когда: объём зафиксирован, контракт с фикс. ценой и есть 1–3 дня на декомпозицию.
Берите top-down по аналогам, когда: идёт первый разговор, продающий питч, нужна оценка-диапазон. Проговаривайте 30-процентный разброс открыто.
Берите PERT, когда: в проекте 1–3 модуля с высокой неопределённостью. Применяйте PERT к ним, остальное считайте bottom-up.
Берите Монте-Карло, когда: проект уровня совета директоров, бюджет от 75 млн ₽, много неопределённых зависимостей и есть PMO, который умеет читать такие отчёты.
Разбор примера — MVP телемедицины
Реальный MVP телемедицины, который мы оценивали в начале 2025 года (анонимизировано). Объём: видеоконсультации с поддержкой HIPAA, расписание, портал пациента, портал врача, передача биллинга в существующую PMS. Аудитория: 10 врачей, 3000 пациентов, только США, только английский.
Декомпозиция bottom-up.
| Модуль | Истории | Человеко-недели |
|---|---|---|
| Discovery + дизайн | — | 8 |
| Портал пациента (web + iOS + Android) | 38 | 22 |
| Портал врача (web) | 31 | 14 |
| Видеоконсультация (mediasoup, self-hosted) | 12 | 10 |
| Расписание + напоминания | 15 | 6 |
| Интеграция биллинга с PMS | 8 | 5 |
| Контроли HIPAA + аудит | — | 6 |
| Подытог (инженерия) | 104 | 71 |
| + QA (25 %) | 18 | |
| + PM + архитектор (12 %) | 9 | |
| + Резерв на риски (15 %) | 11 | |
| Итого | 109 человеко-недель ≈ 28 календарных недель командой из 4 человек |
При типичной смешанной ставке среднеценовой команды в США/ЕС это даёт диапазон примерно 18–31 млн ₽ в зависимости от состава команды и доли сениоров. Реальный проект, который мы выпустили, попал в нижнюю часть диапазона за счёт переиспользования паттернов Agent Engineering из CirrusMED.
Разбор примера — OTT-платформа стриминга
OTT-платформа с VOD и live-стримингом, с собственными брендированными приложениями для web, iOS, Android и Connected TV (Roku, Fire TV, Apple TV). Стартовый каталог — 10 000 часов, расписание прямых эфиров, рекламная модель плюс подписочный тариф.
Почему одного bottom-up недостаточно. У OTT сильно плавающие расходы на инфраструктуру (CDN, кодировщик, хранилище), эффорт на каждую платформу масштабируется по-разному, а работа с правами на контент плохо поддаётся оценке. Мы используем bottom-up для уровня приложений и параметрический метод (на CCU и на час) для инфраструктуры.
Инженерия bottom-up: ~190 человеко-недель на v1 по 5 платформам (web, iOS, Android, tvOS, Roku). С накладными и резервом на риски — около 260 человеко-недель, по типичной смешанной ставке это ~48–82 млн ₽ в зависимости от состава команды.
Инфраструктура (параметрический расчёт). CDN по 1,8 ₽/ГБ × ожидаемые 50 ТБ трафика в месяц = 93 тыс. ₽/месяц. Кластер транскодирования (100 часов нового контента в неделю) — ~112 тыс. ₽/месяц. Хранилище (10 тыс. часов × 1,5 ГБ/час) — ~22 тыс. ₽/месяц. DRM, аналитика, рекламный сервер — ~150 тыс. ₽/месяц. Итого инфраструктура: ~375 тыс. ₽/месяц на v1, дальше масштабируется по трафику.
Права на контент (вне оценки). Лицензирование на каждый тайтл сильно варьируется; CTO стоит закладывать ноль в инженерное предложение и бюджетировать отдельно. Включение стоимости прав в инженерную оценку — красный флаг.
Коммуникация диапазона. Диапазон 48–82 млн ₽ отражает 70 % доверительный интервал. CTO выносит этот диапазон на совет директоров с явным списком допущений, а не одним числом.
Хотите bottom-up оценку своего проекта?
Пришлите бриф или продуктовое ТЗ. Через 5 рабочих дней вернёмся с bottom-up оценкой в 5 шагов: с NFR и реестром рисков. Бесплатно.
Скрытые расходы, о которых никто не пишет в смете
Discovery / фаза погружения (5–15 % от проекта). Полноценный архитектурный дизайн, прототип, план спринтов. Подрядчики, которые пропускают этот этап и сразу садятся писать код, добирают его потом через change-orders.
Накладные расходы на проектное управление (10–15 %). Планирование спринтов, стендапы, ретро, демо-дни, коммуникация со стейкхолдерами. Типичное соотношение — «1 PM на 4 инженеров»; более дешёвые подрядчики часто прячут это в инженерных ставках.
Старший ревью кода + архитектурный надзор (8 %). Лид-инженер или архитектор выборочно проверяет PR, валидирует архитектурные решения, менторит мидлов. Снижает технический долг в долгую; редко указывается отдельной строкой.
Аудиты на соответствие требованиям. Оценка рисков по HIPAA — 375 тыс. – 1,1 млн ₽. Аудит SOC 2 Type 2 — 1,5–4,5 млн ₽. Пентест — 750 тыс. – 1,8 млн ₽ за цикл.
Продакшн-мониторинг + дежурства. Datadog или New Relic (от 37 тыс. до 375 тыс. ₽/месяц на старте). PagerDuty — 1 500 ₽ за пользователя. Дежурство старшего инженера (обычно 1 неделя из 4).
Сторонние сервисы. Twilio, SendGrid, Stripe, Auth0, Algolia, векторное хранилище. На этапе оценки про них легко забыть; в сумме на v1 это 37 тыс.–375 тыс. ₽/месяц.
Поддержка и исправление багов после запуска. Закладывайте 15–25 % от исходного бюджета проекта в год на поддержание системы в рабочем состоянии.
Красные флаги в RFP — 7 признаков плохой оценки
1. Одно число, без диапазона. «15 млн ₽» без доверительного интервала означает, что подрядчик не задумывался о неопределённости. Настоящие оценки приходят диапазонами или с явной строкой резерва на риски.
2. В разбивке нет NFR. Если в разбивке перечислены функции, но нет доступности, безопасности, производительности, масштабирования, доступности для людей с ограниченными возможностями — подрядчик отнесёт это к out-of-scope, когда требования всплывут.
3. Часы, которые округлены до тысяч. «Портал пациента: 200 часов, портал врача: 150 часов». Настоящие bottom-up оценки дают странные числа (87 часов, 142 часа), потому что складываются из отдельных историй.
4. Discovery не указан в коммерческом предложении. «Мы можем начать кодить со следующей недели» означает отсутствие шага архитектурного дизайна. Перепроектирование в середине проекта обойдётся в 3–5 раз дороже, чем стоило бы discovery.
5. Подрядчик принял бриф без вопросов. Сильная команда обязательно оспорит размытые требования, попросит уточнить NFR, предложит альтернативные архитектуры. Если подрядчик ответил «конечно, сделаем ровно то, что вы написали» — у вас проблема.
6. Разброс предложений между подрядчиками больше 3 раз. Если оценки лежат в диапазоне от 6 млн до 22 млн ₽, бриф размытый. Перепишите бриф плотнее и пересоберите оценки; не усредняйте.
7. Фикс. цена без процедуры change-orders. Реальные контракты с фикс. ценой включают процесс change-orders — то, как тарифицируется расширение объёма. Без этого подрядчик будет молча есть ваши изменения, пока не упрётся в потолок, а потом выкатит шестизначный change request на 4-м месяце.
Как написать бриф, по которому дают точные оценки
Бриф из 12 разделов сжимает разброс оценок между подрядчиками с пятикратного до полуторного. Вот эти разделы:
1. Контекст компании — кто вы, что делаете, текущий размер, стадия финансирования.
2. Проблема и пользователи — какую боль пользователя вы решаете, кто эти пользователи, как они справляются сегодня.
3. Функциональный объём — пользовательские истории или эпики с критериями приёмки. Не функции — результаты.
4. Нефункциональные требования (NFR) — производительность (целевая задержка, пропускная способность), безопасность (аутентификация, шифрование, требования регулятора), масштаб (DAU, пиковая конкуренция), доступность (целевой SLA), доступность для людей с ограниченными возможностями (уровень WCAG).
5. Технологические предпочтения — либо явное «на усмотрение подрядчика». Указать «Node + React + Postgres» нормально, если у вас есть позиция; написать «предложите подходящий стек» тоже нормально.
6. Сроки и ключевые точки — что является жёсткой датой (запуск, продление контракта), а что — пожеланием.
7. Бюджетные рамки — диапазон, фиксированная сумма, T&M. Озвучивайте ограничения открыто; иначе подрядчики тратят и ваше, и своё время на угадывание.
8. Критерии оценки — какие факторы влияют на ваше решение (цена, релевантность портфолио, техническая глубина, коммуникация, локация).
9. Условия по интеллектуальной собственности и данным — ваши ожидания по владению кодом, локализации данных, субподряду, депонированию исходного кода.
10. Требования к подаче предложения — формат, дедлайн, кто рассматривает, сроки решения.
11. Реестр рисков — известные неизвестные, которые подрядчик должен оценить отдельно. Признак зрелого заказчика; задаёт честные ожидания.
12. Ожидания по референсам и портфолио — какие прошлые работы вы хотите увидеть.
5-шаговый процесс оценки в Фора Софт
Шаг 1: разбор брифа. Часовой созвон со старшим инженером и руководителем поставки. Подтверждаем объём, NFR, жёсткие ограничения. Подбираем аналоги из нашего портфолио в 625 проектов.
Шаг 2: top-down проверка на здравый смысл. 30 минут. Сравниваем с 2–3 аналогичными проектами. Получаем оценку-диапазон как верхнюю границу для последующего bottom-up.
Шаг 3: декомпозиция bottom-up. 1–3 дня. Раскладываем на пользовательские истории или эпики; оцениваем каждую в стори-поинтах; пересчитываем в человеко-недели через скорость команды. Старший инженер делает ревью.
Шаг 4: реестр рисков и резервы. Выделяем именованные риски (сторонние зависимости, регуляторика, неизвестные по производительности) и оцениваем каждый. Добавляем 10–20 % общего резерва на «неизвестные неизвестные».
Шаг 5: независимое ревью старшего инженера. Другой старший инженер (не тот, кто оценивал) проходит по разбивке и спрашивает «почему такое число?» по каждой строке. Обычно после этого шага оценка корректируется на 5–15 %.
Как выбрать метод оценки за 5 вопросов
В1. Контракт с фиксированной ценой или T&M? Фикс. цена требует bottom-up. T&M допускает top-down или PERT.
В2. Насколько объём зафиксирован? Жёстко зафиксирован → bottom-up. Существенные неизвестные → PERT с тремя точками. Объём открыт → сначала проведите discovery; оценивать открытый объём безответственно.
В3. Размер проекта? До 3,7 млн ₽: top-down подойдёт. 3,7–37 млн ₽: bottom-up. 37–375 млн ₽: bottom-up + PERT на неопределённых модулях. От 375 млн ₽: полный Монте-Карло.
В4. Делали ли вы (или подрядчик) подобные проекты раньше? Да → оценка по аналогам надёжна. Нет → ждите разброса от 30 % и закладывайте резервы соответствующим образом.
В5. Кто читает оценку? Команда инженеров → bottom-up с детализацией по стори-поинтам. Совет директоров → оценка-диапазон с доверительными интервалами и явным списком допущений. Если читают и те и другие — готовьте оба представления.
Подводные камни
1. Оценка без архитектора. Старший архитектор видит риски, которых не видит ни джун, ни PM — сложность интеграций, неизвестные по производительности, странности сторонних API. Архитектор должен подписать любую оценку.
2. Не различать «идеальную» и «реальную» продуктивность. «Идеальный день» старшего инженера — это 5–6 продуктивных часов после встреч, ревью кода и отладки. Закладывайте запас; не считайте по 8 часов в день.
3. Забывать про интеграционное тестирование. Юнит-тесты обычно оцениваются вместе с функциями. End-to-end тесты, интеграционные тесты, нагрузочные тесты часто забываются и в сумме дают 10–15 % от общего объёма работ.
4. Недооценивать миграцию данных. Перенос исторических данных редко «просто скрипт». Маппинг схем, качество данных, крайние случаи, репетиции, откаты — для любой нетривиальной системы это отдельный проект.
5. Игнорировать деплой и DevOps. CI/CD-пайплайны, инфраструктура как код, настройка мониторинга, усиление безопасности — в сумме 5–10 % от объёма проекта, которые часто отсутствуют в оценках.
Какие KPI измерять
KPI качества. Точность оценки: факт / план в пределах 15 % минимум на 75 % проектов. Доля израсходованного резерва на риски (цель: меньше 70 %; если регулярно превышаете, значит резерв слишком маленький).
Бизнес-KPI. Конверсия в победу по оценённым проектам (цель: 30–45 % по тёплым лидам, меньше по холодным). Маржа факт против плана (цель: в пределах 5 % от модели). Среднее время от RFP до оценки (цель: до 7 дней для проектов на 15 млн ₽).
KPI надёжности. Процент проектов с post-mortem по оценке (цель: 100 %; разбираем каждый). Количество change-orders на проект (большое число сигнализирует о плохо проработанном объёме).
Когда не нужно формализовать оценку
Полноценный исследовательский R&D. Если непонятно, заработает ли вообще выбранный технический подход, оценить работу нельзя. Запустите спайк на 2 недели в фиксированный таймбокс, а потом оценивайте. Не делайте вид, что спайка нет.
Глубокая итеративная продуктовая разработка. Ранний этап MVP, где следующий спринт зависит от обратной связи на этом. T&M с недельными чекпоинтами обыграет фикс. цену, ошибочную уже к 3-й неделе.
Тактика на бюджет до 750 тыс. ₽. Недельная функция не нуждается в пятишаговом процессе оценки. Оценка старшего инженера «на глаз» с запасом 30 % сдаётся нормально.
FAQ
Насколько точны bottom-up оценки?
В пределах ±15 % на проекте, где объём зафиксирован, а команда уже делала аналогичные задачи. С менее опытной командой или плавающим объёмом реалистично ±30 %. Всегда называйте диапазон, а не середину.
По какой ставке считать бюджет?
Среднеценовая команда в США: 11 250–18 750 ₽/час по смешанной ставке. Команда в ЕС/Великобритании: 6 750–13 500 ₽/час. Бутики Восточной Европы / Латинской Америки / Индии: 3 750–9 000 ₽/час. Сверяйтесь с портфолио: более низкие ставки при том же качестве работы существуют, но редко.
Меняет ли картину Agent Engineering?
Да. Современная инженерия с AI-помощниками (мы используем её внутри) ощутимо сокращает усилия на бойлерплейт, скаффолдинг, генерацию тестов и рефакторинг. По сравнимому объёму обычно сдаём на 15–25 % быстрее, чем по базе 2022 года. Экономия неравномерна: работа старшего архитектора и discovery почти не сжимается; задачи мидл-уровня по кодированию — заметно.
Каким должен быть резерв на риски?
10–15 % на хорошо проработанных проектах с опытной командой. 20–30 % на новой территории. 50 %+ на R&D-задачах, где неизвестное доминирует. Будьте прозрачны: скрытые резервы подрывают доверие, когда проект сдаётся за 105 % от сметы.
Всегда ли стоит выбирать самое дешёвое предложение?
Нет. Самое дешёвое часто упускает NFR, пропускает discovery или прячет скрытые расходы в change-orders. Смотрите на разброс предложений: если он в пределах 30 % между подрядчиками и у самого дешёвого тот же набор NFR и тот же объём discovery — возможно. Если самое дешёвое на 50 % ниже медианы — уточните, за счёт чего.
Фикс. цена против T&M — что лучше?
Фикс. цена — для ясного объёма (аудит на соответствие, миграция MVP, чётко описанная функция). T&M — для размытого объёма (ранний MVP, R&D). Гибрид (T&M на discovery, фикс. цена на сборку) встречается чаще всего и обычно лучший вариант.
Что делать, если бюджет ниже оценки?
Резать объём, не качество. Подрядчик, который снижает цену на 30 % без сокращения объёма, либо ест маржу (и возьмёт своё через change-orders), либо срезает углы. Подрядчик, который предлагает уменьшить объём под бюджет — например, «пропустим Android в v1, выпустим сначала iOS» — ведёт себя честно.
Можно ли получить оценку, не делясь полным ТЗ?
Оценку-диапазон — да. Bottom-up под фикс. цену — нет. Часть подрядчиков даст оценку по одностраничному брифу — разброс будет 50 %+, а разницу они доберут через change-orders. Решать вам, приемлем ли такой разброс.
Что почитать дальше
Оценка
Почему оценки сроков разработчиков не всегда работают
Сопутствующий материал о человеческой стороне оценки.
MVP
Резать функции и запускаться раньше
Тактики сокращения объёма, которые защищают вашу оценку.
Соответствие
Стоимость HIPAA + SOC 2
Скрытые расходы на соответствие требованиям, которые ломают бюджеты телемедицины.
Стоимость
Как сократить расходы на программный проект
Сопутствующая статья про честные тактики снижения стоимости.
PM
Зачем нужен PM
Накладные расходы PM — одна из категорий скрытых затрат, которую обязательно нужно учитывать.
Готовы запустить проект, который попадёт в оценку?
28 % проектов не укладываются в смету, и причины предсказуемы: размытые требования, оптимизм, забытые NFR, риски сторонних зависимостей, «скидка от основателя». Избегать их — не вопрос удачи, а вопрос процесса. Bottom-up для фикс. цены, top-down для продающих питчей, PERT при неопределённости, Монте-Карло для корпоративного масштаба.
Скрытые расходы — 30–50 % от итога. Качество брифа определяет качество оценки. Подрядчики, которые оспаривают ваш объём, прямо перечисляют NFR и дают диапазоны с доверительными интервалами — это те, кто попадает в бюджет. Дешёвые предложения, которые пропускают эти шаги, в итоге обходятся дороже через change-orders.
Хотите 5-шаговую bottom-up оценку своего проекта?
Пришлите бриф, NFR и целевую дату запуска. Через 5 рабочих дней вернёмся с bottom-up разбивкой, реестром рисков и доверительным интервалом. Бесплатно.
