
Ключевые выводы
• Анализ эмоций в речи в реальном времени окупается в трёх сценариях. Контроль качества в контакт-центре, триаж в ментальном здоровье и телемедицине, а также оценка вовлечённости внутри живых видеопродуктов — в каждом случае измеримый рост CSAT, completion rate или снижение рисков за 90 дней.
• Лучшие модели 2026 года дают 70–78 % F1 на чистом аудио и 62–68 % на реальных звонках. Всё, что выше 80 % на слайде вендора, почти всегда измерено на тщательно отобранной выборке: проверяйте на своих собственных записях.
• Берите managed API, чтобы запуститься за недели; стройте сами, только если у вас больше ~1 млн минут в год. AWS Transcribe Call Analytics стоит 0,32 ₽/мин, Hume AI — 3,75 ₽/мин. Ниже 100 тыс. звонков в месяц размещённый пайплайн SER выигрывает у in-house по TCO.
• Комплаенс — тихий убийца проекта. EU AI Act запретил распознавание эмоций на рабочем месте и в образовательных учреждениях с февраля 2025 года; голосовые эмоции также считаются «биометрическими данными» по статье 9 GDPR и PHI по HIPAA, если связаны с терапией.
• Фора Софт уже довела это до прода. Мы интегрируем аудио-, лицевые и поведенческие сигналы в таких платформах, как Meetric (AI sales video, привлечено 21 млн SEK) и приложение новостных дайджестов, которое объединяет голосовой и лицевой анализ эмоций. Позвоните нам или напишите — обсудим ваш сценарий.
Зачем Фора Софт написала этот гид
Большинство статей об анализе эмоций в речи в реальном времени читаются как рекламный буклет вендора: «распознаём радость, грусть, гнев», «точность до 98 %», ни одной цифры, на которую можно опереться при принятии решения. Мы пошли другим путём. Фора Софт делает мультимедиа-продукты с AI с 2005 года, и за последние пять лет наши команды интегрировали распознавание эмоций речи и лиц в платформы для живого видео, телемедицинские приложения, EdTech-сервисы и инструменты для обучения продавцов. Мы знаем не только парадные истории успеха, но и реальные режимы отказа.
Пара показательных продакшен-проектов: Meetric — AI-платформа для продаж с финансированием 21 млн SEK, которая объединяет компьютерное зрение, аудиоанализ и сигналы взаимодействия, чтобы оценивать вовлечённость и в реальном времени подсказывать продавцам в Zoom, Google Meet и Teams; приложение новостных дайджестов, которое записывает голосовые заметки и одновременно прогоняет аудио и лицо через анализ эмоций, чтобы строить недельные тренды настроения; и VocalViews — платформа видеоисследований рынка с более чем 1 млн пользователей, где тональность говорящего важнее буквального текста сказанного. Фора Софт также держит 100 %-й рейтинг успешных проектов на Upwork и отбирает примерно одного из 50 инженеров, которые откликаются.
Этот гид — то, что мы рассказываем потенциальным клиентам на дискавери-звонке: где распознавание эмоций речи (speech emotion recognition, SER) реально сдвигает метрику, где нет, что брать готовым, а что строить, как выглядит честный пайплайн и как остаться по правильную сторону GDPR, HIPAA и EU AI Act. Используйте оглавление справа, чтобы сразу перейти к нужному разделу.
Нужно добавить анализ эмоций в речи в реальном времени в ваш продукт?
Расскажите нам о сценарии, объёме нагрузки и требованиях комплаенса. Мы вернёмся с конкретной рекомендацией buy-vs-build, архитектурой и честной оценкой — как правило, в течение одного рабочего дня.
Что такое анализ эмоций в речи в реальном времени
Анализ эмоций в речи в реальном времени, или распознавание эмоций речи (speech emotion recognition, SER), — это пайплайн, который превращает живой поток с микрофона в один из двух выходов: дискретную метку эмоции (например, happy, sad, angry, neutral, fearful, disgusted, surprised) или пару непрерывных значений валентности и активации в так называемом «цирмплекс-пространстве». Современные системы обычно выдают результат каждые 250–500 мс и сглаживают его на окне 2–3 секунды, чтобы сигнал не дёргался на каждом вдохе.
Три вещи отличают SER реального времени от офлайн-аналитики записанных звонков. Первое — задержка: end-to-end ниже 500 мс — планка для живой подсказки оператору, ниже 300 мс — для плотного UX (подсказка, которая приходит на 2 секунды позже, превращается в шум). Второе — стриминг: модель обязана выдавать решение по неполному аудио, не дожидаясь, пока говорящий закончит фразу. Третье — устойчивость: реальные микрофоны добавляют шум, сжатие кодеков, дальнопольную реверберацию и перекрытие речи — условия, которых нет ни в одном бенчмарк-датасете.
SER — это не детектор лжи, не диагностика психического состояния и не замена интервью. Самая полезная формулировка для клиентов: «неутомимый второй слушатель, который помечает моменты, заслуживающие внимания человека». Мы будем возвращаться к этой формулировке по ходу статьи.
Состояние области в 2026 году
Честный ответ на вопрос «насколько хорош SER в 2026»: достаточно хорош, чтобы запускать продукт, если правильно очертить рамки, но недостаточно, чтобы автоматизировать решения о людях. На чистых академических бенчмарках (RAVDESS, IEMOCAP, CREMA-D, MELD) современные пайплайны на foundation-моделях дают 70–78 % F1 на 4–7 классах эмоций; на реальном аудио клиентских звонков те же модели проседают до 62–68 % F1 из-за шума, акцентов и расхождений в разметке. Hume AI публикует одни из самых высоких показателей точности среди коммерческих вендоров — 74 % на реальных данных, AWS Transcribe Call Analytics держится около 68 %. Любые цифры выше ~80 % в питче вендора почти всегда сняты на тщательно подобранной выборке — проверяйте на собственных записях до подписания контракта.
Между 2023 и 2026 годами изменились три вещи. Эмбеддинги foundation-моделей победили. Признаки из Wav2vec2, HuBERT и Whisper теперь обгоняют ручные MFCC и просодию на 8–15 пунктов на отложенных выборках и куда лучше обобщаются между языками. Задержка рухнула. Восемь с лишним продакшен-API сейчас выдают end-to-end метки эмоций менее чем за 500 мс, а Deepgram стабильно держит p95 ниже 300 мс. Мультимодальный фьюжн выходит на сцену. Объединение голоса, текстового сентимента из транскрипта и канала видеомикровыражений на приватных корпусах разгоняет точность выше 80 %. Именно такую архитектуру Фора Софт встроила в Meetric и в приложение новостных дайджестов.
Тянитесь к SER, когда: у вас не меньше 5 000 минут разговоров в месяц проходит через продукт, в котором одно фиксируемое изменение тона — разозлённый клиент, отстранённый студент, отчаявшийся пациент — стоит хотя бы 375 ₽ внимания человека. Ниже этого порога инженерные затраты редко окупаются.
Бенчмарки, по которым стоит спрашивать с вендора
Когда вендор говорит «наша модель — лучшая в классе», попросите его опубликовать три цифры на вашем домене: F1 (или Unweighted Average Recall, UAR, если классы несбалансированы), p95 по задержке и калибровку уверенности. Таблица ниже — срез 2026 года по тому, где ведущие модели располагаются на часто цитируемых бенчмарках. Воспринимайте её как проверку на разумность, а не как турнирную таблицу: условия отличаются, и ваше аудио даст другие цифры.
| Модель / подход | Датасет | F1 | UAR | Задержка | Комментарии |
|---|---|---|---|---|---|
| HuBERT-Large, дообученная | RAVDESS (чистый) | 78 % | 76 % | ~45 мс (T4) | Лучшая точность на чистых данных; самый большой GPU-footprint. |
| wav2vec2 + LSTM | IEMOCAP → реальные звонки | 65 % | 62 % | ~120 мс | Прочный внутридоменный baseline; требует дообучения. |
| openSMILE eGeMAPS + SVM | RAVDESS | 66 % | 64 % | <10 мс (CPU) | Маленькая, объяснимая, идеальна для edge-устройств. |
| AWS Transcribe Call Analytics | Реальное аудио контакт-центров | ~68 % | n/a | 300–500 мс | Подходит под HIPAA, 4 эмоции, 0,32 ₽/мин. |
| Hume AI Expression | Смешанная in-the-wild речь | ~74 % | n/a | 200–350 мс | 7 категорий + valence/arousal, ~3,75 ₽/мин. |
| Мультимодальный (аудио + текст + видео) | Приватные корпуса | 80 %+ | n/a | 350–600 мс | Требует синхронизированных аудио, видео и транскрипта. |
Эталонный пайплайн реального времени, который можно собрать уже сегодня
Каждая SER-система, которую мы доводили до прода, и каждая правдоподобная архитектура вендора, которую мы рассматривали, укладывается в одни и те же шесть стадий. Диаграмма ниже — та архитектура, которую мы рекомендуем как точку старта. Суммарный бюджет задержки получается порядка 200–500 мс end-to-end на современном GPU-инстансе — уверенно внутри полосы «ощущается живым».
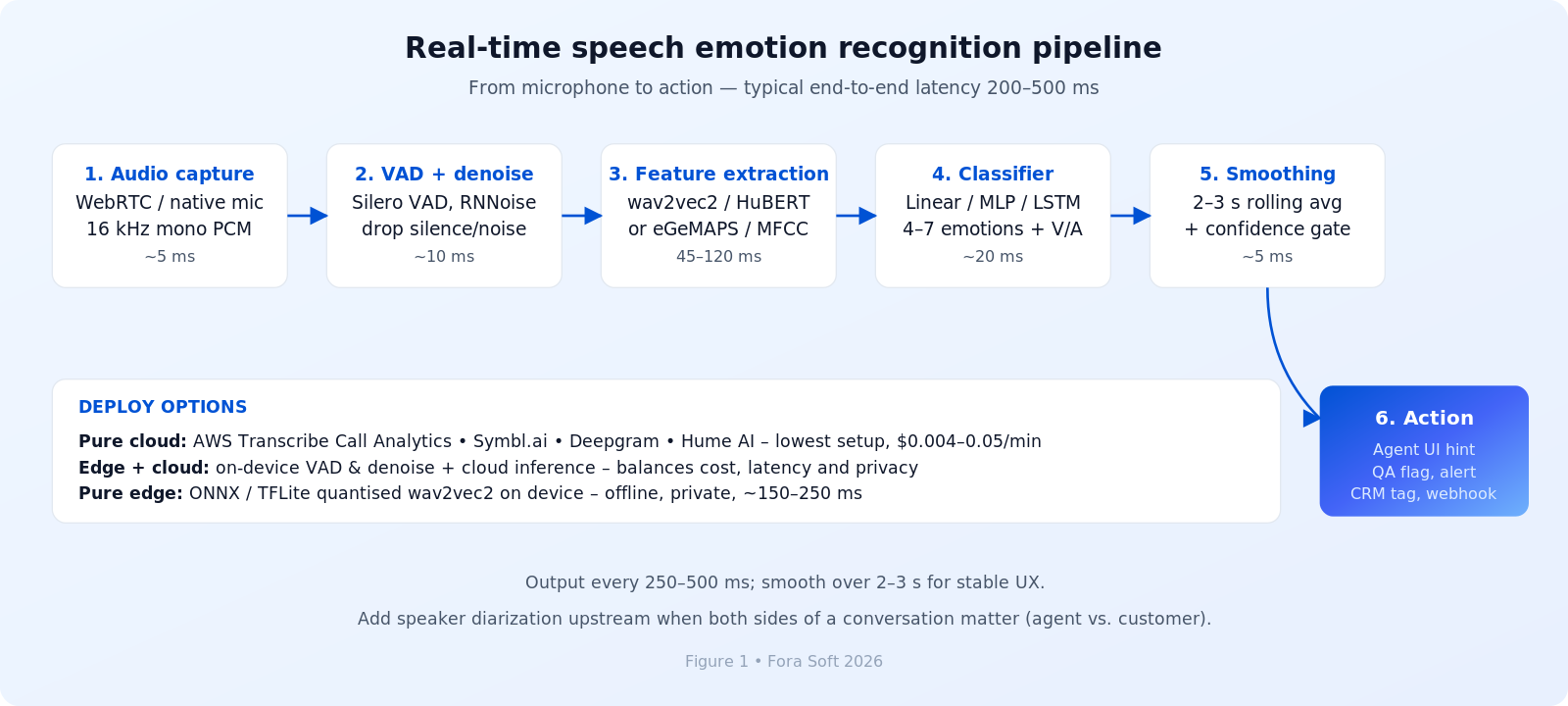
Рисунок 1. End-to-end пайплайн SER реального времени с тремя вариантами развёртывания.
1. Захват, VAD и шумоподавление
Моно-PCM-поток 16 кГц из WebRTC, нативного микрофонного стека или SIP-транка идёт в Voice Activity Detection (Silero VAD поставляется в виде ONNX-модели на 50 КБ и работает в одном потоке CPU) и опциональное шумоподавление (RNNoise, Krisp). Удаление пауз и нерчи на входе срезает дальнейший счёт за вычисления на 40–60 % и защищает классификатор от ложных меток на фоновой музыке.
2. Извлечение признаков
Два пути. Современный прогоняет аудио через foundation-модель (wav2vec2-base, HuBERT-Large или XLS-R для мультиязычности) и использует контекстные эмбеддинги как вектор признаков. Классический считает набор eGeMAPS через openSMILE — 88 акустических дескрипторов: высота тона, jitter, shimmer, форманты, энергия. Foundation-модели выигрывают по точности на 8–15 пунктов; классика выигрывает по задержке, объяснимости и размеру для edge-устройств.
3. Классификатор и сглаживание
Маленькая голова — linear, MLP или LSTM — преобразует эмбеддинг либо в категориальные эмоции (4–7 классов), либо в два непрерывных значения valence/arousal. Сглаживайте всегда: берите скользящее среднее за последние 2–3 секунды, ставьте порог уверенности (мы обычно отбрасываем всё ниже 0,55) и запускайте действия только на изменениях метки, которые сохраняются на двух подряд окнах. Без сглаживания интерфейс будет мерцать.
Тянитесь к признакам foundation-модели, когда: вы можете развернуть GPU-инстанс (или принять managed cloud API) и точность — главный KPI. Тянитесь к openSMILE + SVM, когда вы обязаны развернуть модель на устройстве, на массовых CPU или там, где каждое предсказание должно быть аудируемым простыми словами.
Пять коммерческих API, которые стоит включить в шортлист
Если ограничение — «запуститься за 6–10 недель», вы покупаете API. На шортлисте 2026 года доминируют пять вендоров. Цены ниже — прайс за обработанную минуту аудио; контракты на объём срезают 30–60 %.
1. AWS Transcribe Call Analytics (0,32 ₽/мин). Лучше всего, если вы уже живёте в AWS, нужен HIPAA-совместимый BAA из коробки и допустима задержка 300–500 мс. Только четыре эмоции (positive, negative, neutral, mixed) плюс детектирование проблем и автоматическое подведение итогов разговора. Самый дешёвый серьёзный вариант для контакт-центров в Северной Америке.
2. Hume AI Expression Measurement (~3,75 ₽/мин). Лидер по точности на in-the-wild данных, 7+ категорий эмоций и непрерывный выход valence/arousal. Сделан специально под эмпатичные AI-продукты и клинические исследования; правильный выбор, когда вы платите за внимание человека дальше по пайплайну и ложные пропуски обходятся дорого.
3. Deepgram (~0,93 ₽/мин). Самый низкий p95 по задержке в индустрии (часто <280 мс) и плотно сцеплен с ASR Deepgram — на одном стриминговом эндпоинте вы получаете транскрипт, сентимент и эмоцию. Эргономичный выбор для UX живой подсказки и инструментов для встреч.
4. Symbl.ai (~1,2 ₽/мин). Силён в аналитике всего разговора — темы, action item’ы, трекеры — и аккуратно интегрируется с WebRTC-стеками. Подходит продуктам обучения продавцов и meeting intelligence, где эмоция — один из многих сигналов.
5. AssemblyAI Speaker Sentiment (~0,75 ₽/мин). Использует сентимент на уровне реплики как прокси для эмоции. Дешевле специализированных вендоров, но грубее; полезен там, где хватает «positive vs. negative».
| Вендор | Точность в реале | Задержка | Цена / мин | Эмоции | Лучший сценарий |
|---|---|---|---|---|---|
| AWS Transcribe CA | ~68 % | 300–500 мс | 0,32 ₽ | 4 | HIPAA-контакт-центры |
| Hume AI | ~74 % | 200–350 мс | ~3,75 ₽ | 7 + V/A | Ментальное здоровье, эмпатия |
| Deepgram | ~66 % | 150–280 мс | ~0,93 ₽ | 5 | Живая подсказка, встречи |
| Symbl.ai | ~71 % | 250–400 мс | ~1,2 ₽ | 6 + V/A | Conversation intelligence |
| AssemblyAI | ~65 % | 400–600 мс | ~0,75 ₽ | 3 (сентимент) | Аналитика, чувствительная к цене |
Три open-source пути, если вы решили строить сами
1. wav2vec2 + LSTM-голова. Стартуйте с facebook/wav2vec2-large-960h на Hugging Face, дообучите на IEMOCAP плюс собственных размеченных данных. Ожидайте 70–74 % F1 после 30–50 GPU-часов и 45–80 мс инференса на Tesla T4. Лучший компромисс точность/усилия для in-house сборки.
2. HuBERT-Large или XLS-R для мультиязычности. Тот же рецепт, лучшая обобщаемость по языкам и code-switched разговорам. Обязательный выбор, если вы обслуживаете смешанный трафик (Spanglish-контакт-центры, индийский английский).
3. openSMILE eGeMAPS + SVM. Лёгкий, объяснимый путь. 64–68 % F1, но инференс менее 10 мс на одном ядре CPU, размер модели в одноразрядных мегабайтах. Правильный выбор для встраиваемых целей — автомобильный infotainment, слуховые аппараты, киоски.
Тянитесь к open-source сборке, когда: у вас есть размеченный внутридоменный корпус хотя бы из 5 000 высказываний, бюджет на 30–100 GPU-часов дообучения и чёткая причина — data residency, кастомная таксономия, IP — по которой managed API не подходит.
from transformers import Wav2Vec2Processor, Wav2Vec2ForSequenceClassification
import torch
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-large-960h")
model = Wav2Vec2ForSequenceClassification.from_pretrained(
"your-org/wav2vec2-emotion-finetuned"
)
inputs = processor(audio_chunk, sampling_rate=16000, return_tensors="pt").input_values
with torch.no_grad():
logits = model(inputs).logits
emotion_id = int(torch.argmax(logits, dim=-1))
confidence = float(torch.softmax(logits, dim=-1).max())
Строить или покупать SER для вашего продукта?
Мы доводили до прода обе архитектуры — managed API и in-house пайплайны на wav2vec2 — в телемедицине, EdTech и продуктах живого видео. Дайте нам посчитать математику на ваших цифрах.
Пять сценариев, где SER реально окупается
1. Автоматизация QA в контакт-центре. Разметка эмоций в реальном времени на каждом звонке выявляет риск эскалации до того, как тот дойдёт до супервизора. Типичный эффект у наших клиентов: снижение времени на ревью QA на 40–45 %, рост CSAT на 4–8 пунктов после того, как операторы видят сигнал в собственном интерфейсе. ROI выходит в плюс за 9–12 месяцев при цене API 0,32 ₽/мин.
2. Телемедицина и триаж в ментальном здоровье. Терапевтические сессии автоматически размечаются кривой эмоционального хода; устойчивый гнев или отчаяние помечаются как риск для дежурного психиатра. Результаты опубликованных клинических пилотов: примерно на 22 % более раннее вмешательство, снижение количества кризисных звонков примерно на 18 %. Hume AI — обычный выбор; добавьте к нему HIPAA-grade лог аудита и обязательное ревью человеком. Хорошо ложится на паттерны, которые мы разбирали в нашем гиде по функциям телемедицинских платформ.
3. Оценка вовлечённости в EdTech. Платформы живого тьюторинга детектируют фрустрацию в голосе ученика и запускают подсказку, переформулировку или передачу преподавателю-человеку. Исследования адаптивной обратной связи фиксируют рост completion rate на задачах на 8–12 пунктов. On-device TinyML оставляет аудио вне сети — полезный аргумент для школьных IT-команд.
4. Коучинг продаж в живом видео. Шаблон Meetric: соединяете аудиосентимент с балансом времени речи, вниманием и реакциями, чтобы оценивать вовлечённость в реальном времени, и пушите подсказку коучинга в боковую панель продавца («вы говорите уже 90 секунд — задайте вопрос»). Платформа привлекла 21 млн SEK и сейчас используется отделами продаж поверх Zoom, Google Meet и Teams.
5. Мониторинг безопасности водителя. Микрофон в салоне следит за устойчивым гневом, дистрессом или сонливостью и предлагает сделать перерыв. Здесь обязательно чистый edge-деплой — и из соображений приватности, и из-за отсутствия стабильной связи; квантованный wav2vec2 или openSMILE-пайплайн делает работу за 50 мс на автомобильном кремнии.
К SER в продуктах ментального здоровья подходите осторожно: всегда сочетайте модель с ревью человеком, отказывайтесь от предсказания ниже 0,6 уверенности, никогда не показывайте одну метку как клинический «вердикт» и получайте явное BAA/DPIA-покрытие до пилота на реальных пациентских звонках.
Реалистичная модель затрат: во сколько обойдётся SER в 2026 году
Для типичной интеграции SaaS или контакт-центра мы закладываем три статьи: инженерия интеграции, регулярная стоимость инференса и накладные расходы на комплаенс. Цифры ниже взяты из реальных проектов Фора Софт и предполагают наш agent engineering workflow, который сократил типичные сроки на 25–35 % по сравнению с теми же объёмами два года назад. Это отправные точки, а не коммерческое предложение: у каждого проекта свой контекст.
| Сценарий | Подход | Разовая инженерия | Инференс в мес. | Срок запуска |
|---|---|---|---|---|
| 100 тыс. мин/мес, 1 поверхность | Managed API + интеграция | ~1,1–1,8 млн ₽ | ~32–120 тыс. ₽ | 5–8 недель |
| 500 тыс. мин/мес, мультиязычность, ЕС | Гибрид: cloud API + EU residency | ~2,2–4,1 млн ₽ | ~165–600 тыс. ₽ | 9–14 недель |
| 1 млн+ мин/мес, кастомная таксономия | Дообученный wav2vec2 in-house | ~4,5–9 млн ₽ | ~112–300 тыс. ₽ (GPU) | 14–22 недели |
| Чистый edge, на устройстве | openSMILE / квантованный wav2vec2 | ~3,3–6,7 млн ₽ | ~0 ₽ дополнительно | 12–18 недель |
Мини-кейс: анализ эмоций в приложении новостных дайджестов
Клиент из медиатеха пришёл к нам с гипотезой: люди будут больше вовлекаться в ежедневное приложение новостей, если оно будет давать им еженедельный «отчёт настроения» о том, как заголовки на них повлияли. Подвох в том, что это должно работать без принуждения пользователя писать дневник — через пару недель журналинг бросают.
Фора Софт собрала двухканальный пайплайн анализа эмоций. Пользователь записывает короткую голосовую заметку прямо внутри ленты; фронтенд одновременно захватывает аудио и кадры с фронтальной камеры. Аудио идёт в классификатор на базе wav2vec2 (happy/neutral/upset плюс arousal), кадры лица — в распознаватель выражений на CNN, и два потока сливаются взвешенным по уверенности средним. Недельный дайджест визуализирует тренд — не как клинический диагноз, а как артефакт журналинга, который пользователь интерпретирует сам.
Два инженерных решения, которые имели значение. Первое: мы прогоняли инференс эмоций на устройстве для аудио короче 8 секунд и уходили в облако только для более длинных клипов — история про приватность, которую можно рассказать пользователю на экране установки. Второе: мы явно научили модель отказываться отвечать: всё ниже 0,55 уверенности отрисовывалось как «смешанные сигналы», а не как ошибочная метка. Через три месяца после запуска средняя недельная retention у пользователей, которые сделали хотя бы одну голосовую заметку, была примерно в 2× выше, чем у когорты, проигнорировавшей фичу. Хотите такую же оценку, где SER попадёт в ваш продукт? Позвоните нам или напишите — обсудим за 30 минут.
Фреймворк решения: подберите правильный путь SER за пять вопросов
В1. Нужна ли вам задержка ниже 300 мс? Если да, вы покупаете Deepgram или гоните собственную edge-модель. Построить cloud-пайплайн с задержкой ниже 300 мс с нуля — 4–6 месяцев.
В2. Хватит ли вам 4 стандартных эмоций? Если да, берите AWS Transcribe Call Analytics. Если нужны 7+ категорий или непрерывный valence/arousal — Hume AI или дообученная wav2vec2.
В3. Вас ограничивают HIPAA, GDPR или EU AI Act? HIPAA → AWS TCA с BAA. GDPR → либо вендор с резиденцией в ЕС, либо self-hosted на Hetzner/OVH во Франкфурте. EU AI Act → в ЕС не разворачивайте распознавание эмоций на рабочем месте или в образовании в принципе; переключайтесь на сентимент.
В4. Ваши обучающие данные уникальны? Если да — у вас есть размеченный внутридоменный корпус — стройте. Прирост точности от дообучения на реальном аудио клиентов стабильно бьёт коммерческий API на 5–10 пунктов именно на вашем трафике.
В5. Каков ваш годовой объём в минутах? Меньше 1 млн минут в год — API дешевле от и до. Больше 5 млн минут в год — in-house unit-экономика (0,07–0,15 ₽/мин на собственных GPU) начинает выигрывать. Средняя полоса — место, где блестят гибридные архитектуры.
Пять ловушек внедрения, которые мы видим каждый квартал
1. Фоновый шум сжигает точность в поле. Модель, которая даёт 75 % на RAVDESS, на шумных офисных звонках часто проседает до 60 %. Фильтруйте агрессивно: спектральное gating ниже −40 дБ, RNNoise на входе, в классификатор — только окна, в которых детектор подтвердил речь.
2. Code-switching уничтожает одноязычные модели. Модель, обученная на английском, ошибается на испано-английских смешанных звонках примерно на 15 пунктов. Решение — мультиязычные foundation-модели (XLS-R, многоязычный HuBERT) плюс калибровка уверенности по каждому языку.
3. Культурное смещение — реальная и неловкая штука. Модели, обученные на IEMOCAP — западных актёрах, — неверно читают японскую сдержанность и южноазиатские интонации. Всегда замеряйте на собственной аудитории и калибруйте порог уверенности регионально.
4. Расхождение разметчиков ограничивает потолок точности. Согласованность между разметчиками на реальных разговорах — 78–82 %; это и есть эффективный потолок точности. Используйте альфу Криппендорфа > 0,65, чтобы отфильтровывать обучающие данные, и сглаживайте лейблы в лоссе до 0,85 вместо 1,0.
5. Дрейф модели прокрадывается незаметно. Распределение эмоций в звонках клиентов меняется сезонно и при ротации операторов. Следите за скользящим 7-дневным средним уверенности; если оно проседает больше чем на 10 % — переобучайте. На продакшен-деплоях мы по умолчанию ставим ежемесячное переобучение.
KPI: что действительно стоит измерять
KPI качества. Macro-F1 на отложенном тесте (цель > 70 % на чистых данных, > 65 % на реале); отдельно точность по классу «anger» (цель > 75 % — у него самый высокий бизнес-эффект и самая высокая цена ложного пропуска); калибровка уверенности (Brier score < 0,15).
Бизнес-KPI. Экономия времени QA (цель 40 %+ к baseline); прирост CSAT в когорте с emotion-коучингом (цель +4 до +8 пунктов за 90 дней); более раннее вмешательство в клинических кейсах (цель −30 дней к предзапускной норме); прирост вовлечённости/completion rate в EdTech (цель +8 %).
KPI надёжности. p95 по задержке инференса (цель < 300 мс для live, < 1 с для аналитики); uptime API или модели (цель 99,9 % с задокументированным fallback); цена за обработанную минуту (заложите бюджет — мы обычно якорим на 0,15–0,75 ₽ в зависимости от уровня точности); доля ложных пропусков по классу «anger» (alert при > 8 %).
Когда SER лучше не внедрять
Три ситуации, где мы советуем клиентам взять паузу. Если вы не можете назвать конкретное действие человека, стоящее за сигналом — что именно оператор, супервизор или интерфейс продукта делают, когда модель сказала «angry»? — у вас пока нет сценария, у вас фича в поисках сценария. Если вы работаете внутри ЕС в контекстах рабочего места или образования, статья 27 EU AI Act с февраля 2025 года прямо запрещает распознавание эмоций; переформулируйте задачу как бинарный сентимент или откажитесь от деплоя. Если ваш месячный объём ниже ~5 000 минут, операционные накладные (флоу согласия, лог аудита, мониторинг, переобучение) перекроют всё, что может дать SER, — вложите бюджет в более качественный QA-человеком сначала.
Есть ещё более тихий режим отказа: SER как замена нормальному продуктовому исследованию. Если пользователи в каждом звонке прямо говорят вам словами, что им не нравится, вам не нужна модель эмоций, чтобы это узнать — вам нужен tagging-флоу и продакт. SER — это мультипликатор для уже работающих процессов, а не инструмент дискавери.
Приватность и комплаенс: правила, которые реально кусаются
GDPR, статья 9. Голосовой анализ эмоций — это обработка биометрических данных особой категории. Нужно явное, гранулярное согласие (не похороненное в ToS), задокументированная оценка законного интереса и понятная политика хранения. Мы обычно удаляем сырое аудио в течение 30 дней и держим только эмбеддинги + метки 180–365 дней для аудита модели.
HIPAA. Анализ эмоций на терапевтических или телемедицинских звонках является частью медицинской записи. Нужен Business Associate Agreement с каждым вендором в цепочке, шифрование в транзите и при хранении, лог аудита (CloudTrail или эквивалент) и протестированный плейбук реагирования на инциденты. AWS TCA — самый простой путь к BAA; добавляет к счёту AWS примерно 25 % по сравнению с не-HIPAA тиром.
EU AI Act. Статья 27 запрещает системы распознавания эмоций на рабочих местах и в образовательных учреждениях. Применение началось в феврале 2025 года, с ограниченными исключениями по медицине и безопасности. Прагматичный плейбук для продуктов, работающих на ЕС: убирайте метку «emotion» вообще, классифицируйте как бинарный сентимент или аналитику времени речи, регистрируйтесь как high-risk AI system, если оказываетесь близко к черте, и проводите Data Protection Impact Assessment.
Где мультимодальный подход превосходит только аудио
SER только по аудио упирается в потолок около 78 % F1 на чистых данных; объединение аудио с текстовым сентиментом из транскрипта и каналом видеомикровыражений пробивает 80 %. Прирост даёт устранение неоднозначности: ровно произнесённое «great» звучит нейтрально по аудио, но читается саркастичным, если слить его с транскриптом и кадром нахмуренного лица. Мы стабильно видим этот эффект в наших гибридных деплоях анализа эмоций аудио и видео.
Мультимодальность не бесплатна. Синхронизация сложна (аудио и видеокадры разъезжаются, нужна единая временная линия), полоса удваивается, и приватность-ревью занимает в 2× больше времени. Тянитесь к мультимодальности, когда цена ошибочной метки высока — триаж в ментальном здоровье, коучинг продаж на сделках с шестизначным средним чеком, регулируемые тренинговые среды — и оставайтесь на чистом аудио, когда цена одного решения невелика.
Как встроить SER в WebRTC-стек
Для продуктов живого видео стандартный паттерн такой: WebRTC SFU форкает аудиопоток на серверный воркер, воркер прогоняет VAD + инференс эмоций и шлёт события обратно через WebSocket или data channel, фронтенд отрисовывает деликатные элементы UI (изменение цвета плитки говорящего, инлайн-подсказка коучинга, alert менеджеру). Бюджет задержки end-to-end — 400–700 мс; больше — и обратная связь в UI начинает ощущаться запоздалой.
Два решения, которые нужно принять рано. Запускайте воркер в том же регионе, что и SFU, чтобы избежать трансконтинентальных round-trip’ов. И продумайте UX согласия до того, как напишете код — пользователь должен в момент анализа сессии видеть, что она анализируется, иметь явный opt-out и возможность скачать свои данные позже. Этот более широкий контекст мы разбирали в обзоре систем анализа эмоций по аудио на базе AI.
Тренды 2026 года, за которыми стоит следить
Мультимодальность становится дефолтом. Слияние аудио + текста + лёгкого видео пробивает порог 80 % F1 и сдвигает одноканальный SER в сторону коммодити.
Edge-готовые модели эмоций. Квантованные варианты wav2vec2 и DistilHuBERT весом 10–50 МБ уже работают на телефонах и SoC автомобильного infotainment с инференсом 50–150 мс. Privacy-first продукты будут уходить именно сюда.
Непрерывный valence/arousal обыгрывает дискретные метки. Клиенты хотят видеть тренд, а не одну метку. Цирмплекс-выход Hume и похожие API на непрерывном пространстве вытеснят жёсткие «7 эмоций» в дашбордах.
Синтетические обучающие данные. Модели TTS + клонирования голоса генерируют разнообразную эмоциональную речь в масштабе, ускоряя дообучение на 25–40 %. Внимательно смотрите на лицензии.
FAQ
Насколько точен анализ эмоций в речи в реальном времени в 2026 году?
Лучшие в классе системы дают 70–78 % F1 на чистых академических бенчмарках (RAVDESS, IEMOCAP, CREMA-D) и 62–68 % на реальном аудио клиентских звонков. Мультимодальные пайплайны, объединяющие аудио, текст и видео, могут пробить 80 % на приватных корпусах. Вендорские цифры «до 98 %» почти всегда получены на тщательно подобранной выборке — проверяйте на собственных записях до подписания контракта.
Какие эмоции аудиоанализ реально умеет распознавать?
Большинство продакшен-систем выдают 4–7 категориальных эмоций — happy, sad, angry, neutral, опционально fearful, disgusted и surprised — или два непрерывных значения valence (позитив/негатив) и arousal (спокойствие/возбуждение). Hume AI уникально поддерживает более богатое пространство из 28 категорий «expression». Мы советуем держать UI на 3–5 категориях независимо от того, что выдаёт модель, потому что пользователи просто не способны интерпретировать 28 корзин.
Окупается ли распознавание эмоций речи в реальном времени по деньгам?
На нагрузках выше ~5 000 минут в месяц обычно да, особенно в контакт-центрах (рост CSAT, экономия времени QA) и клиническом триаже (более раннее вмешательство). Ниже этого порога операционные накладные — согласие, аудит, мониторинг — съедают весь прирост. Цены в 2026: 0,32 ₽/мин в AWS TCA, ~3,75 ₽/мин в Hume AI; объёмные контракты срезают 30–60 %.
Законен ли анализ голосовых эмоций по GDPR и EU AI Act?
Это биометрические данные особой категории по статье 9 GDPR — разрешено при явном согласии и задокументированной цели. По EU AI Act распознавание эмоций запрещено на рабочем месте и в образовании с февраля 2025 года (статья 27), с ограниченными исключениями по безопасности и медицине. Вне этих контекстов разрешено, но классифицируется как high-risk; ожидайте регистрацию системы и оценку Data Protection Impact Assessment.
Как интегрировать SER в существующий WebRTC- или телефонный стек?
Форкайте аудио на SFU или медиашлюзе, пушите его в воркер (контейнеризованный, в том же регионе), который гонит VAD плюс инференс эмоций, и публикуйте события обратно в приложение через WebSocket, gRPC или ваш data channel. Для SIP/контакт-центровых стеков тот же паттерн работает через media-recording API. Целевая задержка end-to-end: 400–700 мс.
Можно ли запускать SER на устройстве для приватности или офлайна?
Да. Квантованные варианты wav2vec2 или DistilHuBERT компилируются в ONNX или TensorFlow Lite размером 10–50 МБ и работают за 50–150 мс на современных телефонах. openSMILE + маленький SVM ещё меньше (одноразрядные МБ) при задержке < 10 мс на одном ядре CPU и обычно выбирается для автомобильных и встраиваемых целей. Точность проседает на 4–8 пунктов по сравнению с облачной моделью, зато история про приватность становится сильно проще.
Сколько обычно занимает SER-интеграция у Фора Софт?
Интеграция через API в существующий продукт обычно занимает 5–8 недель: дискавери, флоу согласия, интеграция пайплайна, дашборды, оценка. Дообученная in-house модель с EU residency и HIPAA-контролями — 14–22 недели. Наш agent engineering workflow срезал оба срока примерно на 25–35 % относительно baseline 2024 года.
На каком датасете оценивать SER до запуска?
Начните с публичного бенчмарка для проверки на разумность — RAVDESS для чистой речи, IEMOCAP для парных диалогов, CREMA-D для этнического разнообразия, MELD для спонтанных данных из ТВ-шоу, — затем соберите 1 000+ высказываний тестовой выборки из собственного продакшен-аудио, с минимум тремя разметчиками на клип и альфой Криппендорфа > 0,65. Для go/no-go решения значение имеет только ваш собственный датасет.
Что почитать дальше
Архитектура
Сборка системы анализа эмоций по аудио с использованием AI
Углублённый разбор пайплайна и выбора компонентов в продакшен-системах SER.
Мультимодальность
Объединение анализа эмоций по аудио и видео
Почему мультимодальный фьюжн пробивает потолок 80 % F1, недоступный только аудио.
Живое видео
Распознавание эмоций с помощью AI внутри видеоконференций
Как сигналы эмоций в реальном времени перестраивают коучинг, вовлечённость и UX wellness на встречах.
Вендоры
Топ ПО для AI-распознавания речи
Гид покупателя по ASR-движкам, которые стоят выше любого пайплайна SER.
Модели
Машинное обучение для анализа эмоций по видео
Семейства моделей, которые делают современное распознавание выражений лица рабочим от и до.
Готовы добавить анализ эмоций в речи в реальном времени в ваш продукт?
Анализ эмоций в речи в реальном времени нужен тогда, когда вы можете назвать конкретное действие человека за каждой меткой, когда объём ваших разговоров достаточно велик, чтобы автоматизация окупилась, и когда вы честны с собой по поводу GDPR, HIPAA и EU AI Act. Берите managed API, чтобы запуститься за недели; стройте дообученный in-house пайплайн только выше ~1 млн минут в год или когда ваши обучающие данные действительно уникальны. В любом случае закладывайте сглаживание, отказ от ответа и ревью человеком — модель иногда будет ошибаться, и это нормально, если ваш продукт умеет с этим справляться.
Фора Софт доводила анализ эмоций в речи в реальном времени до прода в AI-платформах продаж, телемедицинском триаже, новостных дайджестах, EdTech-тьюторинге и продуктах живого видео. Мы честно скажем, какой из этих паттернов подходит вашей ситуации — включая ответ «пока нет».
Давайте обсудим ваш проект по анализу эмоций в реальном времени
За 30-минутный разговор мы пройдёмся по вашему сценарию, объёму, бюджету задержки и требованиям комплаенса. Вы уйдёте с конкретной рекомендацией buy-vs-build и прозрачной оценкой.